






一、JavaSE
1、继承与多态 √
面向对象的三大特征:封装、继承、多态。三大特征紧密联系而又有区别,合理使用继承能大大减少重复代码,提高代码复用性。
封装从字面上来理解就是包装的意思,专业点就是信息隐藏,是指利用抽象将数据和基于数据的操作封装在一起,使其构成一个不可分割的独立实体。
数据被保护在类的内部,尽可能地隐藏内部的实现细节,只保留一些对外接口使之与外部发生联系。
其他对象只能通过已经授权的操作来与这个封装的对象进行交互。也就是说用户是无需知道对象内部的细节(当然也无从知道),但可以通过该对象对外的提供的接口来访问该对象。
使用封装有 4 大好处:
-
1、良好的封装能够减少耦合。
-
2、类内部的结构可以自由修改。
-
3、可以对成员进行更精确的控制。
-
4、隐藏信息,实现细节。
首先我们先来看两个类。
Husband.java
public class Husband {
/*
* 对属性的封装
* 一个人的姓名、性别、年龄、妻子都是这个人的私有属性
*/
private String name ;
private String sex ;
private int age ;
private Wife wife;
/*
* setter()、getter()是该对象对外开发的接口
*/
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public void setWife(Wife wife) {
this.wife = wife;
}
}Wife.java
public class Wife {
private String name;
private int age;
private String sex;
private Husband husband;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public void setAge(int age) {
this.age = age;
}
public void setHusband(Husband husband) {
this.husband = husband;
}
public Husband getHusband() {
return husband;
}
}可以看得出, Husband 类里面的 wife 属性是没有 getter()的,同时 Wife 类的 age 属性也是没有 getter()方法的。所以封装把一个对象的属性私有化,同时提供一些可以被外界访问的属性的方法,如果不想被外界方法,我们大可不必提供方法给外界访问。
但是如果一个类没有提供给外界任何可以访问的方法,那么这个类也没有什么意义了。比如我们将一个房子看做是一个对象,里面有漂亮的装饰,如沙发、电视剧、空调、茶桌等等都是该房子的私有属性,但是如果我们没有那些墙遮挡,是不是别人就会一览无余呢?没有一点儿隐私!因为存在那个遮挡的墙,我们既能够有自己的隐私而且我们可以随意的更改里面的摆设而不会影响到外面的人。但是如果没有门窗,一个包裹的严严实实的黑盒子,又有什么存在的意义呢?所以通过门窗别人也能够看到里面的风景。所以说门窗就是房子对象留给外界访问的接口。
通过这个我们还不能真正体会封装的好处。现在我们从程序的角度来分析封装带来的好处。如果我们不使用封装,那么该对象就没有 setter()和 getter(),那么 Husband 类应该这样写:
public class Husband {
public String name ;
public String sex ;
public int age ;
public Wife wife;
}我们应该这样来使用它:
Husband husband = new Husband();
husband.age = 30;
husband.name = "张三";
husband.sex = "男"; //貌似有点儿多余但是哪天如果我们需要修改 Husband,例如将 age 修改为 String 类型的呢?你只有一处使用了这个类还好,如果你有几十个甚至上百个这样地方,你是不是要改到崩溃。如果使用了封装,我们完全可以不需要做任何修改,只需要稍微改变下 Husband 类的 setAge()方法即可。
public class Husband {
/*
* 对属性的封装
* 一个人的姓名、性别、年龄、妻子都是这个人的私有属性
*/
private String name ;
private String sex ;
private String age ; /* 改成 String类型的*/
private Wife wife;
public String getAge() {
return age;
}
public void setAge(int age) {
//转换即可
this.age = String.valueOf(age);
}
/** 省略其他属性的setter、getter **/
}其他的地方依然这样引用( husband.setAge(22) )保持不变。
到了这里我们确实可以看出,封装确实可以使我们更容易地修改类的内部实现,而无需修改使用了该类的代码。
我们再看这个好处:封装可以对成员变量进行更精确的控制。
还是那个 Husband,一般来说我们在引用这个对象的时候是不容易出错的,但是有时你迷糊了,写成了这样:
Husband husband = new Husband();
husband.age = 300;使用封装我们就可以避免这个问题,我们对 age 的访问入口做一些控制(setter)如:
public class Husband {
/*
* 对属性的封装
* 一个人的姓名、性别、年龄、妻子都是这个人的私有属性
*/
private String name ;
private String sex ;
private int age ; /* 改成 String类型的*/
private Wife wife;
public int getAge() {
return age;
}
public void setAge(int age) {
if(age > 120){
System.out.println("ERROR:error age input...."); //提示錯誤信息
}else{
this.age = age;
}
}
/** 省略其他属性的setter、getter **/
}上面都是对 setter 方法的控制,其实通过封装我们也能够对对象的出口做出很好的控制。例如性别在数据库中一般都是以 1、0 的方式来存储的,但是在前台我们又不能展示 1、0,这里我们只需要在 getter()方法里面做一些转换即可。
public String getSexName() {
if("0".equals(sex)){
sexName = "女";
}
else if("1".equals(sex)){
sexName = "男";
}
return sexName;
}在使用的时候我们只需要使用 sexName 即可实现正确的性别显示。同理也可以用于针对不同的状态做出不同的操作。
public String getCzHTML(){
if("1".equals(zt)){
czHTML = "<a href='javascript:void(0)' onclick='qy("+id+")'>启用</a>";
}
else{
czHTML = "<a href='javascript:void(0)' onclick='jy("+id+")'>禁用</a>";
}
return czHTML;
}继承(英语:inheritance)是面向对象软件技术中的一个概念。它使得复用以前的代码非常容易。
Java 语言是非常典型的面向对象的语言,在 Java 语言中继承就是子类继承父类的属性和方法,使得子类对象(实例)具有父类的属性和方法,或子类从父类继承方法,使得子类具有父类相同的方法。
我们来举个例子:动物有很多种,是一个比较大的概念。在动物的种类中,我们熟悉的有猫(Cat)、狗(Dog)等动物,它们都有动物的一般特征(比如能够吃东西,能够发出声音),不过又在细节上有区别(不同动物的吃的不同,叫声不一样)。
在 Java 语言中实现 Cat 和 Dog 等类的时候,就需要继承 Animal 这个类。继承之后 Cat、Dog 等具体动物类就是子类,Animal 类就是父类。
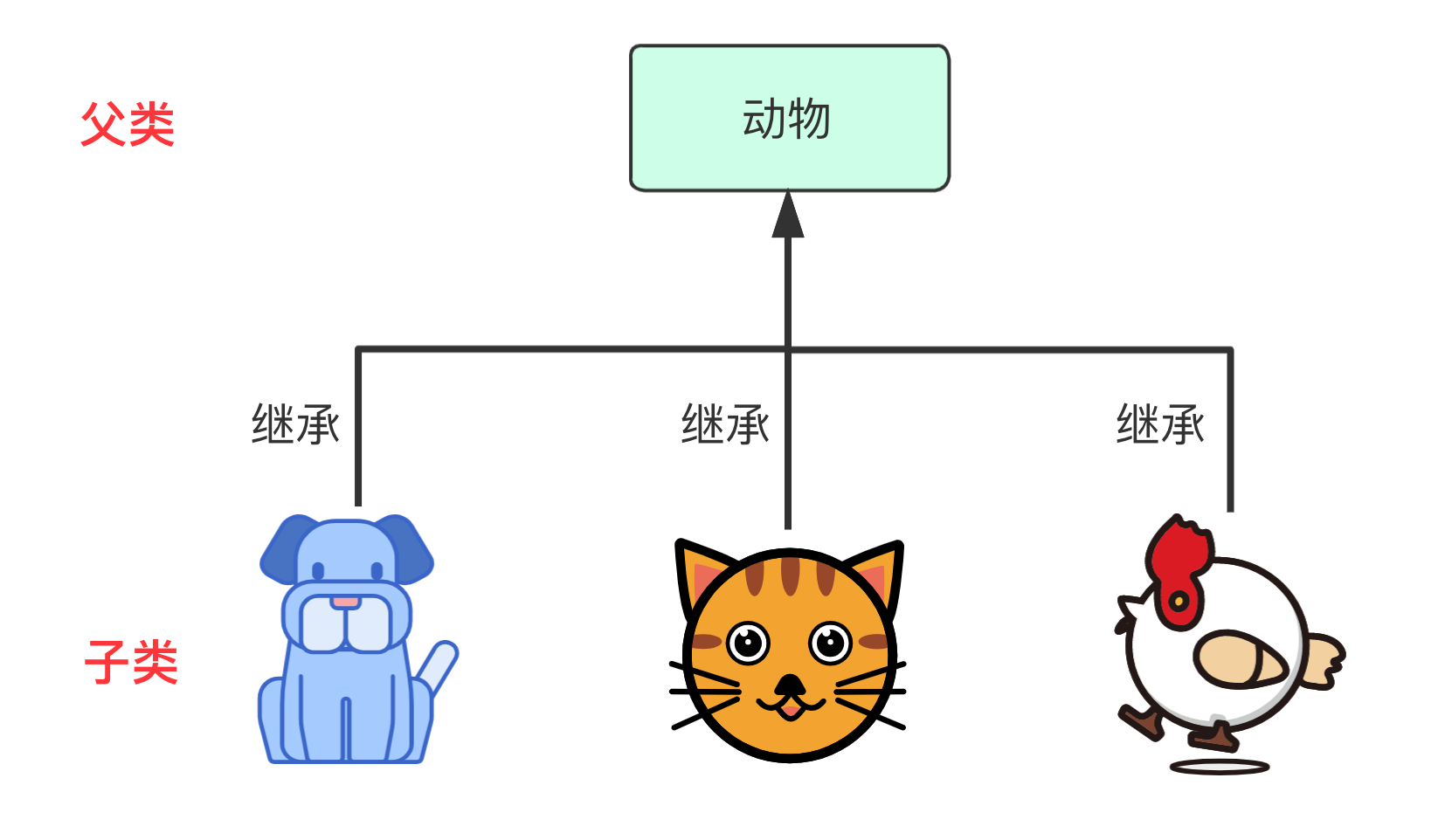
如果仅仅只有两三个类,每个类的属性和方法很有限的情况下确实没必要实现继承,但事情并非如此,事实上一个系统中往往有很多个类并且有着很多相似之处,比如猫和狗同属动物,或者学生和老师同属人。各个类可能又有很多个相同的属性和方法,这样的话如果每个类都重新写不仅代码显得很乱,代码工作量也很大。
这时继承的优势就出来了:可以直接使用父类的属性和方法,自己也可以有自己新的属性和方法满足拓展,父类的方法如果自己有需求更改也可以重写。这样使用继承不仅大大的减少了代码量,也使得代码结构更加清晰可见。
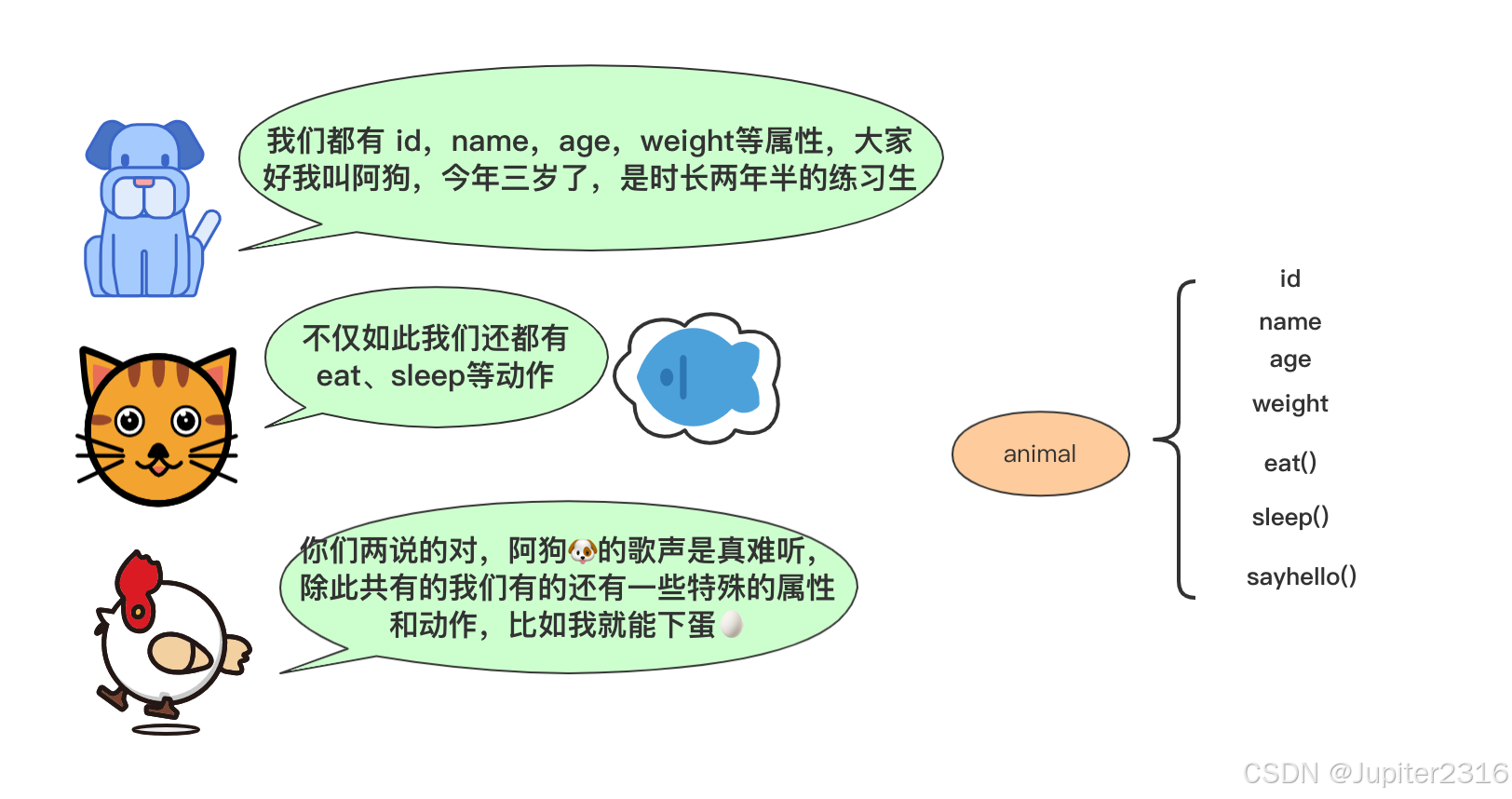
所以这样从代码的层面上来看我们设计这个完整的 Animal 类是这样的:
class Animal
{
public int id;
public String name;
public int age;
