




文章目录
- Docker
- Gateway
- Sentinel
- Seata(分布式事务)
- RabbitMQ
- AOP代理失效的情况
Docker
一、基础命令
1. 启动/停止Docker服务
# 启动Docker服务(Linux)
sudo systemctl start docker
# 停止Docker服务
sudo systemctl stop docker
# 重启Docker服务
sudo systemctl restart docker
# 设置开机自启
sudo systemctl enable docker
2. 查看Docker信息
# 查看Docker版本
docker version
# 查看Docker系统详细信息(存储、网络、资源等)
docker info
二、镜像操作
1. 拉取镜像
# 从Docker Hub拉取镜像(默认latest标签)
docker pull 镜像名称[:标签]
# 示例:拉取最新版Nginx镜像
docker pull nginx:latest
2. 列出本地镜像
# 查看所有本地镜像
docker images
# 仅显示镜像ID(-q)
docker images -q
# 查看所有镜像(含历史层)
docker images -a
3. 删除镜像
# 删除指定镜像(需停止所有关联容器)
docker rmi 镜像ID/名称
# 强制删除镜像
docker rmi -f 镜像ID/名称
# 清理未使用的镜像
docker image prune -a
4. 构建镜像
# 使用Dockerfile构建镜像(当前目录)
docker build -t 镜像名称[:标签] .
# 示例:构建名为app:1.0的镜像
docker build -t app:1.0 .
5. 推送镜像
# 登录Docker Hub
docker login
# 推送镜像到仓库
docker push 镜像名称[:标签]
三、容器操作
1. 创建并启动容器
# 后台运行容器并映射端口
docker run -d -p 宿主机端口:容器端口 镜像名称[:标签]
# 示例:运行Nginx容器并映射8080→80端口
docker run -d -p 8080:80 nginx:latest
# 指定名称启动容器
docker run --name 自定义名称 镜像名称
2. 列出容器
# 查看运行中的容器
docker ps
# 查看所有容器(含已停止)
docker ps -a
# 过滤显示(如仅显示名称)
docker ps --format "table {{.Names}}\t{{.Status}}"
3. 管理容器生命周期
# 停止容器
docker stop 容器ID/名称
# 强制停止容器
docker stop -t 0 容器ID/名称
# 启动已停止的容器
docker start 容器ID/名称
# 删除容器
docker rm 容器ID/名称
# 强制删除运行中容器
docker rm -f 容器ID/名称
4. 进入容器
# 交互式进入运行中的容器(新终端)
docker exec -it 容器ID/名称 /bin/bash
# 以root权限进入(若容器支持)
docker exec -u root -it 容器ID/名称 /bin/sh
5. 查看容器日志
# 实时查看容器日志
docker logs -f 容器ID/名称
# 查看指定行数日志
docker logs --tail 100 容器ID/名称
四、网络操作
1. 网络管理
# 创建自定义网络
docker network create 网络名称
# 列出所有网络
docker network ls
# 删除网络
docker network rm 网络名称
# 将容器连接到网络
docker network connect 网络名称 容器ID/名称
# 将容器从网络断开
docker network disconnect 网络名称 容器ID/名称
五、卷(Volume)操作
1. 数据卷管理
# 创建命名卷
docker volume create 卷名称
# 列出所有卷
docker volume ls
# 删除卷
docker volume rm 卷名称
# 清理未使用的卷
docker volume prune
六、系统维护
1. 清理资源
# 清理所有无用资源(停止容器、未使用的镜像、卷、网络)
docker system prune -a
# 清理停止的容器
docker container prune
# 清理未使用的网络
docker network prune
2. 查看磁盘占用
# 查看Docker资源占用
docker system df
七、其他实用命令
1. 容器操作
# 查看容器实时资源使用(CPU/内存)
docker stats 容器ID/名称
# 导出容器为tar文件
docker export 容器ID > 容器备份.tar
# 导入tar文件为镜像
docker import 容器备份.tar 新镜像名称
2. 帮助与文档
# 查看Docker命令帮助
docker --help
# 查看特定命令帮助(如docker run)
docker run --help
八、进阶命令示例
1. 端口映射与挂载卷
docker run -d \
-p 8080:80 \ # 端口映射
-v /宿主机路径:/容器路径 \ # 挂载卷
--name my_container \ # 自定义名称
nginx:latest
2. 资源限制
# 限制容器内存和CPU
docker run -d \
--memory="512m" \ # 最大512MB内存
--cpus="2" \ # 最多使用2个CPU核心
my_app
九、常见问题命令
1. 修复Docker进程占用过高
# 查看占用资源最多的容器
docker stats
2. 查找未命名的容器
docker ps -a | grep "容器ID前缀"
附录:快速参考表
| 操作类型 | 命令 |
|---|---|
| 基础服务 | systemctl start/stop/restart docker, docker info |
| 镜像操作 | docker pull, docker images, docker rmi, docker build, docker push |
| 容器操作 | docker run, docker ps, docker stop/start, docker exec |
| 网络管理 | docker network create, docker network ls, docker network rm |
| 清理资源 | docker system prune, docker image prune, docker volume prune |
Gateway
技术对比
路由转发配置
路由属性 RouterDefinition
网关实现登录校验(JWT)
问题:怎么实现?