public int weight;
public Animal(int id, String name, int age, int weight) {
this.id = id;
this.name = name;
this.age = age;
this.weight = weight;
}
//这里省略get set方法
public void sayHello()
{
System.out.println("hello");
}
public void eat()
{
System.out.println("I'm eating");
}
public void sing()
{
System.out.println("sing");
}
}而 Dog,Cat,Chicken 类可以这样设计:
class Dog extends Animal//继承animal
{
public Dog(int id, String name, int age, int weight) {
super(id, name, age, weight);//调用父类构造方法
}
}
class Cat extends Animal{
public Cat(int id, String name, int age, int weight) {
super(id, name, age, weight);//调用父类构造方法
}
}
class Chicken extends Animal{
public Chicken(int id, String name, int age, int weight) {
super(id, name, age, weight);//调用父类构造方法
}
//鸡下蛋
public void layEggs()
{
System.out.println("我是老母鸡下蛋啦,咯哒咯!咯哒咯!");
}
}各自的类继承 Animal 后可以直接使用 Animal 类的属性和方法而不需要重复编写,各个类如果有自己的方法也可很容易地拓展。
继承分为单继承和多继承,Java 语言只支持类的单继承,但可以通过实现接口的方式达到多继承的目的。
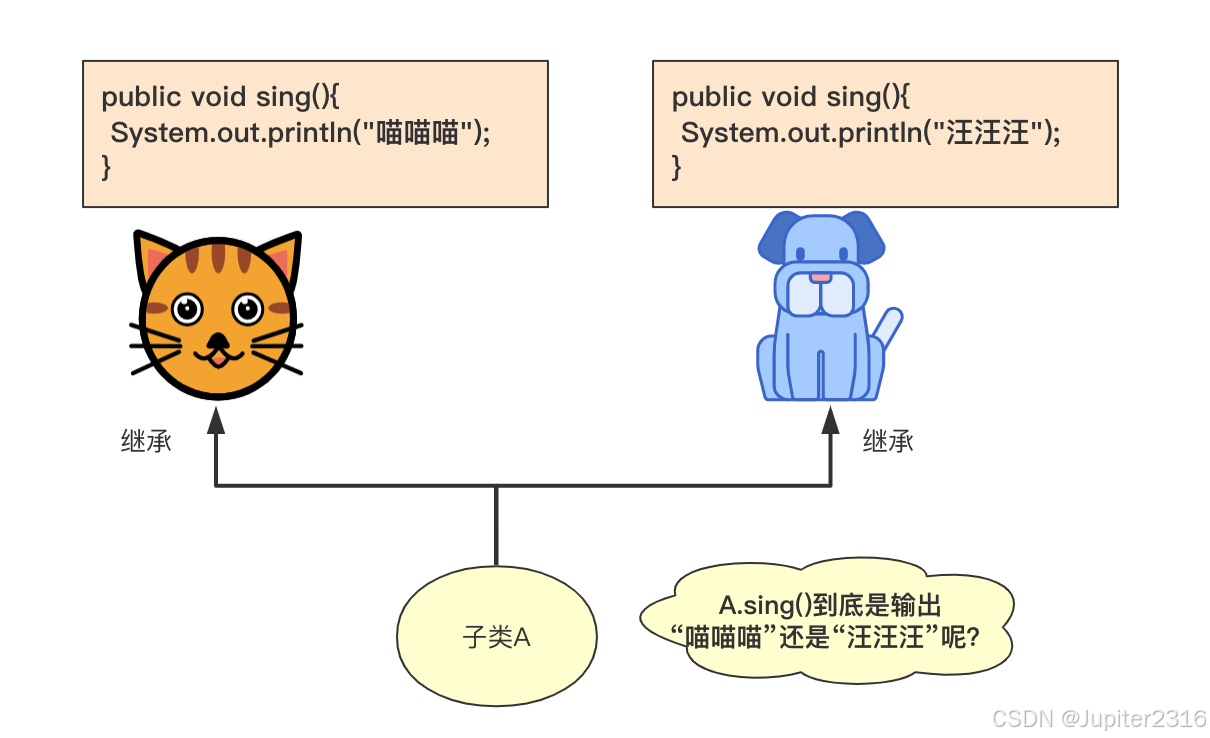
单继承,一个子类只有一个父类,如我们上面讲过的 Animal 类和它的子类。单继承在类层次结构上比较清晰,但缺点是结构的丰富度有时不能满足使用需求。
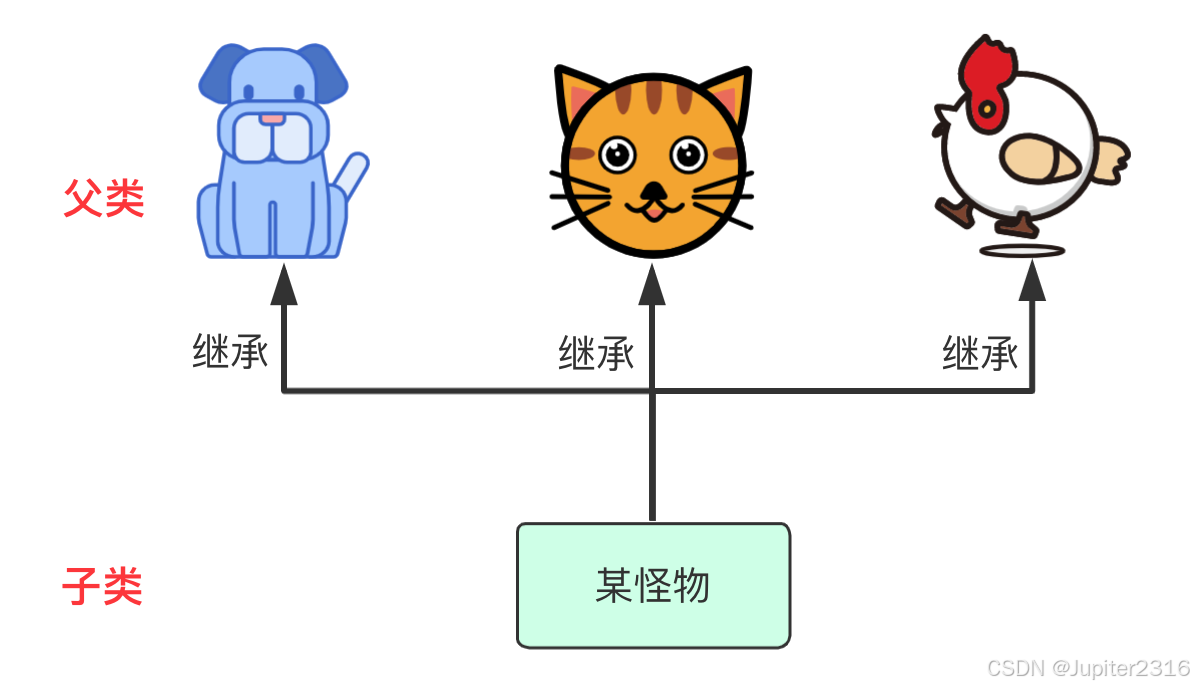
多继承,一个子类有多个直接的父类。这样做的好处是子类拥有所有父类的特征,子类的丰富度很高,但是缺点就是容易造成混乱。下图为一个混乱的例子。
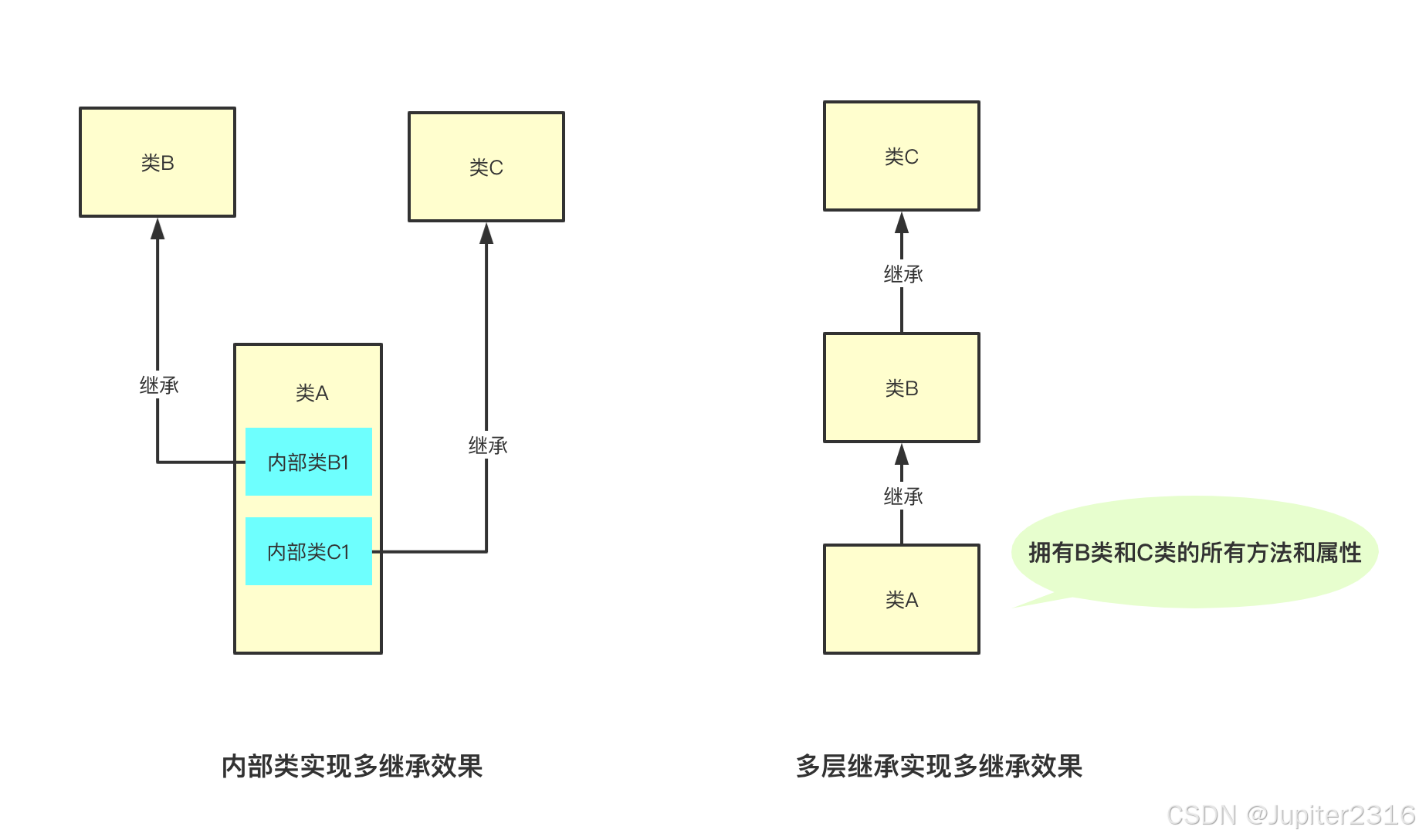
Java 虽然不支持多继承,但是 Java 有三种实现多继承效果的方式,分别是内部类、多层继承和实现接口。
内部类可以继承一个与外部类无关的类,保证了内部类的独立性,正是基于这一点,可以达到多继承的效果。
多层继承:子类继承父类,父类如果还继承其他的类,那么这就叫多层继承。这样子类就会拥有所有被继承类的属性和方法。
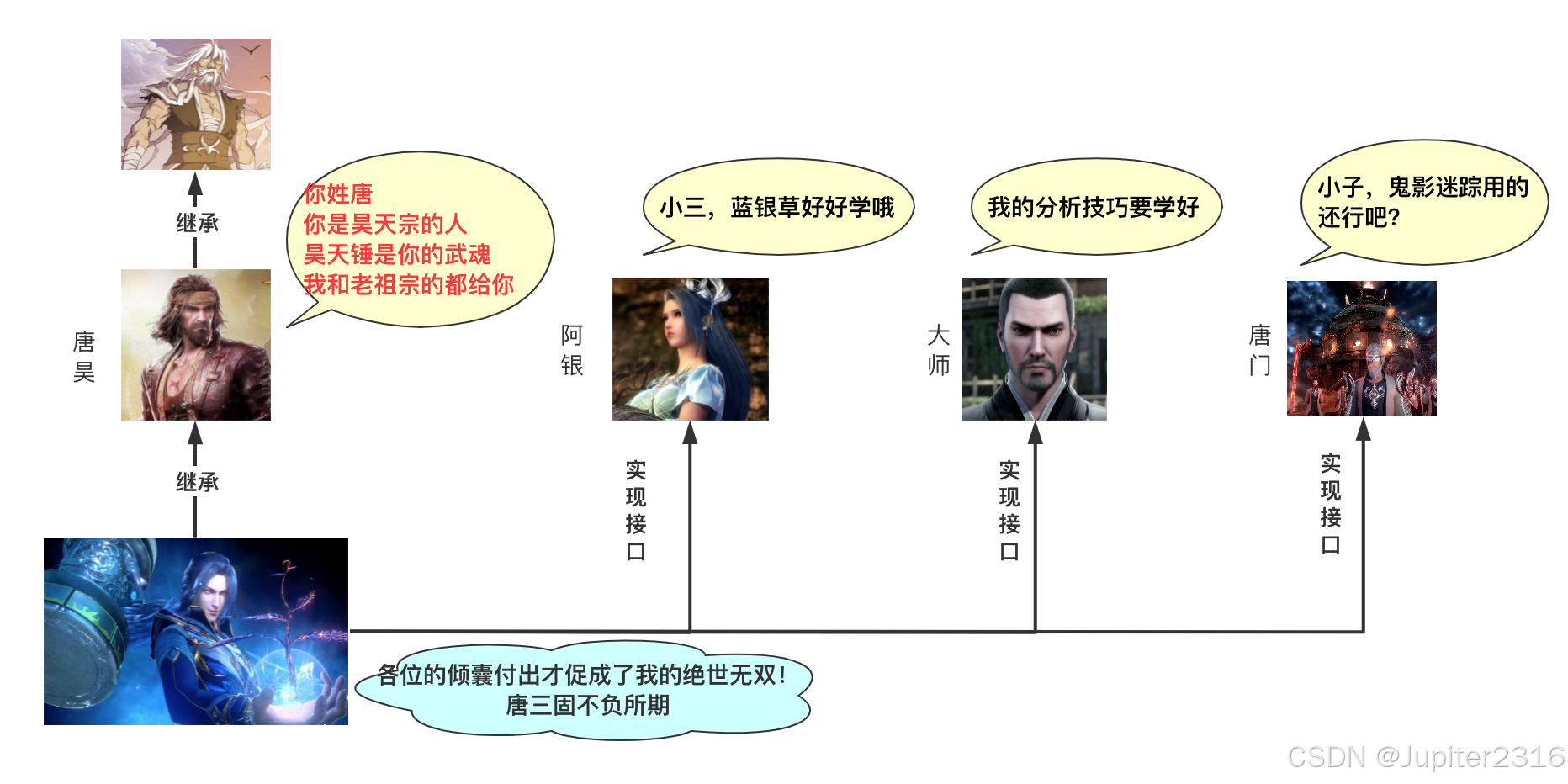
实现接口无疑是满足多继承使用需求的最好方式,一个类可以实现多个接口满足自己在丰富性和复杂环境的使用需求。
类和接口相比,类就是一个实体,有属性和方法,而接口更倾向于一组方法。举个例子,就拿斗罗大陆的唐三来看,他存在的继承关系可能是这样的:
在 Java 中,类的继承是单一继承,也就是说一个子类只能拥有一个父类,所以extends只能继承一个类。其使用语法为:
class 子类名 extends 父类名{}例如 Dog 类继承 Animal 类,它是这样的:
class Animal{} //定义Animal类
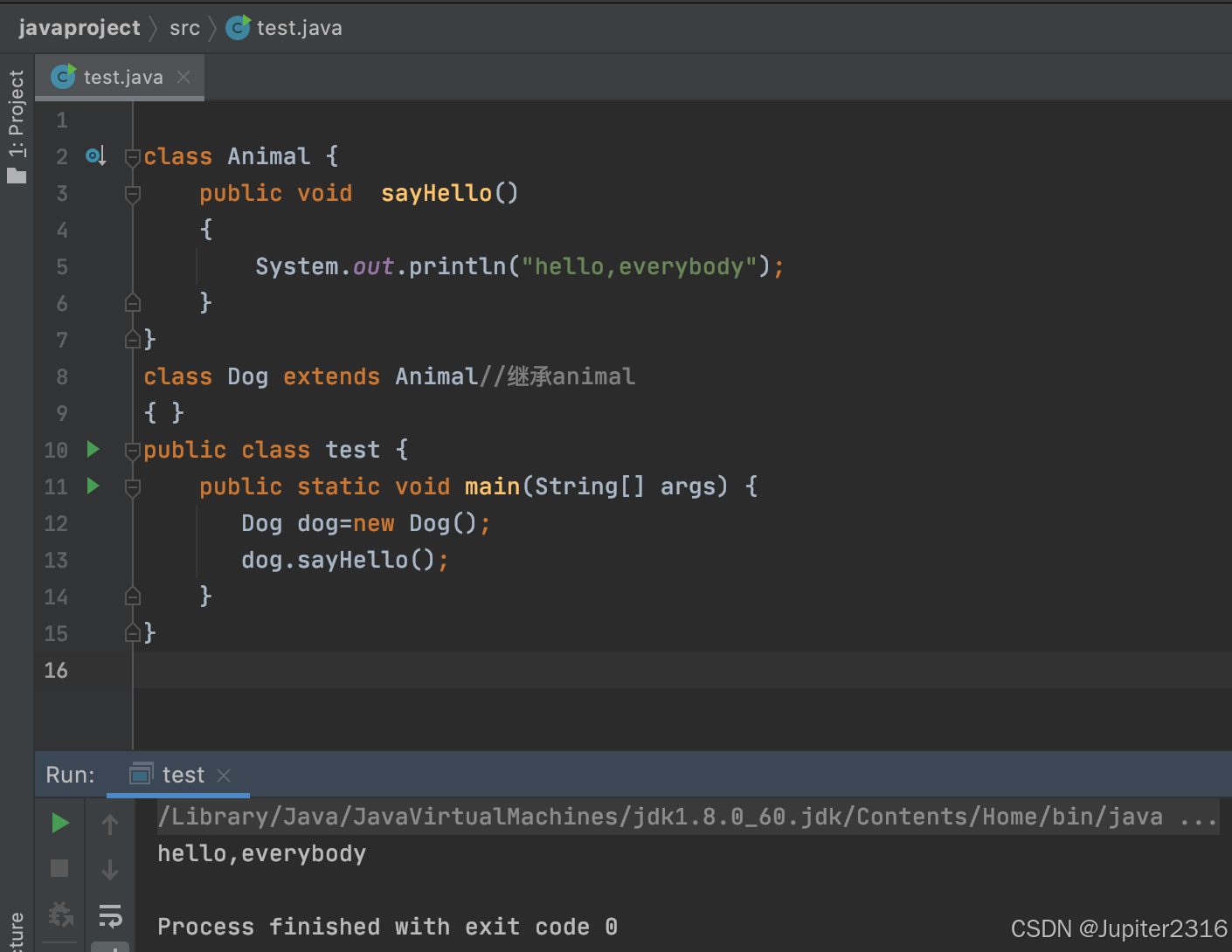
class Dog extends Animal{} //Dog类继承Animal类子类继承父类后,就拥有父类的非私有的属性和方法。如果不明白,请看这个案例,在 IDEA 下创建一个项目,创建一个 test 类做测试,分别创建 Animal 类和 Dog 类,Animal 作为父类写一个 sayHello()方法,Dog 类继承 Animal 类之后就可以调用 sayHello()方法。具体代码为:
class Animal {
public void sayHello()//父类的方法
{
System.out.println("hello,everybody");
}
}
class Dog extends Animal//继承animal
{ }
public class test {
public static void main(String[] args) {
Dog dog=new Dog();
dog.sayHello();
}
}点击运行的时候 Dog 子类可以直接使用 Animal 父类的方法。
使用 implements 关键字可以变相使 Java 拥有多继承的特性,使用范围为类实现接口的情况,一个类可以实现多个接口(接口与接口之间用逗号分开)。
我们来看一个案例,创建一个 test2 类做测试,分别创建 doA 接口和 doB 接口,doA 接口声明 sayHello()方法,doB 接口声明 eat()方法,创建 Cat2 类实现 doA 和 doB 接口,并且在类中需要重写 sayHello()方法和 eat()方法。具体代码为:
interface doA{
void sayHello();
}
interface doB{
void eat();
//以下会报错 接口中的方法不能具体定义只能声明
//public void eat(){System.out.println("eating");}
}
class Cat2 implements doA,doB{
@Override//必须重写接口内的方法
public void sayHello() {
System.out.println("hello!");
}
@Override
public void eat() {
System.out.println("I'm eating");
}
}
public class test2 {
public static void main(String[] args) {
Cat2 cat=new Cat2();
cat.sayHello();
cat.eat();
}
}Cat 类实现 doA 和 doB 接口的时候,需要实现其声明的方法,点击运行结果如下,这就是一个类实现接口的简单案例:
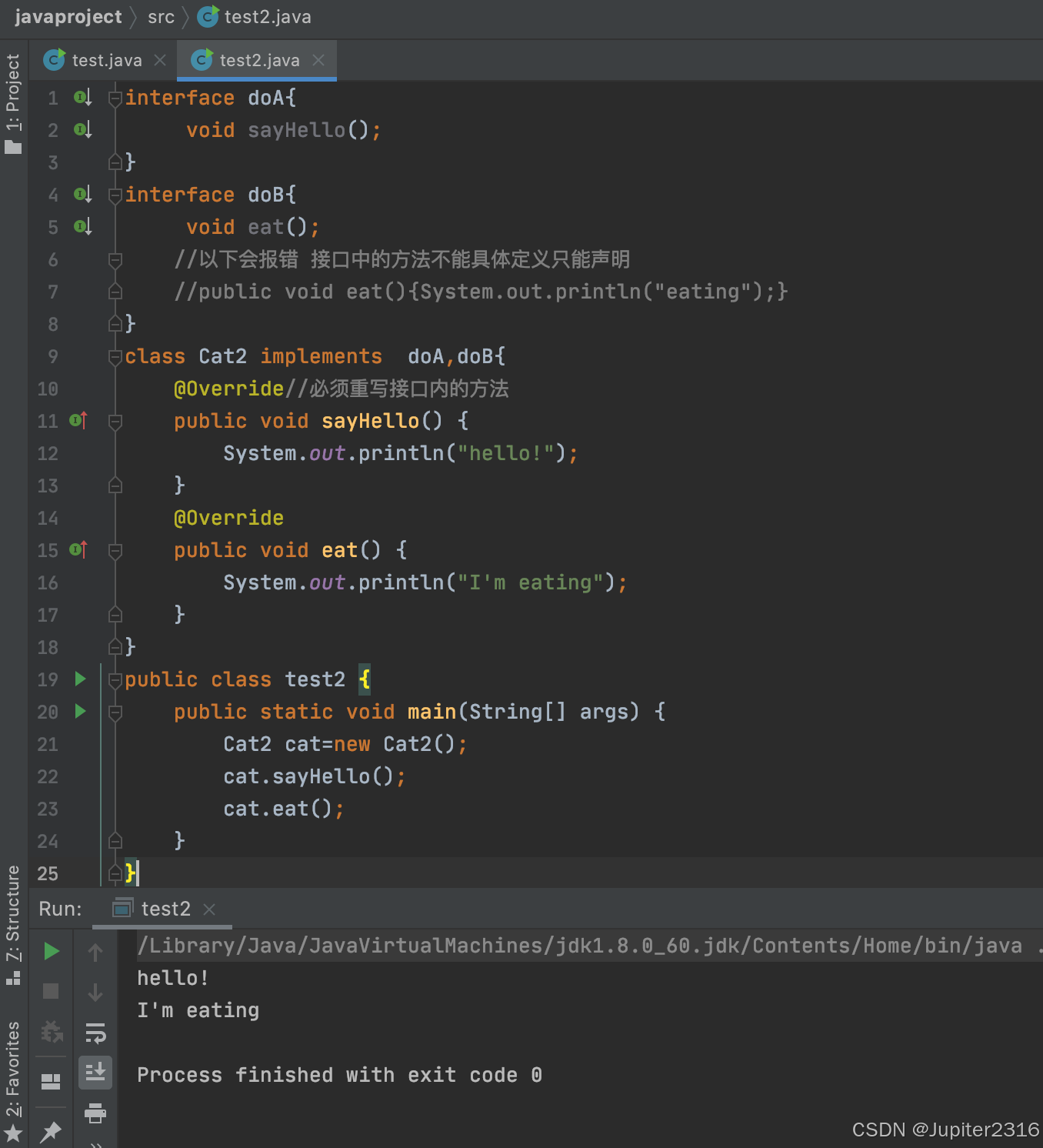
继承的主要内容就是子类继承父类,并重写父类的方法。使用子类的属性或方法时候,首先要创建一个对象,而对象通过构造方法去创建,在构造方法中我们可能会调用子父类的一些属性和方法,所以就需要提前掌握 this 和 super 关键字。
创建完这个对象之后,再调用重写父类后的方法,注意重写和重载的区别。
Java 修饰符的作用就是对类或类成员进行修饰或限制,每个修饰符都有自己的作用,而在继承中可能有些特殊修饰符使得被修饰的属性或方法不能被继承,或者继承需要一些其他的条件。
Java 语言提供了很多修饰符,修饰符用来定义类、方法或者变量,通常放在语句的最前端。主要分为以下两类:
-
访问权限修饰符,也就是 public、private、protected 等
-
非访问修饰符,也就是 static、final、abstract 等
Java 的多态是指在面向对象编程中,同一个类的对象在不同情况下表现出来的不同行为和状态。
-
子类可以继承父类的字段和方法,子类对象可以直接使用父类中的方法和字段(私有的不行)。
-
子类可以重写从父类继承来的方法,使得子类对象调用这个方法时表现出不同的行为。
-
可以将子类对象赋给父类类型的引用,这样就可以通过父类类型的引用调用子类中重写的方法,实现多态。
多态的目的是为了提高代码的灵活性和可扩展性,使得代码更容易维护和扩展。
比如说,通过允许子类继承父类的方法并重写,增强了代码的复用性。
再比如说多态可以实现动态绑定,这意味着程序在运行时再确定对象的方法调用也不迟。
在我的印象里,西游记里的那段孙悟空和二郎神的精彩对战就能很好的解释“多态”这个词:一个孙悟空,能七十二变;一个二郎神,也能七十二变;他们都可以变成不同的形态,只需要悄悄地喊一声“变”。
Java 的多态是什么?其实就是一种能力——同一个行为具有不同的表现形式;换句话说就是,执行一段代码,Java 在运行时能根据对象类型的不同产生不同的结果。和孙悟空和二郎神都只需要喊一声“变”,然后就变了,并且每次变得还不一样;一个道理。
多态的前提条件有三个:
-
子类继承父类
-
子类重写父类的方法
-
父类引用指向子类的对象
多态的一个简单应用,来看程序清单 1-1:
//子类继承父类
public class Wangxiaoer extends Wanger {
public void write() { // 子类重写父类方法
System.out.println("记住仇恨,表明我们要奋发图强的心智");
}
public static void main(String[] args) {
// 父类引用指向子类对象