自定义过滤器:编写登录校验的Pre前置处理逻辑。校验时机:网关将请求转发到微服务之前。校验结果后的用户信息放置Http请求头中。
问题:如何自定义过滤器?
实现GlobalFilter接口,重写filter方法,并注册到Spring中。
问题:校验逻辑?
1.获取请求中的请求头中的 登录凭证
2.校验凭证
3.return chain.filter(exchange) 并保证我们的过滤器在NettyRoutingFilter之前执行。
问题:NettyRoutingFilter的实现是什么样的?
实现了globalfilter接口,以及Ordered接口。
Ordered接口需要返回一个优先级,值越低优先级越高,范围是int范围。
问题:微服务之间的用户信息如何存储?
分析:基于OpenFegin发起,可以也可以放在请求头里。
问题:请求头放置什么类型的数据?
自定义GatewayFilter
问题:为什么用GatewayFilter?怎么实现
更灵活。区别于globalfilter,需要实现一个抽象网关过滤器工厂。过滤器工厂可以读取配置并帮助你创建过滤器对象。无参过滤器具体实现是定义匿名内部类的方法。自定义gatewayfilter 方法名必须是
前缀+GatewayFilterFactory,前缀未来就是yml中的 filter: -前缀
网关处理请求的流程(责任链)
1.路由映射器:默认HandlerMapping 路由处理,将匹配的路由存储上下文
2.请求处理器:默认FilteringWebHandler,加载多个过滤器(Pre前置处理),放入集合中形成过滤器链,然后依次执行这些过滤器。
3.路由过滤器:NettyRoutingFilter,将请求转发到微服务(URI属性)并将响应结果存入上下文(Post后置处理)。
网关过滤器
- GatewayFilter :针对特定路由 / yml中的过滤器属性或者配置到default-filter中,为所有未设置过滤器的路由生效。
- GlobalFilter:全局过滤器,声明生效。
两种过滤器的接口方法签名完全一致:
Mon<Void> filter(ServerWebExchange exchage,GatewayFilterChain chain);
参数:
- exchange:网关上下文
- chain : 可以调用下一个过滤器
返回值:
- Mono :定义回调函数(异步非阻塞编程)
使用场景:几乎不需要写Post
Sentinel
配置信息
1. 熔断降级配置
(1) 基础熔断配置(Java代码)
// 定义需保护的服务方法,绑定降级逻辑
@SentinelResource(
value = "orderService",
fallback = "orderFallback",
blockHandler = "orderBlockHandler"
)
public OrderDTO getOrder(String orderId) {
// 业务逻辑(如调用下游服务)
}
// 通用异常降级方法(fallback)
public OrderDTO orderFallback(String orderId, Throwable e) {
return new OrderDTO("DEFAULT_ORDER"); // 返回默认值或错误信息
}
// 熔断触发时的专用处理(blockHandler)
public OrderDTO orderBlockHandler(
String orderId,
BlockException ex
) {
return new OrderDTO("SERVICE_UNAVAILABLE"); // 服务不可用时的逻辑
}
说明:
fallback:捕获业务异常(如空指针、数据库异常)。blockHandler:捕获 Sentinel 规则触发的限流/降级(如QPS超过阈值)。- 双保险设计:两者结合可覆盖异常和流量控制场景(如知识库[1]中金融平台案例)。
(2) 动态规则配置(Nacos集成)
# application.yml(规则持久化配置)
spring:
cloud:
sentinel:
datasource:
ds1:
nacos:
server-addr: localhost:8848