Wanger[] wangers = { new Wanger(), new Wangxiaoer() };
for (Wanger wanger : wangers) {
// 对象是王二的时候输出:勿忘国耻
// 对象是王小二的时候输出:记住仇恨,表明我们要奋发图强的心智
wanger.write();
}
}
}
class Wanger {
public void write() {
System.out.println("勿忘国耻");
}
}现在,我们来思考一个问题:程序清单 1-1 在执行 wanger.write() 时,由于编译器只有一个 Wanger 引用,它怎么知道究竟该调用父类 Wanger 的 write() 方法,还是子类 Wangxiaoer 的 write() 方法呢?
答案是在运行时根据对象的类型进行后期绑定,编译器在编译阶段并不知道对象的类型,但是 Java 的方法调用机制能找到正确的方法体,然后执行,得到正确的结果。
多态机制提供的一个重要的好处就是程序具有良好的扩展性。来看程序清单 2-1:
//子类继承父类
public class Wangxiaoer extends Wanger {
public void write() { // 子类覆盖父类方法
System.out.println("记住仇恨,表明我们要奋发图强的心智");
}
public void eat() {
System.out.println("我不喜欢读书,我就喜欢吃");
}
public static void main(String[] args) {
// 父类引用指向子类对象
Wanger[] wangers = { new Wanger(), new Wangxiaoer() };
for (Wanger wanger : wangers) {
// 对象是王二的时候输出:勿忘国耻
// 对象是王小二的时候输出:记住仇恨,表明我们要奋发图强的心智
wanger.write();
}
}
}
class Wanger {
public void write() {
System.out.println("勿忘国耻");
}
public void read() {
System.out.println("每周读一本好书");
}
}在程序清单 2-1 中,我们在 Wanger 类中增加了 read() 方法,在 Wangxiaoer 类中增加了 eat()方法,但这丝毫不会影响到 write() 方法的调用。
write() 方法忽略了周围代码发生的变化,依然正常运行。这让我想起了金庸《倚天屠龙记》里九阳真经的口诀:“他强由他强,清风拂山岗;他横由他横,明月照大江。”
多态的这个优秀的特性,让我们在修改代码的时候不必过于紧张,因为多态是一项让程序员“将改变的与未改变的分离开来”的重要特性。
在构造方法中调用多态方法,会产生一个奇妙的结果,我们来看程序清单 3-1:
public class Wangxiaosan extends Wangsan {
private int age = 3;
public Wangxiaosan(int age) {
this.age = age;
System.out.println("王小三的年龄:" + this.age);
}
public void write() { // 子类覆盖父类方法
System.out.println("我小三上幼儿园的年龄是:" + this.age);
}
public static void main(String[] args) {
new Wangxiaosan(4);
// 上幼儿园之前
// 我小三上幼儿园的年龄是:0
// 上幼儿园之后
// 王小三的年龄:4
}
}
class Wangsan {
Wangsan () {
System.out.println("上幼儿园之前");
write();
System.out.println("上幼儿园之后");
}
public void write() {
System.out.println("老子上幼儿园的年龄是3岁半");
}
}从输出结果上看,是不是有点诧异?明明在创建 Wangxiaosan 对象的时候,年龄传递的是 4,但输出结果既不是“老子上幼儿园的年龄是 3 岁半”,也不是“我小三上幼儿园的年龄是:4”。
为什么?
因为在创建子类对象时,会先去调用父类的构造方法,而父类构造方法中又调用了被子类覆盖的多态方法,由于父类并不清楚子类对象中的字段值是什么,于是把 int 类型的属性暂时初始化为 0,然后再调用子类的构造方法(子类构造方法知道王小二的年龄是 4)。
向下转型是指将父类引用强转为子类类型;这是不安全的,因为有的时候,父类引用指向的是父类对象,向下转型就会抛出 ClassCastException,表示类型转换失败;但如果父类引用指向的是子类对象,那么向下转型就是成功的。
来看程序清单 4-1:
public class Wangxiaosi extends Wangsi {
public void write() {
System.out.println("记住仇恨,表明我们要奋发图强的心智");
}
public void eat() {
System.out.println("我不喜欢读书,我就喜欢吃");
}
public static void main(String[] args) {
Wangsi[] wangsis = { new Wangsi(), new Wangxiaosi() };
// wangsis[1]能够向下转型
((Wangxiaosi) wangsis[1]).write();
// wangsis[0]不能向下转型
((Wangxiaosi)wangsis[0]).write();
}
}
class Wangsi {
public void write() {
System.out.println("勿忘国耻");
}
public void read() {
System.out.println("每周读一本好书");
}
}-
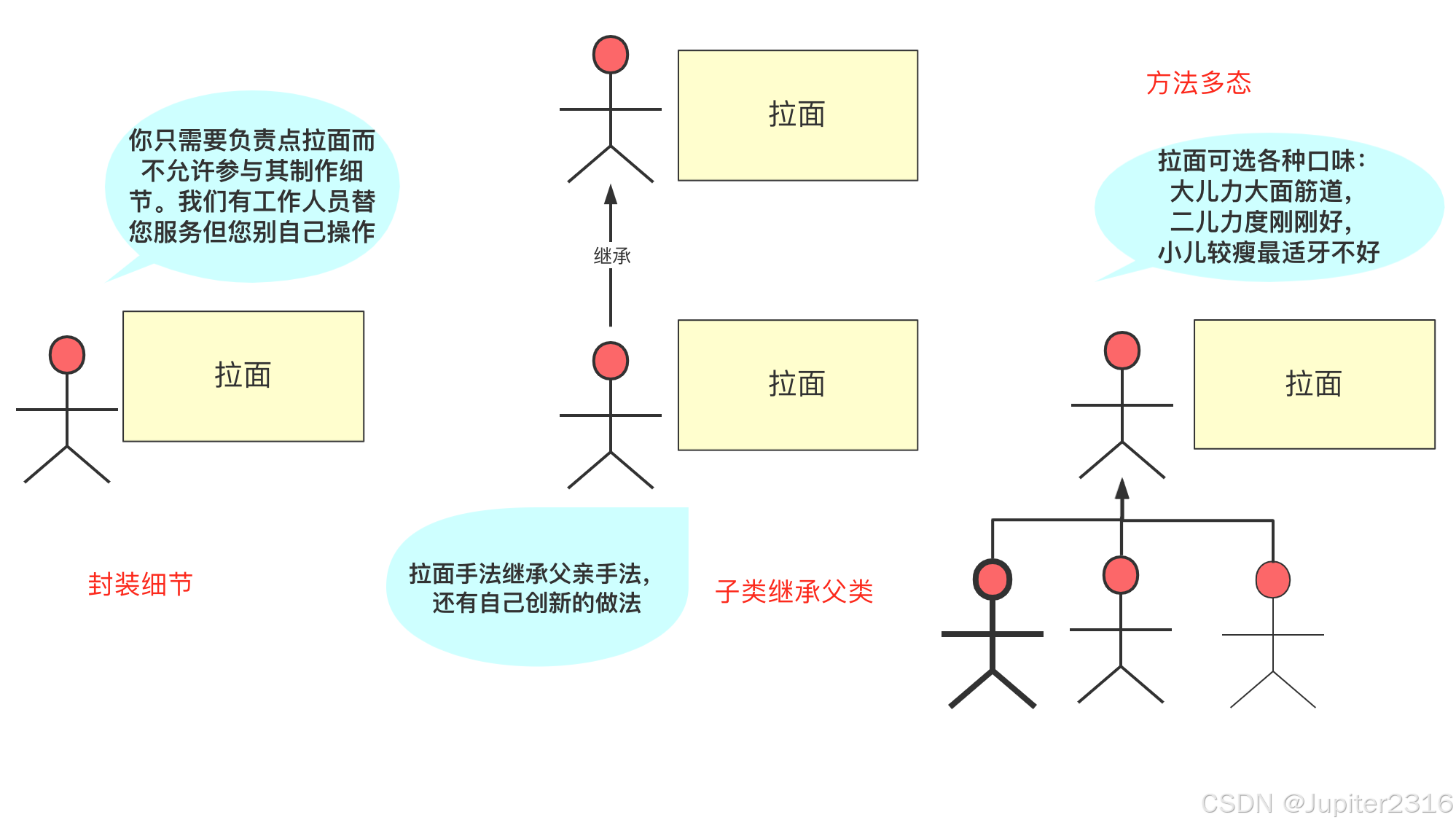
封装:是对类的封装,封装是对类的属性和方法进行封装,只对外暴露方法而不暴露具体使用细节,所以我们一般设计类成员变量时候大多设为私有而通过一些 get、set 方法去读写。
-
继承:子类继承父类,即“子承父业”,子类拥有父类除私有的所有属性和方法,自己还能在此基础上拓展自己新的属性和方法。主要目的是复用代码。
-
多态:多态是同一个行为具有多个不同表现形式或形态的能力。即一个父类可能有若干子类,各子类实现父类方法有多种多样,调用父类方法时,父类引用变量指向不同子类实例而执行不同方法,这就是所谓父类方法是多态的。
最后送你一张图捋一捋其中的关系吧。
2、抽象类与接口 √
对于面向对象编程来说,抽象是它的一大特征之一。在 Java 中,可以通过两种形式来体现 OOP 的抽象:接口和抽象类。这两者有太多相似的地方,又有太多不同的地方。很多人在初学的时候会以为它们可以随意互换使用,但是实际则不然。
一、抽象类
在了解抽象类之前,先来了解一下抽象方法。抽象方法是一种特殊的方法:它只有声明,而没有具体的实现。抽象方法的声明格式为:
abstract void fun();抽象方法必须用 abstract 关键字进行修饰。如果一个类含有抽象方法,则称这个类为抽象类,抽象类必须在类前用 abstract 关键字修饰。因为抽象类中含有无具体实现的方法,所以不能用抽象类创建对象。
下面要注意一个问题:在《JAVA 编程思想》一书中,将抽象类定义为"包含抽象方法的类",但是后面发现如果一个类不包含抽象方法,只是用 abstract 修饰的话也是抽象类。也就是说抽象类不一定必须含有抽象方法。
[public] abstract class ClassName {
abstract void fun();
}从这里可以看出,抽象类就是为了继承而存在的,如果你定义了一个抽象类,却不去继承它,那么等于白白创建了这个抽象类,因为你不能用它来做任何事情。对于一个父类,如果它的某个方法在父类中实现出来没有任何意义,必须根据子类的实际需求来进行不同的实现,那么就可以将这个方法声明为 abstract 方法,此时这个类也就成为 abstract 类了。
包含抽象方法的类称为抽象类,但并不意味着抽象类中只能有抽象方法,它和普通类一样,同样可以拥有成员变量和普通的成员方法。注意,抽象类和普通类的主要有三点区别:
- 1)抽象方法必须为 public 或者 protected(因为如果为 private,则不能被子类继承,子类便无法实现该方法),默认情况下默认为 public。
- 2)抽象类不能用来创建对象;
- 3)如果一个类继承于一个抽象类,则子类必须实现父类的抽象方法。如果子类没有实现父类的抽象方法,则必须将子类也定义为为 abstract 类。
- 在其他方面,抽象类和普通的类并没有区别。
二、接口
接口,英文称作 interface,在软件工程中,接口泛指供别人调用的方法或者函数。从这里,我们可以体会到 Java 语言设计者的初衷,它是对行为的抽象。在 Java 中,定一个接口的形式如下:
[public] interface InterfaceName {