dataId: ${spring.application.name}-sentinel-rules
groupId: DEFAULT_GROUP
rule-type: flow
// Nacos中配置的流控规则示例
[
{
"resource": "orderService",
"grade": 1, // QPS模式
"count": 1000, // 阈值1000 QPS
"strategy": 0, // 直接拒绝
"controlBehavior": 0 // 快速失败
},
{
"resource": "paymentService",
"grade": 2, // 异常比例模式
"count": 0.5, // 异常率超过50%触发降级
"strategy": 0
}
]
(3) 热点参数限流(秒杀场景)
// 方法定义(需标注@SentinelResource)
@SentinelResource(value = "hotProduct", blockHandler = "hotProductBlock")
public Product getHotProduct(@RequestParam("productId") String productId) {
// 业务逻辑(如查询热门商品)
}
// 初始化热点参数规则(白名单配置)
public void initHotRules() {
ParamFlowRule rule = new ParamFlowRule("hotProduct")
.setParamIdx(0) // 参数索引(从0开始)
.setCount(100) // 单参数阈值100 QPS
.setGrade(RuleConstant.FLOW_GRADE_QPS)
.setControlBehavior(RuleConstant.CONTROL_BEHAVIOR_DEFAULT);
// 添加例外项(如VIP用户不触发限流)
rule.getParamFlowItemList()
.add(new ParamFlowItem()
.setSpecificItem("VIP_1001") // 指定参数值
.setObjectType(ParamFlowItem setObjectTypeAnd));
ParamFlowRuleManager.loadRules(Collections.singletonList(rule));
}
2. 流控模式与效果
| 模式 | 说明 | 效果 |
|---|---|---|
| 直接 | 单纯基于资源名的限流。 | 快速失败、Warm Up(预热)、排队等待(需配置超时时间)。 |
| 关联 | 根据关联资源的流量控制非核心操作(如读写分离场景)。 | 例如:当核心写操作流量过高时,自动限流非核心读操作。 |
| 链路 | 根据调用链路区分限流对象(如内部调用与外部调用)。 | 例如:外部请求达到阈值时触发限流,内部调用不受影响。 |
(1) Warm Up(预热)配置
# 配置示例(application.yml)
spring.cloud.sentinel.flow.coldFactor=3 # 冷启动系数,默认3
逻辑:
- 初始QPS = 阈值 / coldFactor(如阈值12 → 起始QPS=4)。
- 逐步提升至阈值(如4秒内从4 QPS线性增长到12 QPS)。
(2) 排队等待
# 示例配置(需结合规则JSON)
controlBehavior: 2 # 排队等待模式
maxQueueingTimeMs: 2000 # 等待超时时间(毫秒)
效果:
- 达到阈值后,请求进入队列等待,超时未处理则拒绝。
微服务集成
1. Spring Cloud集成步骤
(1) 依赖添加
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
(2) Feign与Sentinel整合
# application.yml启用Feign与Sentinel的集成
feign:
sentinel:
enabled: true
(3) 全局异常处理
@SentinelResource(
fallback = "globalFallback",