}接口中可以含有 变量和方法。但是要注意,接口中的变量会被隐式地指定为 public static final 变量(并且只能是 public static final变量,用 private 修饰会报编译错误),而方法会被隐式地指定为 public abstract 方法且只能是 public abstract 方法(用其他关键字,比如 private、protected、static、 final 等修饰会报编译错误),并且接口中所有的方法不能有具体的实现,也就是说,接口中的方法必须都是抽象方法。从这里可以隐约看出接口和抽象类的区别,接口是一种极度抽象的类型,它比抽象类更加"抽象",并且一般情况下不在接口中定义变量。
要让一个类遵循某组特地的接口需要使用 implements 关键字,具体格式如下:
class ClassName implements Interface1,Interface2,[....]{
}可以看出,允许一个类遵循多个特定的接口。如果一个非抽象类遵循了某个接口,就必须实现该接口中的所有方法。对于遵循某个接口的抽象类,可以不实现该接口中的抽象方法。
抽象类和接口的区别
1、语法层面上的区别
-
1)抽象类可以提供成员方法的实现细节,而接口中只能存在public abstract 方法;
-
2)抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是public static final类型的;
-
3)接口中不能含有静态代码块以及静态方法,而抽象类可以有静态代码块和静态方法;
-
4)一个类只能继承一个抽象类,而一个类却可以实现多个接口。
2、设计层面上的区别
1)抽象类是对一种事物的抽象,即对类抽象,而接口是对行为的抽象。抽象类是对整个类整体进行抽象,包括属性、行为,但是接口却是对类局部(行为)进行抽象。举个简单的例子,飞机和鸟是不同类的事物,但是它们都有一个共性,就是都会飞。那么在设计的时候,可以将飞机设计为一个类 Airplane,将鸟设计为一个类 Bird,但是不能将 飞行 这个特性也设计为类,因此它只是一个行为特性,并不是对一类事物的抽象描述。此时可以将 飞行 设计为一个接口Fly,包含方法fly( ),然后Airplane和Bird分别根据自己的需要实现Fly这个接口。然后至于有不同种类的飞机,比如战斗机、民用飞机等直接继承Airplane即可,对于鸟也是类似的,不同种类的鸟直接继承Bird类即可。从这里可以看出,继承是一个 "是不是"的关系,而 接口 实现则是 "有没有"的关系。如果一个类继承了某个抽象类,则子类必定是抽象类的种类,而接口实现则是有没有、具备不具备的关系,比如鸟是否能飞(或者是否具备飞行这个特点),能飞行则可以实现这个接口,不能飞行就不实现这个接口。
2)设计层面不同,抽象类作为很多子类的父类,它是一种模板式设计。而接口是一种行为规范,它是一种辐射式设计。什么是模板式设计?最简单例子,大家都用过 ppt 里面的模板,如果用模板 A 设计了 ppt B 和 ppt C,ppt B 和 ppt C 公共的部分就是模板 A 了,如果它们的公共部分需要改动,则只需要改动模板 A 就可以了,不需要重新对 ppt B 和 ppt C 进行改动。而辐射式设计,比如某个电梯都装了某种报警器,一旦要更新报警器,就必须全部更新。也就是说对于抽象类,如果需要添加新的方法,可以直接在抽象类中添加具体的实现,子类可以不进行变更;而对于接口则不行,如果接口进行了变更,则所有实现这个接口的类都必须进行相应的改动。
下面看一个网上流传最广泛的例子:门和警报的例子:门都有 open() 和 close() 两个动作,此时我们可以定义通过抽象类和接口来定义这个抽象概念:
abstract class Door {
public abstract void open();
public abstract void close();
}或者:
interface Door {
public abstract void open();
public abstract void close();
}但是现在如果我们需要门具有报警 的功能,那么该如何实现?下面提供两种思路:
1)将这三个功能都放在抽象类里面,但是这样一来所有继承于这个抽象类的子类都具备了报警功能,但是有的门并不一定具备报警功能;
2)将这三个功能都放在接口里面,需要用到报警功能的类就需要实现这个接口中的 open( ) 和 close( ),也许这个类根本就不具备 open( ) 和 close( ) 这两个功能,比如火灾报警器。
从这里可以看出, Door 的 open() 、close() 和 alarm() 根本就属于两个不同范畴内的行为,open() 和 close() 属于门本身固有的行为特性,而 alarm() 属于延伸的附加行为。因此最好的解决办法是单独将报警设计为一个接口,包含 alarm() 行为,Door 设计为单独的一个抽象类,包含 open 和 close 两种行为。再设计一个报警门继承 Door 类和实现 Alarm 接口。
interface Alram {
void alarm();
}
abstract class Door {
void open();
void close();
}
class AlarmDoor extends Door implements Alarm {
void oepn() {
//....
}
void close() {
//....
}
void alarm() {
//....
}
}3、Java内存模型
蚂蚁金服面试官:说说Java的内存模型(JMM) | 二哥的Java进阶之路
4、GC垃圾回收 √
垃圾回收是一种在堆内存中找出哪些对象在被使用,还有哪些对象没被使用,并且将后者回收掉的机制。
所谓使用中的对象,指的是程序中还有引用的对象;而未使用中的对象,指的是程序中已经没有引用的对象,该对象占用的内存也可以被回收掉。
Java 语言出来之前,大家都在拼命的写 C 或者 C++ 的程序,此时存在一个很大的矛盾,C++ 等语言创建对象需要不断的去开辟空间,不用的时候又需要不断的去释放空间,既要写构造函数,又要写析构函数,很多时候都在重复的 allocated,然后不停的析构。而 Java 不一样,它有垃圾回收器,释放内存由回收器负责。
垃圾回收的第一步是标记。垃圾回收器此时会找出内存哪些在使用中,哪些不是。
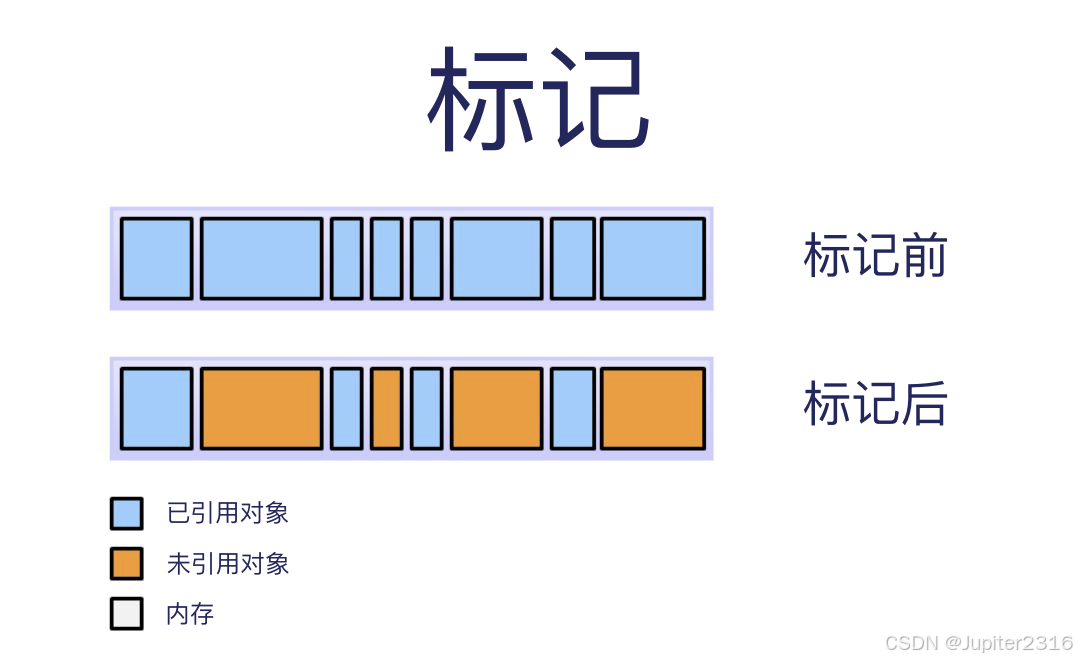
上图中,蓝色表示已引用对象,橙色表示未引用对象。垃圾回收器要检查完所有的对象,才能知道哪些有被引用,哪些没。如果系统里所有的对象都要检查,那这一步可能会相当耗时间。
垃圾回收的第二步是清除,这一步会删掉标记出的未引用对象。
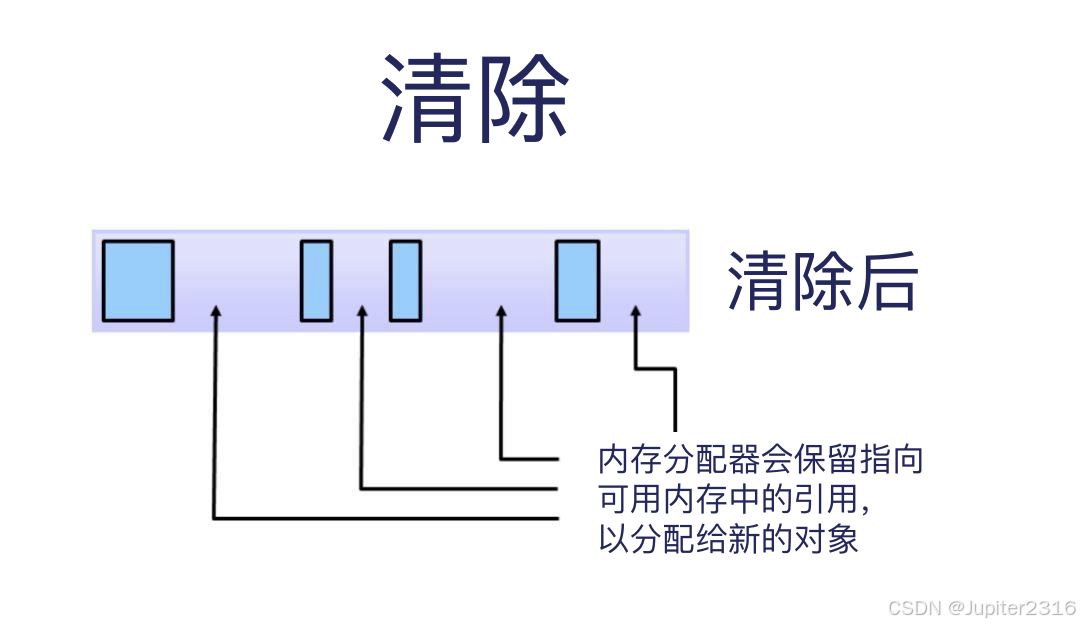
内存分配器会保留指向可用内存中的引用,以分配给新的对象。
垃圾回收的第三步是压缩,为了提升性能,删除了未引用对象后,还可以将剩下的已引用对象放在一起(压缩),这样就能更简单快捷地分配新对象了。
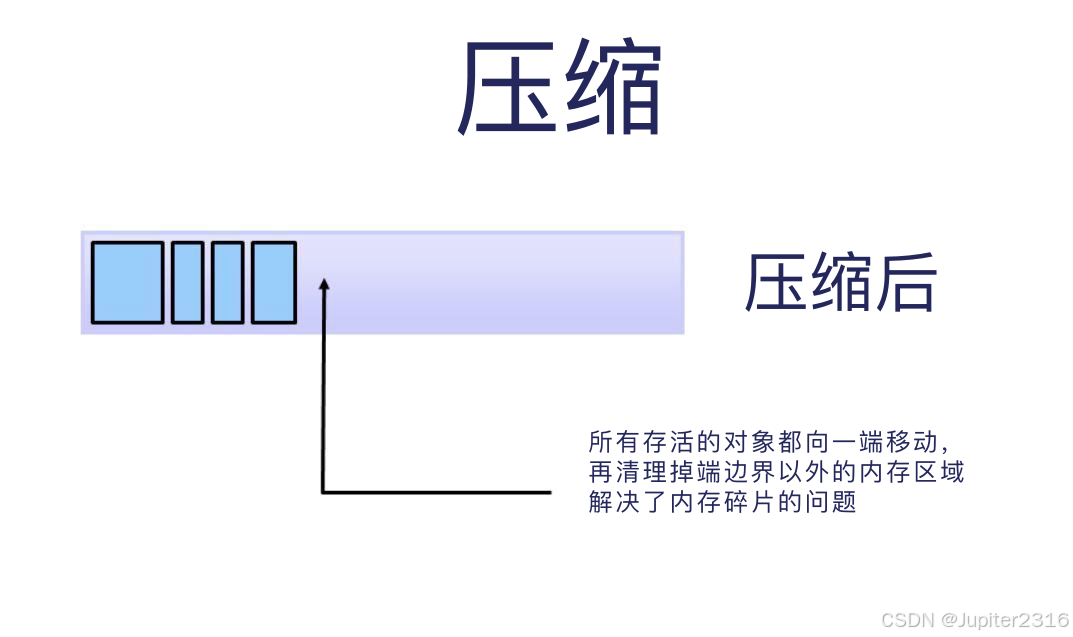
之前提到过,逐一标记和压缩 Java 虚拟机中的所有对象非常低效:分配的对象越多,垃圾回收需要的时间就越久。不过,根据统计,大部分的对象,其实用没多久就不用了。
来看个例子吧。下图中,竖轴代表已分配的字节,而横轴代表程序的运行时间。
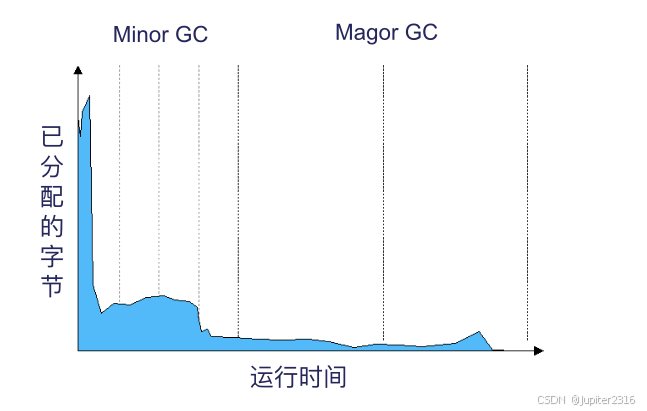
可见,存活(没被释放)的对象随着运行时间越来越少。图中左侧的峰值,也表明了大部分对象其实都挺短命的。
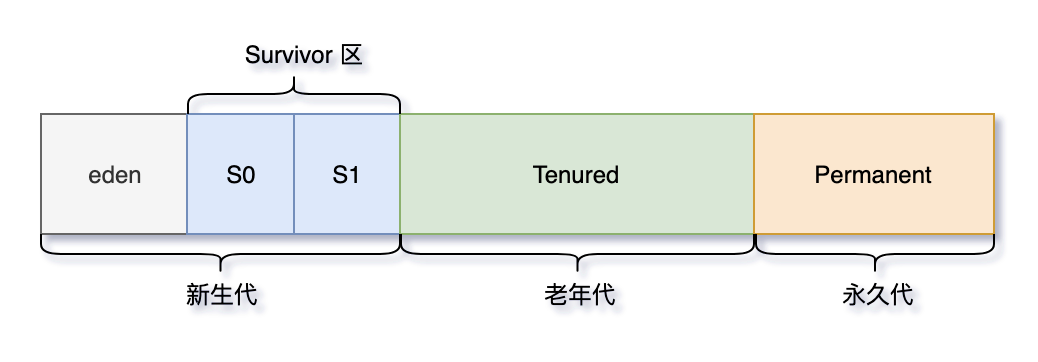
根据之前的规律,就可以用来提升 JVM 的效率了。方法是,把堆分成几个部分(就是所谓的分代),分别是新生代、老年代,以及永生代。
新对象会被分配在新生代内存。一旦新生代内存满了,就会开始对死掉的对象,进行所谓的小型垃圾回收(Minor GC)过程。一片新生代内存里,死掉的越多,回收过程就越快;至于那些还活着的对象,此时就会老化,并最终老到进入老年代内存。
Stop the World 事件 —— 小型垃圾回收属于一种叫 "Stop the World" 的事件。在这种事件发生时,所有的程序线程都要暂停,直到事件完成(比如这里就是完成了所有回收工作)为止。
老年代用来保存长时间存活的对象。通常,设置一个阈值,当达到该年龄时,年轻代对象会被移动到老年代。最终老年代也会被回收。这个事件为 Major GC。
Major GC 也会触发STW(Stop the World)。通常,Major GC会慢很多,因为它涉及到所有存活对象。所以,对于响应性的应用程序,应该尽量避免Major GC。还要注意,Major GC的STW的时长受年老代垃圾回收器类型的影响。
永久代包含JVM用于描述应用程序中类和方法的元数据。永久代是由JVM在运行时根据应用程序使用的类来填充的。此外,Java SE类库和方法也存储在这里。
如果JVM发现某些类不再需要,并且其他类可能需要空间,则这些类可能会被回收。
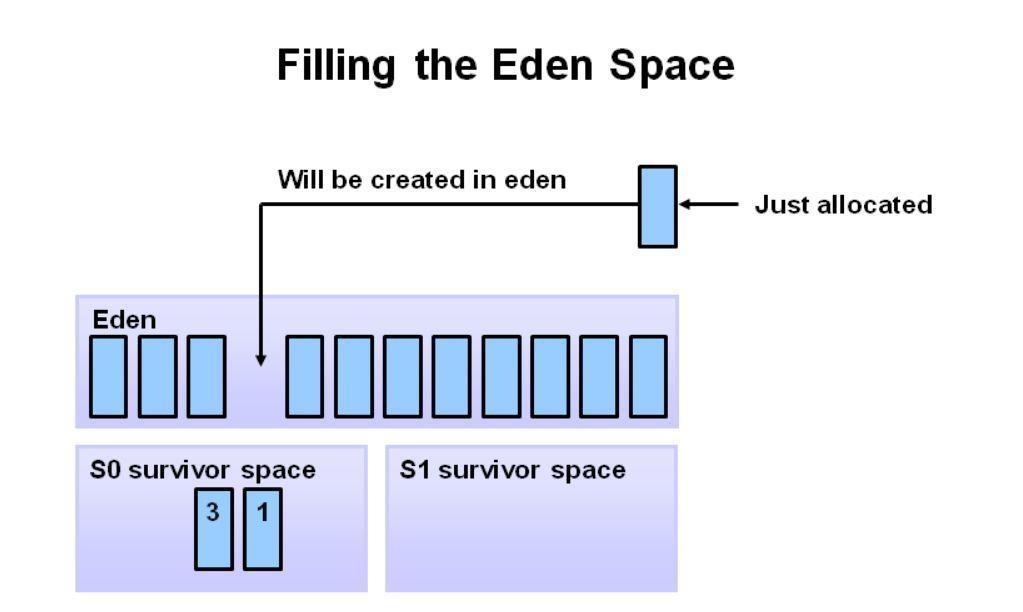
首先,将任何新对象分配给 eden 空间。 两个 survivor 空间都是空的。
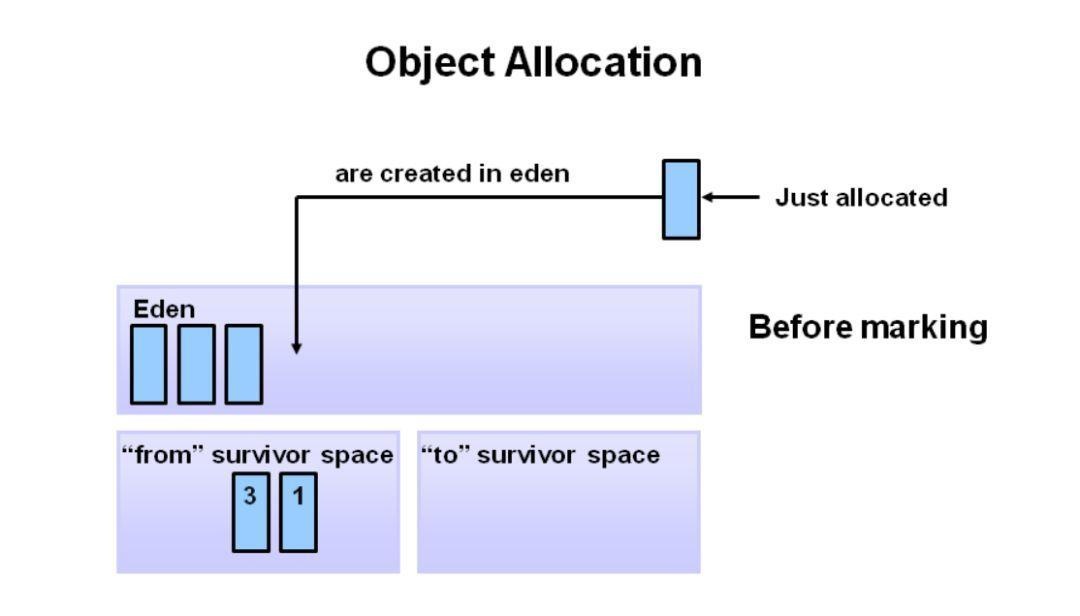
当 eden 空间填满时,会触发轻微的垃圾收集。
引用的对象被移动到第一个 survivor 空间。 清除 eden 空间时,将删除未引用的对象。