blockHandler = "globalBlockHandler"
)
@RestControllerAdvice
public class GlobalExceptionHandler {
public OrderDTO globalFallback(
Throwable e,
BlockException ex
) {
// 全局降级逻辑
return new OrderDTO("GLOBAL_ERROR");
}
}
2. 最佳实践
- 服务雪崩防护:对核心服务配置熔断(如知识库[1]中金融平台提升37%成功率)。
- 监控与告警:通过Sentinel Dashboard实时监控指标(QPS、异常率、熔断状态)。
- 动态规则管理:结合Nacos或Apollo实现规则热更新,无需重启服务。
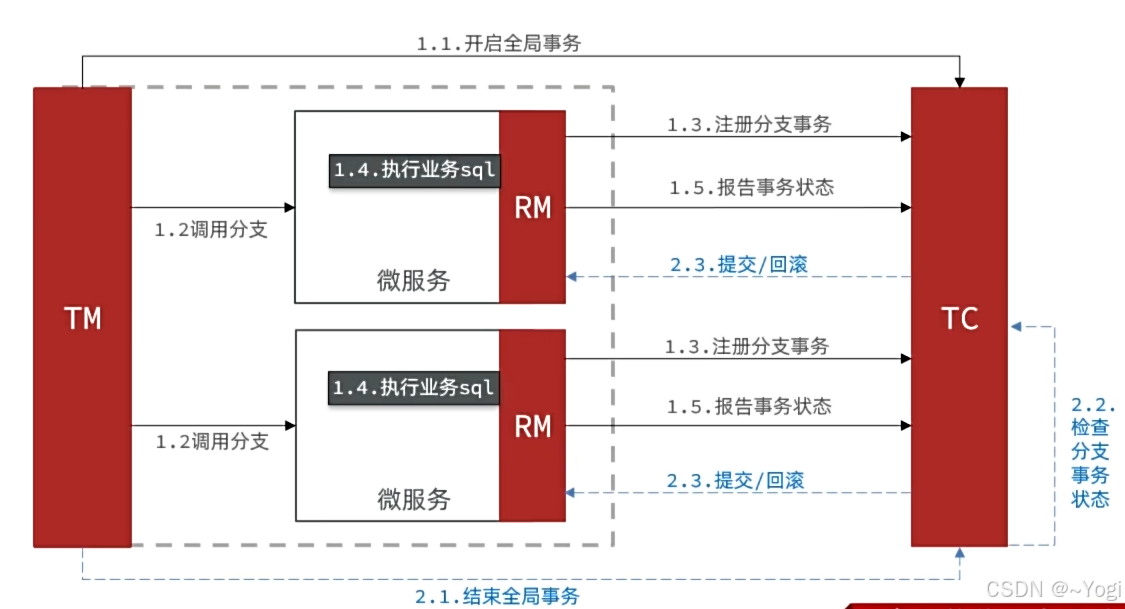
Seata(分布式事务)

XA模式
1. XA模式原理
-
角色:
- TM(事务管理器):协调全局事务(如Seata的TC)。
- RM(资源管理器):管理资源(如数据库)。
- AP(应用):发起事务请求。
-
流程:
- 准备阶段:AP向TM提交事务,TM通知各RM准备(锁资源)。
- 提交阶段:TM收集RM状态,若全部成功则提交,否则回滚。
-
特点:
- 强一致性:依赖数据库对XA协议的支持(如MySQL 8+)。
- 性能开销大:需两阶段提交,资源锁定时间长。
2. Seata XA模式配置
# seata.config
transaction.service.group.xa.DataSource.XADataSourceType = mysql
transaction.service.group.xa.DataSource.user = root
transaction.service.group.xa.DataSource.password = root
// 业务代码示例(需@GlobalTransactional注解)
@GlobalTransactional
public void saveOrder(OrderSaveParam param) {
// 跨服务操作(如扣减库存、生成订单)
// 异常时自动回滚
}
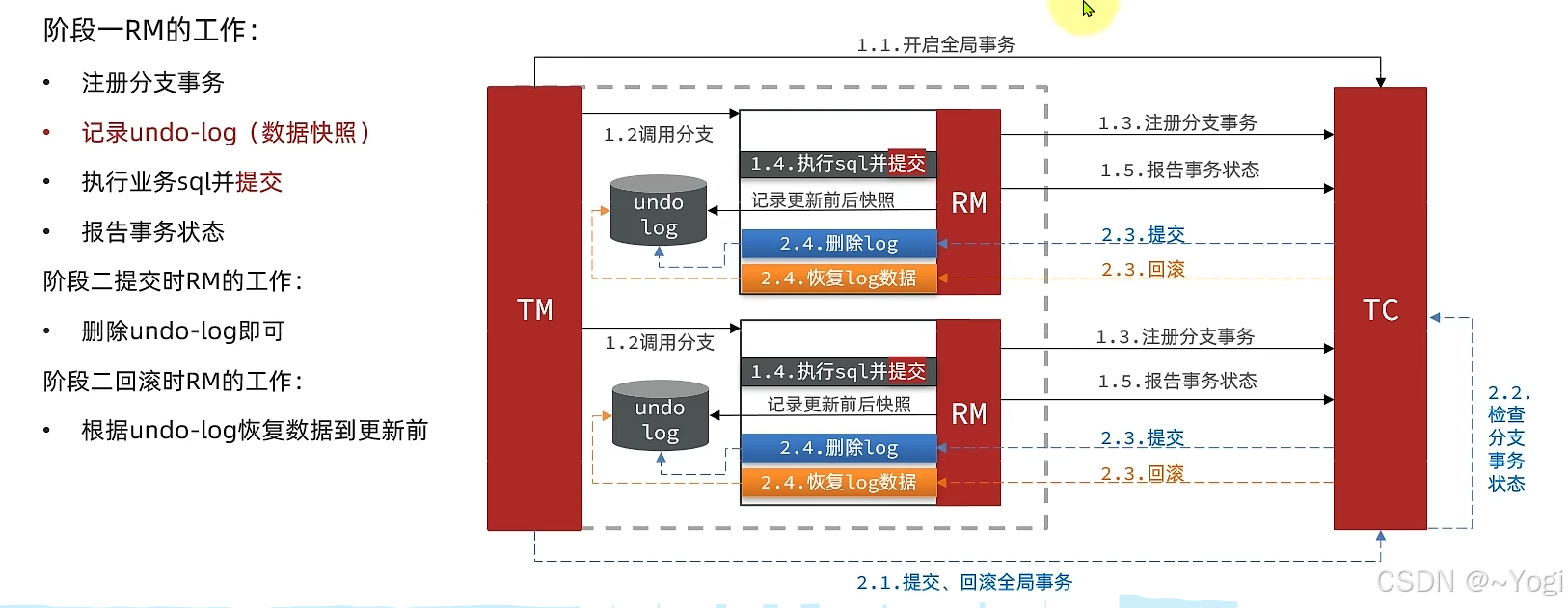
AT模式
1. AT模式原理
- 自动补偿机制:通过异步提交和快照对比实现最终一致性。
- 流程:
- 预写阶段:记录业务数据的前后快照。
- 提交阶段:直接提交业务数据,异步对比快照完成最终提交或回滚。
- 特点:
- 无侵入性:无需数据库支持XA协议。
- 性能较高:避免两阶段提交的锁竞争问题。
2. Seata AT模式配置
# seata.config
transaction.service.group.at.DataSource.driverClass = com.mysql.cj.jdbc.Driver
transaction.service.group.at.DataSource.url = jdbc:mysql://localhost:3306/test?useSSL=false
// 业务代码与XA模式相同,只需切换模式
@GlobalTransactional
public void saveOrder(OrderSaveParam param) {
// 同样实现跨服务操作
}
XA模式 vs AT模式对比
| 维度 | XA模式 | AT模式 |
|---|---|---|
| 一致性 | 强一致性(两阶段提交) | 最终一致性(异步补偿) |
| 性能 | 较低(锁资源时间长) | 较高(无锁设计) |
| 数据库依赖 | 需支持XA协议(如MySQL 8+) | 无需XA协议,支持主流数据库 |
| 适用场景 | 高一致性要求的金融场景 | 高并发、低延迟的电商、互联网场景 |
总结
- Sentinel:用于流量控制、熔断降级,保障单服务稳定性。
- Seata XA/AT模式:解决分布式事务问题,确保跨服务数据一致性。
- 组合方案:在微服务架构中,Sentinel可与Seata结合,既控制流量又保证事务。
如需进一步优化配置或具体场景实现,可参考知识库中的代码示例和最佳实践!
RabbitMQ
高性能异步通信组件
同步通讯:打视频,打电话(实时阻塞)
异步通讯:WX聊天(非阻塞)
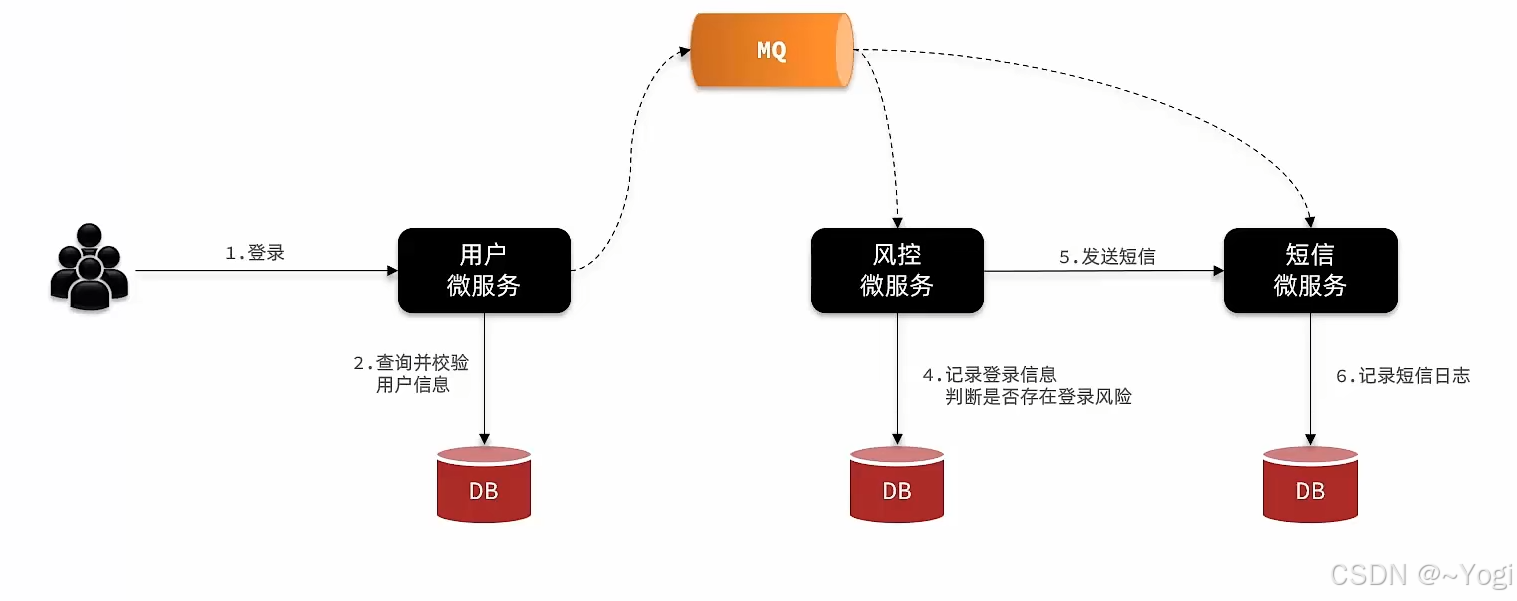
同步和异步
同步调用:需要等待调用的结果 (大概是核心业务)
异步调用:无需等待调用结果 / 回复 (大概是边缘业务)
问题:异步调用为什么需要消息代理?
消息的接收方可能在忙。需要驿站
MQ技术选型

数据隔离
知识总结
- 虚拟主机(Virtual Host):逻辑隔离不同业务的数据,每个虚拟主机独立管理队列、交换机和权限。
- 用户权限:通过用户与虚拟主机的绑定实现权限隔离,用户只能操作关联虚拟主机内的资源。
注意
- 默认虚拟主机:
/是默认虚拟主机,需谨慎使用。 - 权限配置:需显式授予用户对虚拟主机的
configure、write、read权限。
使用场景
- 多项目/团队共享同一 RabbitMQ 集群时,避免数据互相干扰。
- 敏感业务需独立资源管理(如金融、日志系统)。
常见八股文
- Q:如何实现 RabbitMQ 的数据隔离?