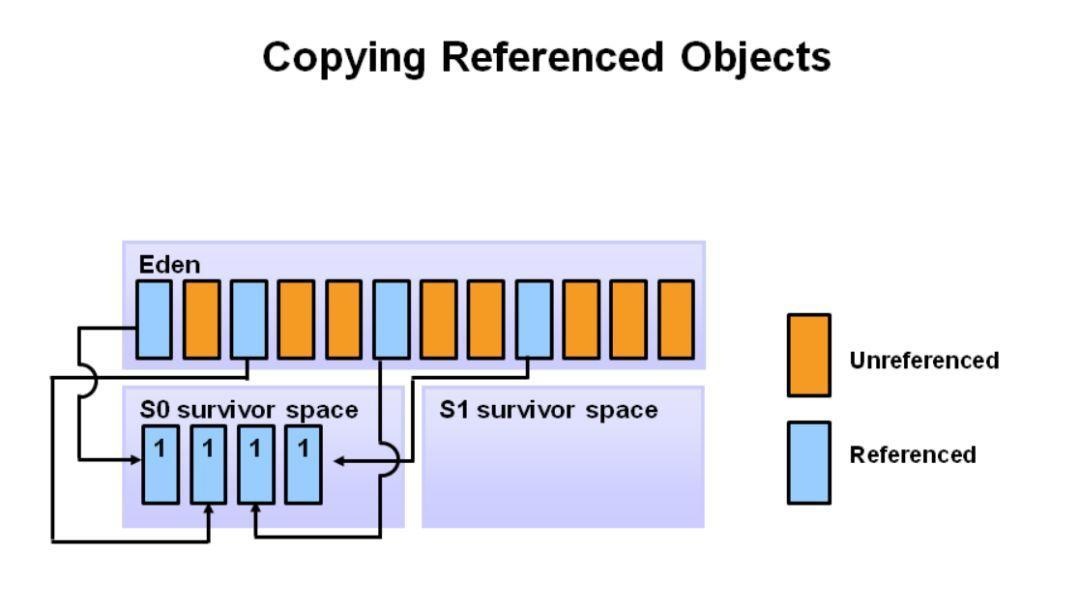
在下一次Minor GC中,Eden区也会做同样的操作。删除未被引用的对象,并将被引用的对象移动到Survivor区。然而,这里,他们被移动到了第二个Survivor区(S1)。
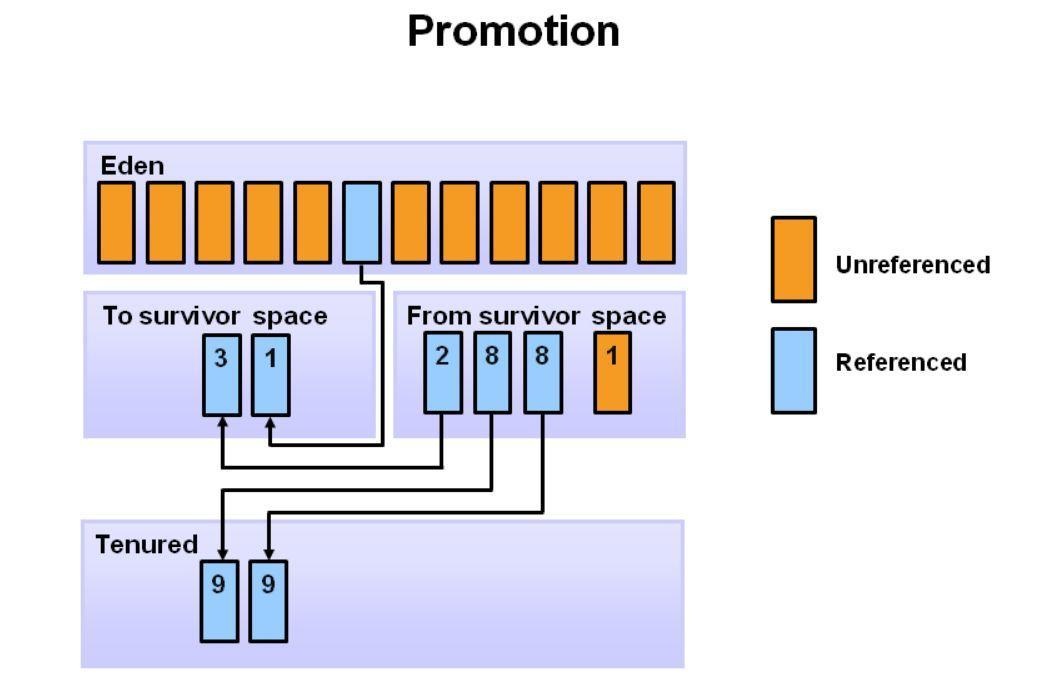
此外,第一个Survivor区(S0)中,在上一次Minor GC幸存的对象,会增加年龄,并被移动到S1中。待所有幸存对象都被移动到S1后,S0和Eden区都会被清空。注意,Survivor区中有了不同年龄的对象。
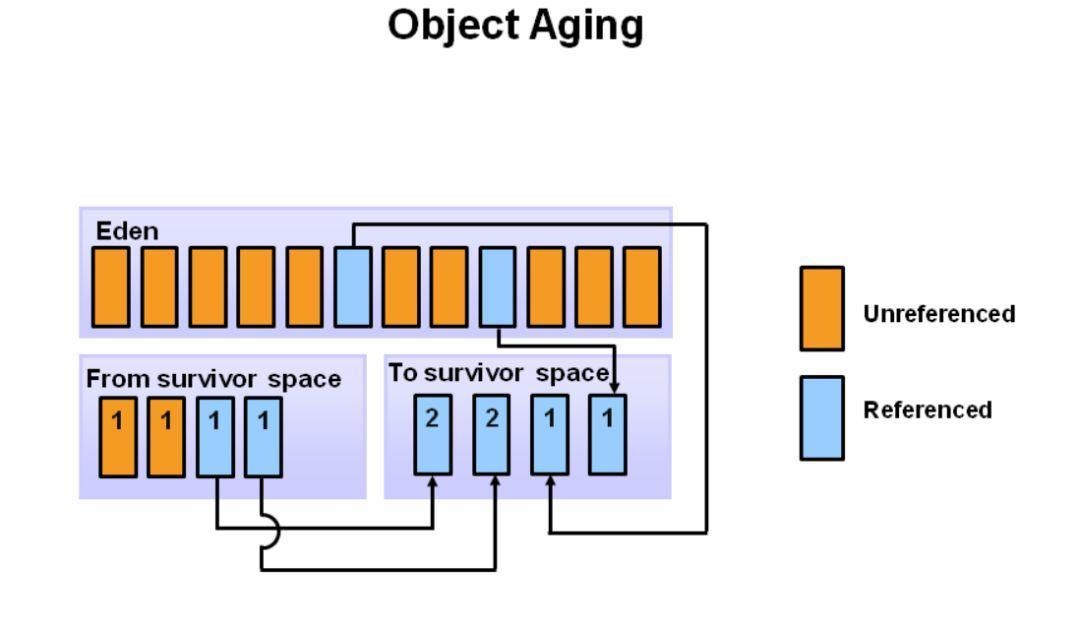
在下一次Minor GC中,会重复同样的操作。不过,这一次Survivor区会交换。被引用的对象移动到S0,。幸存的对象增加年龄。Eden区和S1被清空。
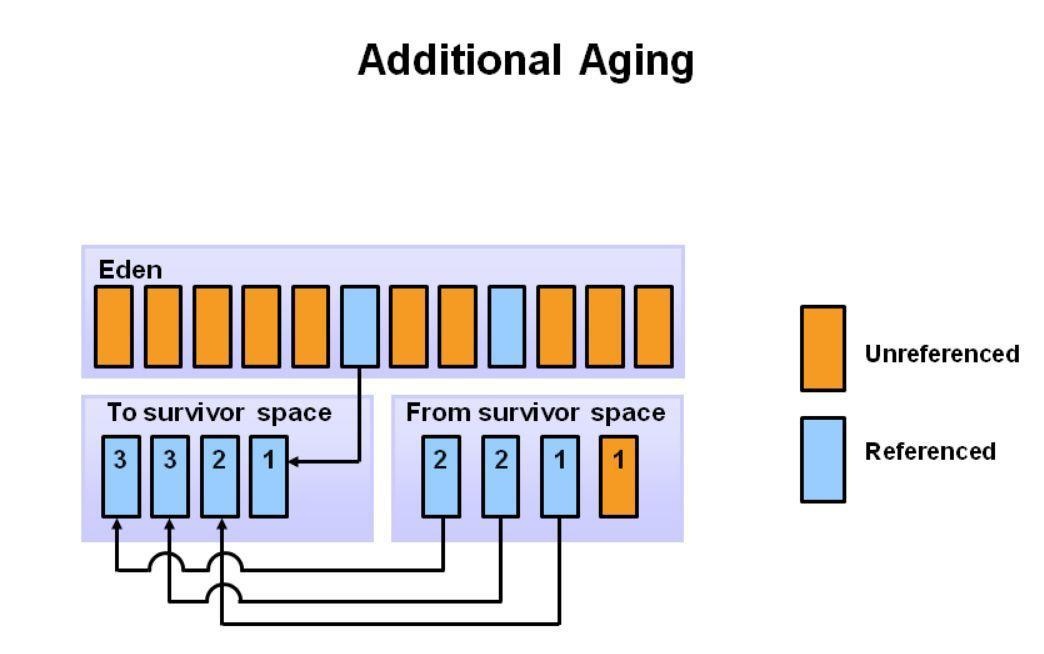
此幻灯片演示了 promotion。 在较小的GC之后,当老化的物体达到一定的年龄阈值(在该示例中为8)时,它们从年轻一代晋升到老一代。
随着较小的GC持续发生,物体将继续被推广到老一代空间。
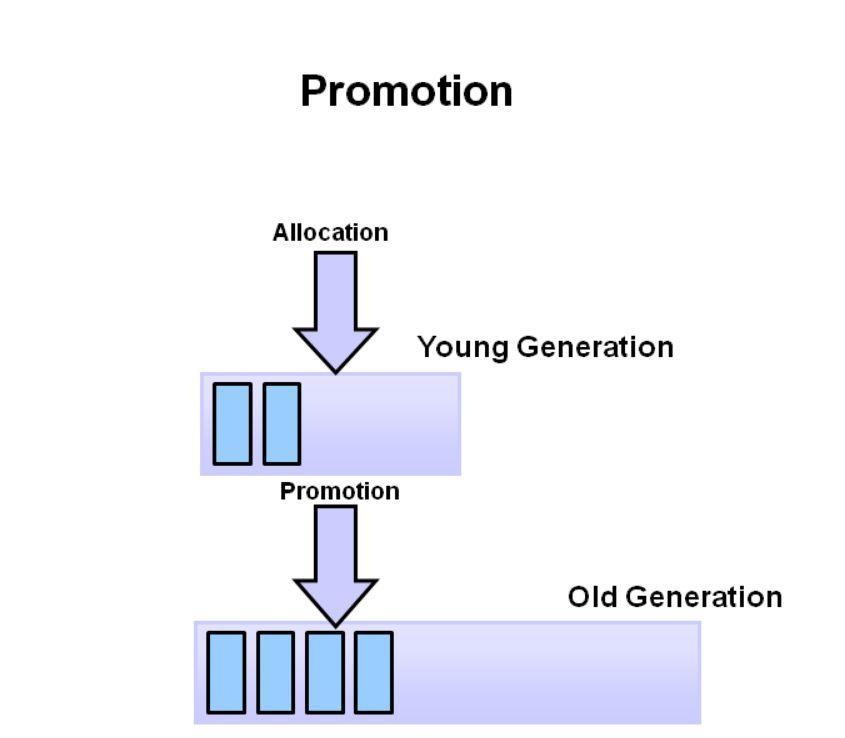
所以这几乎涵盖了年轻一代的整个过程。 最终,将主要对老一代进行GC,清理并最终压缩该空间。
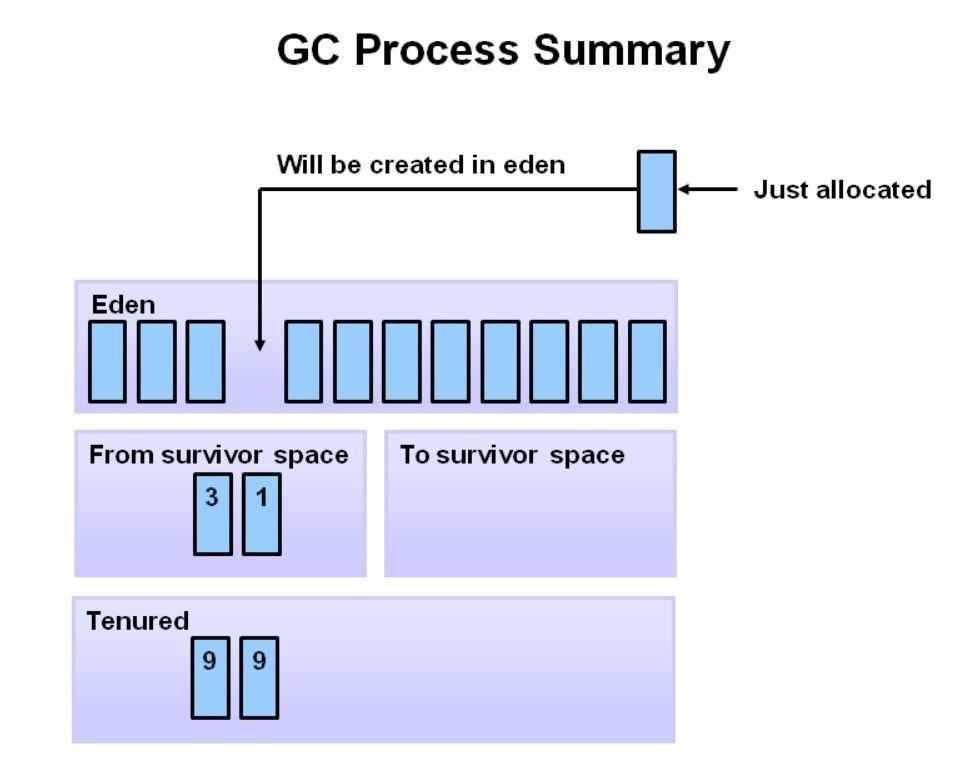
Java 堆(Java Heap)是 JVM 所管理的内存中最大的一块,堆又是垃圾收集器管理的主要区域,这里我们主要分析一下 Java 堆的结构。
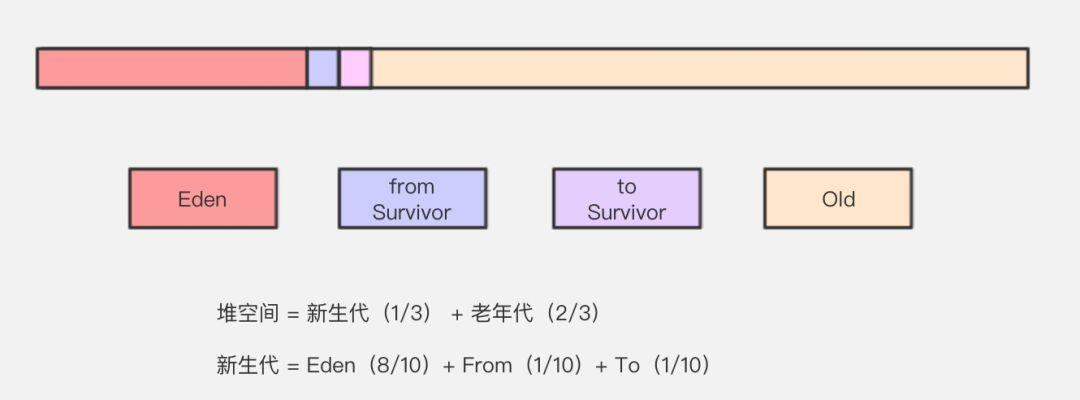
Java 堆主要分为 2 个区域-年轻代与老年代,其中年轻代又分 Eden 区和 Survivor 区,其中 Survivor 区又分 From 和 To 2 个区。可能这时候大家会有疑问,为什么需要 Survivor 区,为什么 Survivor 还要分 2 个区。
大多数情况下,对象会在新生代 Eden 区中进行分配。当 Eden 区没有足够空间进行分配时,虚拟机会发起一次 Minor GC,Minor GC 相比 Major GC 更频繁,回收速度也更快。
通过 Minor GC 之后,Eden 会被清空,Eden 区中绝大部分对象会被回收,而那些无需回收的存活对象,将会进到 Survivor 的 From 区(若 From 区不够,则直接进入 Old 区)。
Survivor 区相当于是 Eden 区和 Old 区的一个缓冲,类似于我们交通灯中的黄灯。Survivor 又分为 2 个区,一个是 From 区,一个是 To 区。每次执行 Minor GC,会将 Eden 区和 From 存活的对象放到 Survivor 的 To 区(如果 To 区不够,则直接进入 Old 区)。
之所以有 Survivor 区是因为如果没有 Survivor 区,Eden 区每进行一次 Minor GC,存活的对象就会被送到老年代,老年代很快就会被填满。而有很多对象虽然一次 Minor GC 没有消灭,但其实也并不会蹦跶多久,或许第二次,第三次就需要被清除。这时候移入老年区,很明显不是一个明智的决定。
所以,Survivor 的存在意义就是减少被送到老年代的对象,进而减少 Major GC 的发生。Survivor 的预筛选保证,只有经历 16 次 Minor GC 还能在新生代中存活的对象,才会被送到老年代。
设置两个 Survivor 区最大的好处就是解决内存碎片化。
我们先假设一下,Survivor 如果只有一个区域会怎样。Minor GC 执行后,Eden 区被清空了,存活的对象放到了 Survivor 区,而之前 Survivor 区中的对象,可能也有一些是需要被清除的。问题来了,这时候我们怎么清除它们?在这种场景下,我们只能标记清除,而我们知道标记清除最大的问题就是内存碎片,在新生代这种经常会消亡的区域,采用标记清除必然会让内存产生严重的碎片化。因为 Survivor 有 2 个区域,所以每次 Minor GC,会将之前 Eden 区和 From 区中的存活对象复制到 To 区域。第二次 Minor GC 时,From 与 To 职责互换,这时候会将 Eden 区和 To 区中的存活对象再复制到 From 区域,以此反复。
这种机制最大的好处就是,整个过程中,永远有一个 Survivor space 是空的,另一个非空的 Survivor space 是无碎片的。那么,Survivor 为什么不分更多块呢?比方说分成三个、四个、五个?显然,如果 Survivor 区再细分下去,每一块的空间就会比较小,容易导致 Survivor 区满,两块 Survivor 区可能是经过权衡之后的最佳方案。
老年代占据着 2/3 的堆内存空间,只有在 Major GC 的时候才会进行清理,每次 GC 都会触发“Stop-The-World”。内存越大,STW 的时间也越长,所以内存也不仅仅是越大就越好。在内存担保机制下,无法安置的对象会直接进到老年代,以下几种情况也会进入老年代。
1)大对象,指需要大量连续内存空间的对象,这部分对象不管是不是“朝生夕死”,都会直接进到老年代。这样做主要是为了避免在 Eden 区及 2 个 Survivor 区之间发生大量的内存复制。
2)长期存活对象,虚拟机给每个对象定义了一个对象年龄(Age)计数器。正常情况下对象会不断的在 Survivor 的 From 区与 To 区之间移动,对象在 Survivor 区中每经历一次 Minor GC,年龄就增加 1 岁。当年龄增加到 15 岁时,这时候就会被转移到老年代。当然,这里的 15,JVM 也支持进行特殊设置。
3)动态对象年龄,虚拟机并不重视要求对象年龄必须到 15 岁,才会放入老年区,如果 Survivor 空间中相同年龄所有对象大小的总合大于 Survivor 空间的一半,年龄大于等于该年龄的对象就可以直接进去老年区,无需等你“成年”。
这其实有点类似于负载均衡,轮询是负载均衡的一种,保证每台机器都分得同样的请求。看似很均衡,但每台机的硬件不通,健康状况不同,我们还可以基于每台机接受的请求数,或每台机的响应时间等,来调整我们的负载均衡算法。
5、Java反射
大白话说Java反射:入门、使用、原理 - 陈树义 - 博客园
6、== 和 equals的区别 √
对于基本类型和引用类型 == 的作用效果是不同的,如下所示:
基本类型:比较的是值是否相同;
引用类型:比较的是引用是否相同;
代码示例:
String x = "string";
String y = "string";
String z = new String("string");
System.out.println(x==y); // true
System.out.println(x==z); // false
System.out.println(x.equals(y)); // true
System.out.println(x.equals(z)); // true代码解读:因为 x 和 y 指向的是同一个引用,所以 == 也是 true,而 new String()方法则重写开辟了内存空间,所以 == 结果为 false,而 equals 比较的一直是值,所以结果都为 true。
equals 解读
equals 本质上就是 ==,只不过 String 和 Integer 等重写了 equals 方法,把它变成了值比较。看下面的代码就明白了。
首先来看默认情况下 equals 比较一个有相同值的对象,代码如下:
class Cat {
public Cat(String name) {
this.name = name;
}
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
Cat c1 = new Cat("王磊");
Cat c2 = new Cat("王磊");
System.out.println(c1.equals(c2)); // false
输出结果出乎我们的意料,竟然是 false?这是怎么回事,看了 equals 源码就知道了,源码如下:
public boolean equals(Object obj) {
return (this == obj);
}
原来 equals 本质上就是 ==。
那问题来了,两个相同值的 String 对象,为什么返回的是 true?代码如下:
String s1 = new String("老王");
String s2 = new String("老王");
System.out.println(s1.equals(s2)); // true
同样的,当我们进入 String 的 equals 方法,找到了答案,代码如下:
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
原来是 String 重写了 Object 的 equals 方法,把引用比较改成了值比较。
总结 :== 对于基本类型来说是值比较,对于引用类型来说是比较的是引用;而 equals 默认情况下是引用比较,只是很多类重新了 equals 方法,比如 String、Integer 等把它变成了值比较,所以一般情况下 equals 比较的是值是否相等。