A:通过创建独立虚拟主机,并为不同用户分配对应虚拟主机的权限。 - Q:虚拟主机与用户权限的关系?
A:用户需绑定到虚拟主机,且需显式授予操作权限(如set_permissions)。
Spring AMQP
知识总结
- 核心组件:
RabbitTemplate(发送消息)、@RabbitListener(消费消息)、MessageConverter(消息转换)。 - 自动声明:通过配置自动创建队列、交换机及绑定关系。
细节
- 消息序列化:默认使用
JdkSerializationConverter,生产环境推荐Jackson2JsonMessageConverter,两者不兼容。 - 事务与确认:需显式配置
publisher-confirms或publisher-returns,并配置相应的回调函数。
使用场景
- Spring Boot 项目中快速集成 RabbitMQ,实现消息的发送与消费。
常见八股文
- Q:如何配置 JSON 消息转换器?
A:通过@Bean注册Jackson2JsonMessageConverter。 - Q:Spring AMQP 如何实现消息确认?
A:配置PublisherCallbackChannel并实现CorrelationData。
Work 模式(工作队列)
知识总结
- 特性:一个生产者、多个消费者,消息默认按轮询分发,确保消息被消费一次。
- 负载均衡:消费者按能力拉取消息(基于
prefetch-count配置)。
细节
- 公平调度:需设置合理
prefetch-count(默认 256),避免快慢消费者不均。 - 消息持久化:需同时设置队列持久化(
durable)和消息持久化(persistent)。
使用场景
- 高并发任务处理(如订单创建、日志收集)。
常见八股文
- Q:Work 模式如何实现公平分发?
A:通过设置prefetch-count为 1,确保消费者处理完当前消息后才拉取新消息。 - Q:Work 模式与发布订阅的区别?
A:Work 模式消息被消费一次,发布订阅消息被所有消费者接收(FanOut交换机)。
MQ 消息转换器
知识总结
- 作用:将 Java 对象与字节流相互转换,支持 JSON、XML、序列化等格式。
- 核心类:
MessageConverter(如Jackson2JsonMessageConverter)。
细节
- 一致性:生产者与消费者需使用相同的转换器。
- 自定义转换:可通过继承
AbstractJavaTypeMapper处理复杂对象映射。 - Jackson序列化比JDK ObjectOutputStream的转换更小,而且可读性更高。
使用场景
- 发送复杂对象(如 Java Bean)时避免二进制序列化。
常见八股文
- Q:如何自定义消息转换器?
A:实现MessageConverter接口,覆盖toMessage和fromMessage方法。 - Q:为什么 JSON 转换器比默认序列化更好?
A:JSON 更易读、体积小,且支持跨语言解析。
发布订阅模式(Pub/Sub)
知识总结
- 特性:消息被广播到所有绑定的队列,每个消费者独立消费一份副本。
- 交换机类型:
fanout(无路由键)、topic、direct、headers。
细节
- 临时队列:消费者可声明
exclusive队列,断开后自动删除。 - 路由规则:
topic支持通配符(*匹配一个词,#匹配多个词)。
使用场景
- 实时通知(如系统告警、消息广播)。
常见八股文
- Q:如何实现精准匹配的 Pub/Sub?
A:使用direct交换机,通过路由键精确匹配队列。 - Q:fanout 与 topic 的区别?
A:fanout 不区分路由键,消息广播给所有绑定队列;topic 支持通配符路由。
消息堆积问题处理
知识总结
- 原因:生产速度 > 消费速度,或消费者故障。
- 解决方案:扩容消费者、优化消费逻辑、调整预取数、使用优先级队列。
细节
- 预取数(prefetch-count):过高可能导致内存溢出,过低影响吞吐。
- 死信队列:设置
max-length或ttl,将未及时消费的消息转存。
使用场景
- 高峰流量(如秒杀、促销活动)时的流量削峰。
常见八股文
- Q:如何快速缓解消息堆积?
A:扩容消费者、优化消费逻辑、调整预取数、启用死信队列。 - Q:消息堆积时如何保证消息不丢失?
A:确保消息持久化、消费者确认模式为manual/auto。
发送者重连
知识总结
- 机制:RabbitMQ 客户端通过
Retry机制自动重连。 - 配置参数:
connection-factory的recovery-interval、automatic-recovery-enabled
细节
- 重连间隔:默认 5 秒,需根据业务调整。
- 未确认消息:重连后需手动重发未确认的消息(如使用
PublisherCallbackChannel)。
使用场景
- 网络波动或服务重启时保持生产者稳定性。
常见八股文
- Q:如何配置 RabbitMQ 的重连策略?
A:通过CachingConnectionFactory设置setRetry和setRecoveryInterval。 - Q:重连时如何避免消息重复?