7、重载和重写的区别,它们的编译方式 √
重写(Override)
重写(Override)是指子类定义了一个与其父类中具有相同名称、参数列表和返回类型的方法,并且子类方法的实现覆盖了父类方法的实现。 即外壳不变,核心重写!
重写的好处在于子类可以根据需要,定义特定于自己的行为。也就是说子类能够根据需要实现父类的方法。这样,在使用子类对象调用该方法时,将执行子类中的方法而不是父类中的方法。
重写方法不能抛出新的检查异常或者比被重写方法申明更加宽泛的异常。例如: 父类的一个方法申明了一个检查异常 IOException,但是在重写这个方法的时候不能抛出 Exception 异常,因为 Exception 是 IOException 的父类,抛出 IOException 异常或者 IOException 的子类异常。
在面向对象原则里,重写意味着可以重写任何现有方法。实例如下:
TestDog.java 文件代码:
class Animal{
public void move(){
System.out.println("动物可以移动");
}
}
class Dog extends Animal{
public void move(){
System.out.println("狗可以跑和走");
}
}
public class TestDog{
public static void main(String args[]){
Animal a = new Animal(); // Animal 对象
Animal b = new Dog(); // Dog 对象
a.move();// 执行 Animal 类的方法
b.move();//执行 Dog 类的方法
}
}以上实例编译运行结果如下:
动物可以移动
狗可以跑和走
在上面的例子中可以看到,尽管 b 属于 Animal 类型,但是它运行的是 Dog 类的 move方法。
这是由于在编译阶段,只是检查参数的引用类型。
然而在运行时,Java 虚拟机(JVM)指定对象的类型并且运行该对象的方法。
因此在上面的例子中,之所以能编译成功,是因为 Animal 类中存在 move 方法,然而运行时,运行的是特定对象的方法。
思考以下例子:
TestDog.java 文件代码:
class Animal{
public void move(){
System.out.println("动物可以移动");
}
}
class Dog extends Animal{
public void move(){
System.out.println("狗可以跑和走");
}
public void bark(){
System.out.println("狗可以吠叫");
}
}
public class TestDog{
public static void main(String args[]){
Animal a = new Animal(); // Animal 对象
Animal b = new Dog(); // Dog 对象
a.move();// 执行 Animal 类的方法
b.move();//执行 Dog 类的方法
b.bark();
}
}以上实例编译运行结果如下:
TestDog.java:30: cannot find symbol
symbol : method bark()
location: class Animal
b.bark();
^
方法的重写规则
-
参数列表与被重写方法的参数列表必须完全相同。
-
返回类型与被重写方法的返回类型可以不相同,但是必须是父类返回值的派生类(java5 及更早版本返回类型要一样,java7 及更高版本可以不同)。
-
访问权限不能比父类中被重写的方法的访问权限更低。例如:如果父类的一个方法被声明为 public,那么在子类中重写该方法就不能声明为 protected。
-
父类的成员方法只能被它的子类重写。
-
声明为 final 的方法不能被重写。
-
声明为 static 的方法不能被重写,但是能够被再次声明。
-
子类和父类在同一个包中,那么子类可以重写父类所有方法,除了声明为 private 和 final 的方法。
-
子类和父类不在同一个包中,那么子类只能够重写父类的声明为 public 和 protected 的非 final 方法。
-
重写的方法能够抛出任何非强制异常,无论被重写的方法是否抛出异常。但是,重写的方法不能抛出新的强制性异常,或者比被重写方法声明的更广泛的强制性异常,反之则可以。
-
构造方法不能被重写。
-
如果不能继承一个类,则不能重写该类的方法。
Super 关键字的使用
当需要在子类中调用父类的被重写方法时,要使用 super 关键字。
TestDog.java 文件代码:
class Animal{
public void move(){
System.out.println("动物可以移动");
}
}
class Dog extends Animal{
public void move(){
super.move(); // 应用super类的方法
System.out.println("狗可以跑和走");
}
}
public class TestDog{
public static void main(String args[]){
Animal b = new Dog(); // Dog 对象
b.move(); //执行 Dog类的方法
}
}重载(Overload)
重载(overloading) 是在一个类里面,方法名字相同,而参数不同。返回类型可以相同也可以不同。
每个重载的方法(或者构造函数)都必须有一个独一无二的参数类型列表。
最常用的地方就是构造器的重载。
重载规则:
-
被重载的方法必须改变参数列表(参数个数或类型不一样);
-
被重载的方法可以改变返回类型;
-
被重载的方法可以改变访问修饰符;
-
被重载的方法可以声明新的或更广的检查异常;
-
方法能够在同一个类中或者在一个子类中被重载。
-
无法以返回值类型作为重载函数的区分标准。
实例
Overloading.java 文件代码:
public class Overloading {
public int test(){
System.out.println("test1");
return 1;
}
public void test(int a){
System.out.println("test2");
}
//以下两个参数类型顺序不同
public String test(int a,String s){
System.out.println("test3");
return "returntest3";
}
public String test(String s,int a){
System.out.println("test4");
return "returntest4";
}
public static void main(String[] args){
Overloading o = new Overloading();
System.out.println(o.test());
o.test(1);
System.out.println(o.test(1,"test3"));
System.out.println(o.test("test4",1));
}
}重写与重载之间的区别
| 区别点 | 重载方法 | 重写方法 |
|---|---|---|
| 参数列表 | 必须修改 | 一定不能修改 |
| 返回类型 | 可以修改 | 一定不能修改 |
| 异常 | 可以修改 | 可以减少或删除,一定不能抛出新的或者更广的异常 |
| 访问 | 可以修改 | 一定不能做更严格的限制(可以降低限制) |
总结
方法的重写(Overriding)和重载(Overloading)是java多态性的不同表现,重写是父类与子类之间多态性的一种表现,重载可以理解成多态的具体表现形式。
-
(1)方法重载是一个类中定义了多个方法名相同,而他们的参数的数量不同或数量相同而类型和次序不同,则称为方法的重载(Overloading)。
-
(2)方法重写是在子类存在方法与父类的方法的名字相同,而且参数的个数与类型一样,返回值也一样的方法,就称为重写(Overriding)。
-
(3)方法重载是一个类的多态性表现,而方法重写是子类与父类的一种多态性表现。

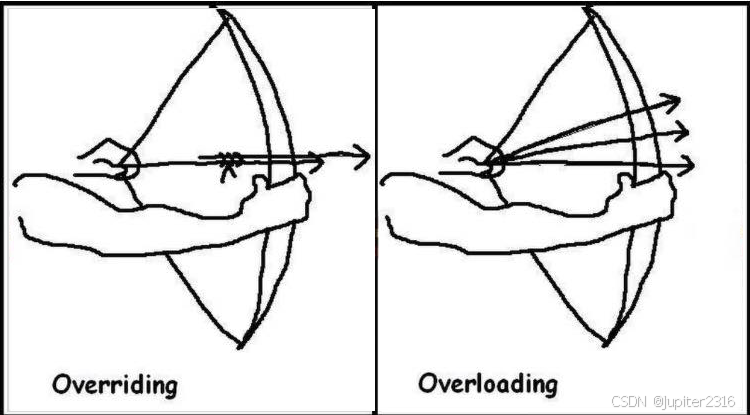
8、数组和链表的区别 √
数组定义:是有序的元素序列,若将有限个类型相同的变量的集合命名,那么这个名称为数组。
java中初始化一个int类型数组int[] temp=new int[8];表示初始化一个数组里面都放int类型的值,数组长度是8。

数组是一组有序的元素的集合,那么在内存分配上,数组必须先分配一段连续的内存地址。你想象成数组就像一个连续从0标号的的台阶。
你要知道哪个台阶上放的东西,你只需要知道这个台阶的下标号,直接去这个标号的台阶上取东西就行了。
你不需要知道其他台阶上的标号和东西,也不用从第一个台阶往上依次找。
数组之间是通过下标维护的,数组支持随机查找。
比如你要找index是7的值,只需要通过数组的下标找到index是7就能找到对应的值。
如图下标是7的值是90,那么就是temp[7]=90;所以数组的查询速度很快是O(1)的时间复杂度。

说完查找,那么数组的新增和修改是怎么样的呢?