A:结合消息 ID 和数据库幂等处理。
发送者确认
知识总结
- Confirm 确认:确认消息到达交换机。
- Return 确认:确认消息未被路由到队列(需设置
mandatory)。
细节
- 异步确认:通过
ConfirmCallback处理大规模消息。 - 消息丢失场景:需结合持久化和持久化确认。
使用场景
- 需要保证消息到达交换机的场景(如订单通知)。
常见八股文
- Q:Confirm 与 Return 的区别?
A:Confirm 确认消息到达交换机,Return 确认消息未被路由到队列。 - Q:如何实现消息的可靠投递?
A:结合 Confirm、Return 和持久化,配合数据库记录状态。
MQ 持久化
知识总结
- 队列持久化:设置
durable = true。 - 消息持久化:设置
messageProperties.setDeliveryMode(PERSISTENT)。 - 磁盘写入:需配合
镜像队列或集群避免单点故障。
细节
- 持久化 ≠ 安全:需结合主从复制或集群保证高可用。
- 性能影响:持久化会降低吞吐量,需权衡可靠性与性能。
使用场景
- 重要业务消息(如支付、订单)需持久化。
常见八股文
- Q:如何实现消息的持久化?
A:队列设置durable,消息设置persistent,并启用磁盘写入。 - Q:持久化消息丢失的可能原因?
A:未配置持久化、磁盘故障、未启用主从复制。
LazyQueue(惰性队列)
知识总结
- 特性:消息先存储在磁盘,延迟加载到内存,适合冷数据存储。
- 配置:队列参数
x-queue-mode = lazy。 - 版本:3.12 版本后队列默认为惰性队列无法修改
细节
- 吞吐量下降:磁盘读取速度低于内存,适合低频消费场景。
- 内存占用:显著降低,适合存储大量不活跃消息。
- 并发量:能够处理的并发量是上升的。
使用场景
- 日志归档、历史数据存储。
常见八股文
- Q:LazyQueue 与普通队列的区别?
A:LazyQueue 消息存储磁盘,减少内存占用,但吞吐量低。 - Q:何时使用 LazyQueue?
A:消息需长期存储且消费频率低时。
消费者确认
知识总结
- 自动确认:
autoAck = true,消费立即确认。 - 手动确认:
autoAck = false,需显式调用basicAck。
细节
- 未确认消息:消费者崩溃时消息重新入队(需幂等处理)。
- 批量确认:通过
basicAck的multiple参数优化性能。
使用场景
- 需要确保消息被正确处理后再确认(如事务型操作)。
常见八股文
- Q:手动确认 vs 自动确认?
A:手动确认避免消息丢失,但需处理幂等;自动确认简单但可能丢失消息。 - Q:如何实现批量确认?
A:设置multiple = true并定期调用basicAck。
失败重试
知识总结
- 死信队列(DLX):将失败消息路由到指定队列,由备用消费者处理。
- 重试机制:通过
RetryTemplate或Spring Retry实现本地重试。
细节
- 死信条件:需设置
x-dead-letter-exchange和max-delivery。 - 重试间隔:指数退避避免雪崩,需与业务逻辑匹配。
使用场景
- 需要重试的失败消息(如网络波动、临时服务不可用)。
常见八股文
- Q:如何配置死信队列?
A:设置队列参数x-dead-letter-exchange和x-dead-letter-routing-key。 - Q:本地重试与死信队列的区别?
A:本地重试在消费者端重试,死信队列将消息转移至其他队列处理。
业务幂等
知识总结
- 核心思想:同一消息多次处理结果一致。
- 实现方式:数据库唯一索引、Redis 记录消息 ID、版本号校验。
细节
- 分布式幂等:需全局唯一 ID(如
UUID)和分布式锁。 - 幂等与性能:如 Redis 记录需考虑缓存穿透和过期时间。
使用场景
- 避免重复扣款、重复发券等业务场景。
常见八股文
- Q:如何实现 RabbitMQ 消息的幂等性?
A:通过消息 ID 记录(如 Redis)或数据库唯一约束。 - Q:幂等与事务的区别?
A:幂等关注结果一致性,事务关注操作的原子性。
延迟消息
知识总结
- 实现方式:
- 插件方式:
rabbitmq_delayed_message_exchange(需配置x-delay)。 - 死信方式:通过 TTL + DLX 实现。
- 插件方式:
- 插件配置:声明延迟交换机
x-delayed-message。
细节
- 插件依赖:需安装
rabbitmq_delayed_message_exchange插件。 - TTL 方案:需多个队列支持不同延迟时间。
使用场景
- 定时任务(如优惠券过期通知、订单超时取消)。
常见八股文
- Q:RabbitMQ 如何实现延迟消息?
A:使用延迟插件或 TTL + DLX 方案。 - Q:插件方案与 TTL 方案的优缺点?