你现在有个需求需要在楼梯index是2和3的地方加一层台阶,你怎么办?
那么只有把index是3以后的台阶都往后挪动一位,将原来长度是8的台阶变成长度是9的台阶。
如图红色的是加的index为3的台阶,后面颜色变深的是index:3,4,5,6,7的台阶index+1向后移动一位的结果变成index:4,5,6,7,8的台阶。
台阶的内容不变,红色前面的是index是3的值之前index:1,2的台阶和之前一样index和值没有任何变化。
最坏的结果在数组最前面加一层台阶整个台阶(数组)都要往后移动一阶,时间复杂度是O(n)。
最好的情况是在数组最后加一阶那么直接将数组长度+1,时间复杂度是O(1)。那么总的来说数组的新增修改需要移动数组效率较低。

数组删除元素,如果你现在需要把上面3加的index值是3的台阶删掉。
那么需要将index是3之后的index和值往前移动一位,就是将index是:4,5,6,7,8的值-1变成:3,4,5,6,7。
如图:和新增一样最坏的情况是删除第一个index是1的值,index为1的值之后的所有元素都要往前移动一位,时间复杂度O(n)。
最好的情况删除最后一个元素不用移动数组,时间复杂度O(1)。

数组如果申请的空间长度不够,扩展的时候会重新申请一段连续的内存空间不利于扩展。
链表:是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。

图示的是单链表,现只讨论单链表的数据结构。
那么链表在内存的分配上是怎样的呢,数组是连续的内存,那么链表申请内存的时候就不需要预先申请连续的内存。
在内存分配上链表物理地址就不连续,那么在两个不连续的物理内存存储的链表的内容通过next指针连接成一条链依次去查找。
有点按图索骥的意思。
就好像一个猜纸条的游戏,你拿到第一个纸条,需要打开看到这个纸条给你留的下个纸条的地址在哪。
你才能根据第一个纸条内容找到第二个纸条。
如果要找到第三个纸条,你必须依次打开第一个纸条找到第二个纸条,再根据第二个纸条的提示找到第三个纸条。
你不能随机的一下找到第三个纸条,那么查找的效率上链表效率低,最坏的情况从头找到尾时间复杂度是O(n)。
链表新增,数组的新增需要移动元素位置,那么链表如果需要新增怎么办?
是不是需要移动元素的位置?
回答:不需要移动位置,只需要改变这个你加入的位置的前面指针的指向,让前面的指针指向你新加的元素。
让新加的元素指向原指向你指针的下一个元素。只需要改变指针的指向,不需要移动元素效率高,时间复杂度O(1)。
原链表:

新增元素

链表删除,链表的删除只需要把上文指向新加的节点的指针变成指向原节点就好,时间复杂度O(1)。如图正好和新增相反的过程。
原链表

删除元素

总结
数组:查询效率高,新增和修改需要移动元素效率低,内存分配是连续的内存,扩容需要重新分配内存。
链表:新增和修改效率高,只需要修改指针指向就好。链表查询效率低,需要从链表头依次查找。内存分配不需要连续的内存,占用连续内存少。
9、String和StringBuffer、StringBuider的区别 √
在 Java 中字符串属于对象,Java 提供了 String 类来创建和操作字符串。String 类是不可变类,即一旦一个 String 对象被创建以后,包含在这个对象中的字符序列是不可改变的,直至这个对象被销毁。
Java 提供了两个可变字符串类 StringBuffer 和 StringBuilder,中文翻译为“字符串缓冲区”。
StringBuilder 类是 JDK 1.5 新增的类,它也代表可变字符串对象。实际上,StringBuilder 和 StringBuffer 功能基本相似,方法也差不多。不同的是,StringBuffer 是线程安全的,而 StringBuilder 则没有实现线程安全功能,所以性能略高。因此在通常情况下,如果需要创建一个内容可变的字符串对象,则应该优先考虑使用 StringBuilder 类。
StringBuffer、StringBuilder、String 中都实现了 CharSequence 接口。CharSequence 是一个定义字符串操作的接口,它只包括 length()、charAt(int index)、subSequence(int start, int end) 这几个 API。
StringBuffer、StringBuilder、String 对 CharSequence 接口的实现过程不一样,如下图所示:
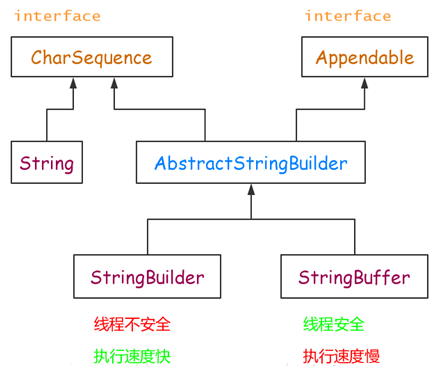
可见,String 直接实现了 CharSequence 接口,StringBuilder 和 StringBuffer 都是可变的字符序列,它们都继承于 AbstractStringBuilder,实现了 CharSequence 接口。
总结
String 是 Java 中基础且重要的类,被声明为 final class,是不可变字符串。因为它的不可变性,所以拼接字符串时候会产生很多无用的中间对象,如果频繁的进行这样的操作对性能有所影响。
StringBuffer 就是为了解决大量拼接字符串时产生很多中间对象问题而提供的一个类。它提供了 append 和 add 方法,可以将字符串添加到已有序列的末尾或指定位置,它的本质是一个线程安全的可修改的字符序列。
在很多情况下我们的字符串拼接操作不需要线程安全,所以 StringBuilder 登场了。StringBuilder 是 JDK1.5 发布的,它和 StringBuffer 本质上没什么区别,就是去掉了保证线程安全的那部分,减少了开销。
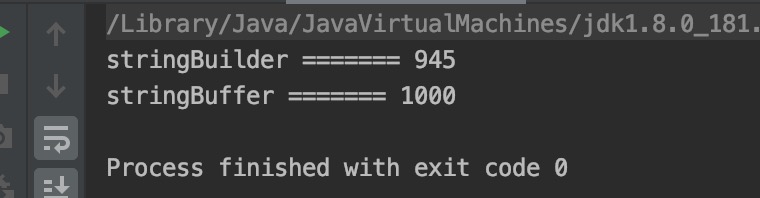
线程安全:
StringBuffer:线程安全
StringBuilder:线程不安全
验证代码如下:
/**
* 验证StringBuffer线程安全,StringBuilder线程不安全
*/
public static void testStringBuilderAndStringBuffer() {
//证明StringBuffer线程安全,StringBuilder线程不安全
StringBuffer stringBuffer = new StringBuffer();
StringBuilder stringBuilder = new StringBuilder();
// 计数器
CountDownLatch latch1 = new CountDownLatch(1000);
CountDownLatch latch2 = new CountDownLatch(1000);
for (int i = 0; i < 1000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(50);
stringBuilder.append(1);
} catch (Exception e) {
e.printStackTrace();
} finally {
latch1.countDown();
}
}
}).start();
}
for (int i = 0; i < 1000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(50);
stringBuffer.append(1);
} catch (Exception e) {
e.printStackTrace();
} finally {
latch2.countDown();
}
}
}).start();
}
try {
latch1.await();
System.out.println("stringBuilder ======= " + stringBuilder.length());
latch2.await();
System.out.println("stringBuffer ======= " + stringBuffer.length());
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}结果如下:
速度:
一般情况下,速度从快到慢为 StringBuilder > StringBuffer > String,当然这是相对的,不是绝对的。
使用环境:
操作少量的数据使用 String。
单线程操作大量数据使用 StringBuilder。
多线程操作大量数据使用 StringBuffer。
10、类加载机制,对象实例化的过程 √
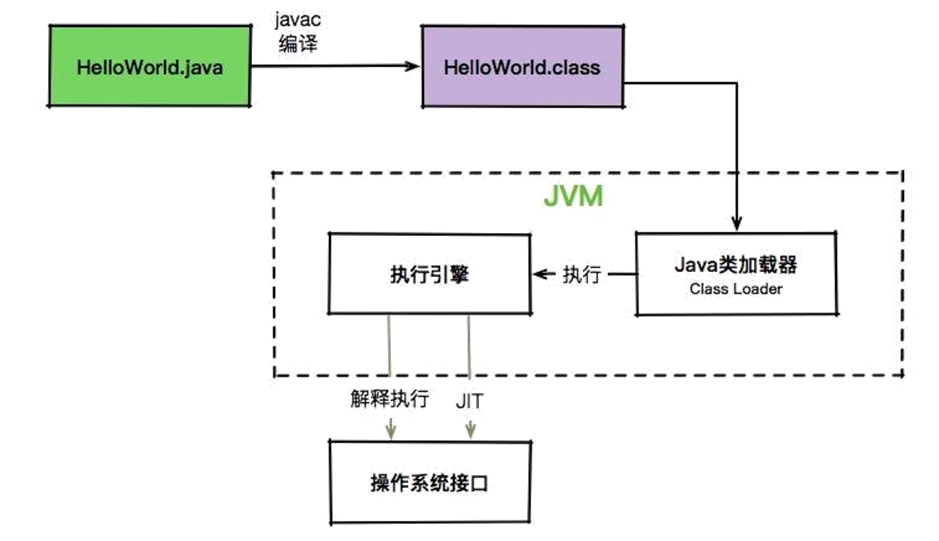
JVM 需要将编译后的字节码文件加载到其内部的运行时数据区域中进行执行。这个过程涉及到了 Java 的类加载机制(面试常问的知识点)。
这里再给大家普及一个小技巧,可以通过 xxd 命令来查看字节码文件,先看下面这段代码。
public class Test {
public static void main(String[] args) {
System.out.println("沉默王二");
}
}代码编译通过后,在命令行执行 xxd Test.class(macOS 用户可以直接执行,Windows 用户可以戳这个链接获取替代品)就可以快速查看字节码的十六进制内容。
xxd 是一个用于在终端中创建十六进制转储(hex dump)或将十六进制转回二进制的工具。可通过维基百科了解更多信息。
00000000: cafe babe 0000 0034 0022 0700 0201 0019 .......4."......
00000010: 636f 6d2f 636d 6f77 6572 2f6a 6176 615f com/cmower/java_
00000020: 6465 6d6f 2f54 6573 7407 0004 0100 106a demo/Test......j
00000030: 6176 612f 6c61 6e67 2f4f 626a 6563 7401 ava/lang/Object.
00000040: 0006 3c69 6e69 743e 0100 0328 2956 0100 ..<init>...()V..
00000050: 0443 6f64 650a 0003 0009 0c00 0500 0601 .Code...........
00000060: 000f 4c69 6e65 4e75 6d62 6572 5461 626c ..LineNumberTabl这里只说一点,这段字节码中的 cafe babe 被称为“魔数”,是 JVM 识别 .class 文件(字节码文件)的标志,相信大家都知道,Java 的 logo 是一杯冒着热气的咖啡,是不是又关联上了?