A:插件方案灵活(单消息延迟),TTL 需预设队列但性能更高。
AOP代理失效的情况
一、内部方法调用(this调用)
现象
- 目标类中一个方法调用本类的另一个方法时,AOP不生效。
原因
- AOP通过代理对象拦截方法调用,但
this引用直接指向原始对象,绕过了代理。
解决方法
- 通过代理对象调用:从Spring容器中获取代理对象。
- 启用CGLIB代理:配置
proxyTargetClass=true。
示例
@Service
public class MyService {
@Autowired
private MyService proxyService; // 通过Spring注入代理对象
public void methodA() {
methodB(); // 失效(直接调用this的方法)
proxyService.methodB(); // 生效(通过代理对象调用)
}
@Loggable // 自定义切面注解
public void methodB() {}
}
// 配置CGLIB代理
@Configuration
@EnableAspectJAutoProxy(proxyTargetClass = true)
public class AppConfig {}
二、静态方法调用
现象
- 切面无法拦截静态方法。
原因
- 静态方法属于类而非实例,代理对象无法覆盖静态方法。
解决方法
- 将静态方法改为实例方法,并确保通过代理对象调用。
示例
public class MyService {
public static void staticMethod() { // 无法被AOP拦截
// ...
}
public void instanceMethod() { // 可被拦截
// ...
}
}
三、final方法或类
现象
- 标有
final的关键字的方法或类无法被AOP拦截。
原因
- CGLIB无法生成子类覆盖
final方法。
解决方法
- 移除
final修饰符。
示例
@Service
public class MyService {
@Loggable
public final void finalMethod() { // 失效(final方法)
// ...
}
}
四、私有方法(private)
现象
- 私有方法无法被切面拦截。
原因
- 代理对象无法访问私有方法。
解决方法
- 将方法改为
public、protected或包级可见。
示例
@Service
public class MyService {
@Loggable
private void privateMethod() { // 失效(私有方法)
// ...
}
}
五、未正确配置AOP
现象
- 切面类未被识别或切点表达式错误。
原因
- 缺少
@Aspect注解或未启用AOP支持。
解决方法
- 添加
@Aspect到切面类。 - 确保主配置类有
@EnableAspectJAutoProxy。
示例
// ✅ 正确配置
@Aspect
@Component
public class LoggingAspect {
@After("execution(* com.example..*(..))")
public void log() {
System.out.println("Logged!");
}
}
@Configuration
@EnableAspectJAutoProxy
public class AppConfig {}
六、目标对象未由Spring管理
现象
- 手动
new的对象无法触发AOP。
原因
- 非Spring管理的对象没有被代理。
解决方法
- 通过
@Autowired或ApplicationContext获取Bean。
示例
// ❌ 错误:手动new对象
MyService service = new MyService();
service.method(); // 无AOP
// ✅ 正确:通过Spring容器获取
@Autowired
private MyService service;
service.method(); // 有AOP
七、异步方法(@Async)
现象
- 标有
@Async的方法可能无法触发AOP。
原因
- 异步方法由独立线程执行,代理逻辑可能未正确传递。
解决方法
- 确保切面支持异步方法,或使用
@EnableAsync并配置代理。
示例
@Service
public class MyService {
@Async
@Loggable
public void asyncMethod() { // 需要特殊处理
// ...
}
}
八、切点表达式错误
现象
- 切点未匹配到目标方法。
原因
- 表达式语法错误或范围不匹配。
解决方法
- 检查
execution表达式是否正确。
示例
// ❌ 错误表达式:未匹配到包路径
@After("execution(* com.example.service..*(..))")
// ✅ 正确表达式:匹配所有service包的方法
@After("execution(* com.example.service.*.*(..))")
九、循环依赖
现象
- 循环依赖可能导致AOP代理未正确生成。
原因
- Spring在解决循环依赖时可能返回未增强的早期Bean引用。
解决方法
- 重构代码消除循环依赖,或使用
@Lazy延迟注入。
示例
@Service
public class ServiceA {
@Autowired
private ServiceB serviceB; // 可能导致循环依赖
}
@Service
public class ServiceB {
@Autowired
private ServiceA serviceA;
}
十、事务与AOP的冲突
现象
- 事务注解
@Transactional与AOP同时失效。
原因
- 事务本身依赖AOP代理,若AOP失效则事务也失效。
解决方法
- 确保事务方法在代理对象上调用(如Service层而非内部调用)。
排查步骤总结
- 检查配置:确认切面类有
@Aspect,主类有@EnableAspectJAutoProxy。 - 验证Bean管理:确保目标对象是Spring管理的Bean。
- 检查方法可见性:非
public方法或final方法无法被拦截。 - 内部调用问题:通过代理对象调用方法,避免
this直接调用。 - 切点表达式:确保表达式语法正确且匹配目标方法。
- 异步与事务:处理
@Async或@Transactional的特殊场景。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