文件格式的定制者可以自由选择魔数值(只要没用过),比如说 .png 文件的魔数是
8950 4e47。
至于字节码文件中的其他内容,暂时先不用去管,我们后面会详细讲解。
知道什么是 Java 字节码后,我们来聊聊 Java 的类加载过程。
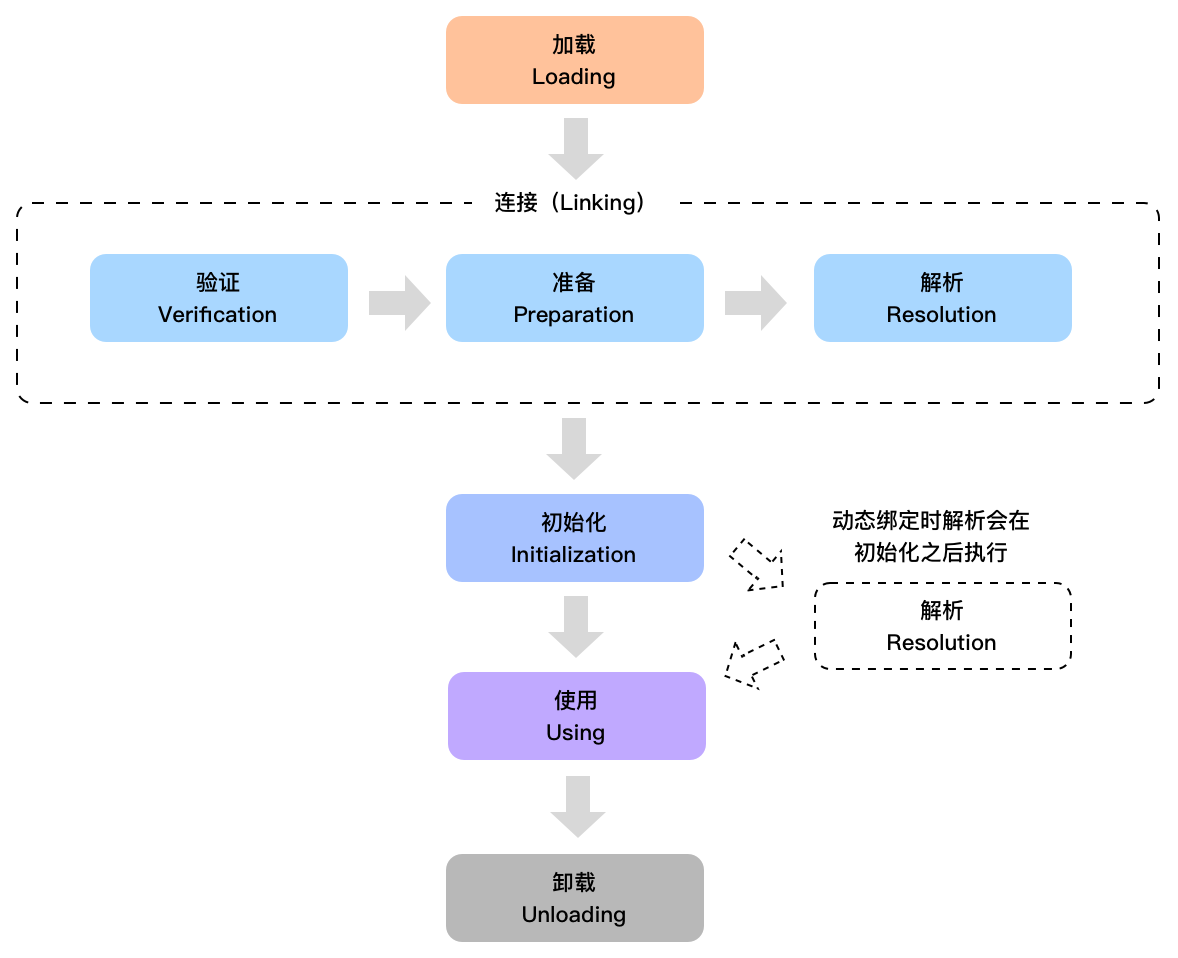
类从被加载到 JVM 开始,到卸载出内存,整个生命周期分为七个阶段,分别是加载、验证、准备、解析、初始化、使用和卸载。其中验证、准备和解析这三个阶段统称为连接。
除去使用和卸载,就是 Java 的类加载过程。这 5 个阶段一般是顺序发生的,但在动态绑定的情况下,解析阶段发生在初始化阶段之后(我们随后来解释)。
JVM 在该阶段的目的是将字节码从不同的数据源(可能是 class 文件、也可能是 jar 包,甚至网络)转化为二进制字节流加载到内存中,并生成一个代表该类的 java.lang.Class 对象(在学反射的时候有讲过)。
JVM 会在该阶段对二进制字节流进行校验,只有符合 JVM 字节码规范的才能被 JVM 正确执行。该阶段是保证 JVM 安全的重要屏障,下面是一些主要的检查。
-
确保二进制字节流格式符合预期(比如说是否以
cafe bene开头,前面提到过)。 -
是否所有方法都遵守访问控制关键字的限定,protected、private 那些。
-
方法调用的参数个数和类型是否正确。
-
确保变量在使用之前被正确初始化了。
-
检查变量是否被赋予恰当类型的值。
-
还有更多。
JVM 会在该阶段对类变量(也称为静态变量,static 关键字修饰的)分配内存并初始化,对应数据类型的默认初始值,如 0、0L、null、false 等。
也就是说,假如有这样一段代码:
public String chenmo = "沉默";
public static String wanger = "王二";
public static final String cmower = "沉默王二";chenmo 不会被分配内存,而 wanger 会;但 wanger 的初始值不是“王二”而是 null。
需要注意的是,static final 修饰的变量被称作为常量,和类变量不同(这些在讲 static 关键字就讲过了)。常量一旦赋值就不会改变了,所以 cmower 在准备阶段的值为“沉默王二”而不是 null。
该阶段将常量池中的符号引用转化为直接引用。
what?符号引用,直接引用?
符号引用以一组符号(任何形式的字面量,只要在使用时能够无歧义的定位到目标即可)来描述所引用的目标。
在编译时,Java 类并不知道所引用的类的实际地址,因此只能使用符号引用来代替。比如 com.Wanger 类引用了 com.Chenmo 类,编译时 Wanger 类并不知道 Chenmo 类的实际内存地址,因此只能使用符号 com.Chenmo。
直接引用通过对符号引用进行解析,找到引用的实际内存地址。我们再来对比说明一下。
符号引用
-
定义:包含了类、字段、方法、接口等多种符号的全限定名。
-
特点:在编译时生成,存储在编译后的字节码文件的常量池中。
-
独立性:不依赖于具体的内存地址,提供了更好的灵活性。
直接引用
-
定义:直接指向目标的指针、相对偏移量或者能间接定位到目标的句柄。
-
特点:在运行时生成,依赖于具体的内存布局。
-
效率:由于直接指向了内存地址或者偏移量,所以通过直接引用访问对象的效率较高。
下面通过一张简化的图来描述它们的区别:
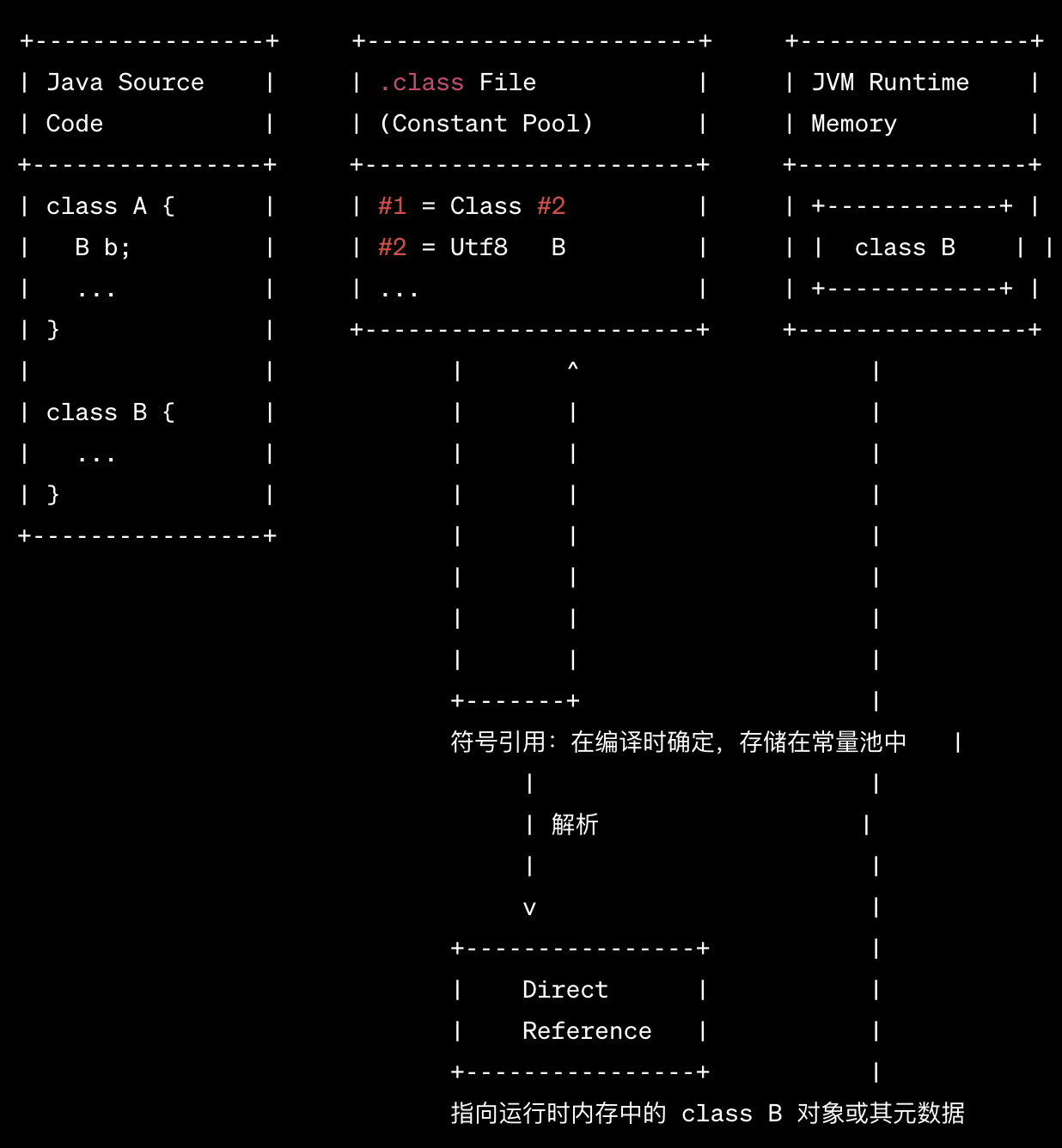
在上面的例子中:
-
class A引用了class B。 -
在编译时,这个引用变成了符号引用,存储在
.class文件的常量池中。 -
在运行时,当
class A需要使用class B的时候,JVM 会将符号引用解析为直接引用,指向内存中的class B对象或其元数据。
通过这种方式,Java 程序能够在编译时和运行时具有更高的灵活性和解耦性,同时在运行时也能获得更好的性能。
Java 本身是一个静态语言,但后面又加入了动态加载特性,因此我们理解解析阶段需要从这两方面来考虑。
如果不涉及动态加载,那么一个符号的解析结果是可以缓存的,这样可以避免多次解析同一个符号,因为第一次解析成功后面多次解析也必然成功,第一次解析异常后面重新解析也会是同样的结果。
如果使用了动态加载,前面使用动态加载解析过的符号后面重新解析结果可能会不同。使用动态加载时解析过程发生在在程序执行到这条指令的时候,这就是为什么前面讲的动态加载时解析会在初始化后执行。
整个解析阶段主要做了下面几个工作:
-
类或接口的解析
-
类方法解析
-
接口方法解析
-
字段解析
该阶段是类加载过程的最后一步。在准备阶段,类变量已经被赋过默认初始值,而在初始化阶段,类变量将被赋值为代码期望赋的值。换句话说,初始化阶段是执行类构造器方法(javap 中看到的 <clinit>() 方法)的过程。
上面这段话可能说得很抽象,不好理解,我来举个例子。
String cmower = new String("沉默王二");上面这段代码使用了 new 关键字来实例化一个字符串对象,那么这时候,就会调用 String 类的构造方法对 cmower 进行实例化。
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}初始化时机包括以下这些:
-
创建类的实例时。
-
访问类的静态方法或静态字段时(除了 final 常量,它们在编译期就已经放入常量池)。
-
使用 java.lang.reflect 包的方法对类进行反射调用时。
-
初始化一个类的子类(首先会初始化父类)。
-
JVM 启动时,用户指定的主类(包含 main 方法的类)将被初始化。
聊完类加载过程,就不得不聊聊类加载器。
一般来说,Java 程序员并不需要直接同类加载器进行交互。JVM 默认的行为就已经足够满足大多数情况的需求了。不过,如果遇到了需要和类加载器进行交互的情况,而对类加载器的机制又不是很了解的话,就不得不花大量的时间去调试 ClassNotFoundException 和 NoClassDefFoundError 等异常(前面讲过)。
对于任意一个类,都需要由它的类加载器和这个类本身一同确定其在 JVM 中的唯一性。也就是说,如果两个类的加载器不同,即使两个类来源于同一个字节码文件,那这两个类就必定不相等(比如两个类的 Class 对象不 equals)。
来通过一段简单的代码了解下。
/**
* @author 微信搜「沉默王二」,回复关键字 PDF
*/
public class Test {
public static void main(String[] args) {
ClassLoader loader = Test.class.getClassLoader();
while (loader != null) {
System.out.println(loader);
loader = loader.getParent();
}
}
}每个 Java 类都维护着一个指向定义它的类加载器的引用,通过 类名.class.getClassLoader() 可以获取到此引用;然后通过 loader.getParent() 可以获取类加载器的上层类加载器。
上面这段代码的输出结果如下:
jdk.internal.loader.ClassLoaders$AppClassLoader@512ddf17
jdk.internal.loader.ClassLoaders$PlatformClassLoader@2d209079第一行输出为 Test 的类加载器,即应用类加载器,它是 jdk.internal.loader.ClassLoaders$AppClassLoader 类的实例;第二行输出为平台类加载器,是 jdk.internal.loader.ClassLoaders$PlatformClassLoader 类的实例。那启动类加载器呢?
按理说,扩展类加载器的上层类加载器是启动类加载器,但启动类加载器是虚拟机的内置类加载器,通常表示为 null。
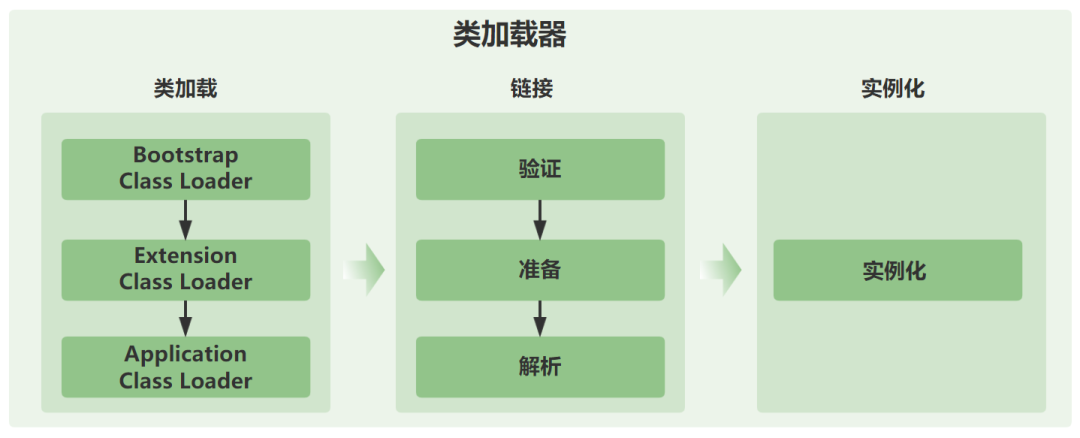
也就是说,类加载器可以分为四种类型:
①、引导类加载器(Bootstrap ClassLoader):负责加载 JVM 基础核心类库,如 rt.jar、sun.boot.class.path 路径下的类。
②、扩展类加载器(Extension ClassLoader):负责加载 Java 扩展库中的类,例如 jre/lib/ext 目录下的类或由系统属性 java.ext.dirs 指定位置的类。
③、系统(应用)类加载器(System ClassLoader):负责加载系统类路径 java.class.path 上指定的类库,通常是你的应用类和第三方库。
④、用户自定义类加载器:Java 允许用户创建自己的类加载器,通过继承 java.lang.ClassLoader 类的方式实现。这在需要动态加载资源、实现模块化框架或者特殊的类加载策略时非常有用。
import java.io.*;
public class CustomClassLoader extends ClassLoader {
private String pathToBin;
public CustomClassLoader(String pathToBin) {
this.pathToBin = pathToBin;
}
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
try {
byte[] classData = loadClassData(name);
return defineClass(name, classData, 0, classData.length);
} catch (IOException e) {
throw new ClassNotFoundException("Class " + name + " not found", e);
}
}
private byte[] loadClassData(String name) throws IOException {
String file = pathToBin + name.replace('.', File.separatorChar) + ".class";
InputStream is = new FileInputStream(file);
ByteArrayOutputStream byteSt = new ByteArrayOutputStream();
int len = 0;
while ((len = is.read()) != -1) {
byteSt.write(len);
}
return byteSt.toByteArray();
}
}这个自定义类加载器做了以下几件事情:
-
构造器:接受一个字符串参数,这个字符串指定了类文件的存放路径。
-
覆写 findClass 方法:当父类加载器无法加载类时,findClass 方法会被调用。在这个方法中,首先使用 loadClassData 方法读取类文件的字节码,然后调用 defineClass 方法来将这些字节码转换为 Class 对象。
-
loadClassData 方法:读取指定路径下的类文件内容,并将内容作为字节数组返回。
双亲委派模型(Parent Delegation Model)是 Java 类加载器使用的一种机制,用于确保 Java 程序的稳定性和安全性。在这个模型中,类加载器在尝试加载一个类时,首先会委派给其父加载器去尝试加载这个类,只有在父加载器无法加载该类时,子加载器才会尝试自己去加载。
-
委派给父加载器:当一个类加载器接收到类加载的请求时,它首先不会尝试自己去加载这个类,而是将这个请求委派给它的父加载器。
-
递归委派:这个过程会递归向上进行,从启动类加载器(Bootstrap ClassLoader)开始,再到扩展类加载器(Extension ClassLoader),最后到系统类加载器(System ClassLoader)。
-
加载类:如果父加载器可以加载这个类,那么就使用父加载器的结果。如果父加载器无法加载这个类(它没有找到这个类),子加载器才会尝试自己去加载。
-
安全性和避免重复加载:这种机制可以确保不会重复加载类,并保护 Java 核心 API 的类不被恶意替换。
类加载器的层级结构如下图所示:
Bootstrap ClassLoader
↑
│
Extension ClassLoader
↑
│
System/Application ClassLoader
↑
│
Custom ClassLoader这种层次关系被称作为双亲委派模型:如果一个类加载器收到了加载类的请求,它会先把请求委托给上层加载器去完成,上层加载器又会委托上上层加载器,一直到最顶层的类加载器;如果上层加载器无法完成类的加载工作时,当前类加载器才会尝试自己去加载这个类。
PS:双亲委派模型突然让我联想到朱元璋同志,这个同志当上了皇帝之后连宰相都不要了,所有的事情都亲力亲为,只有自己没精力没时间做的事才交给大臣们去干。
使用双亲委派模型有一个很明显的好处,那就是 Java 类随着它的类加载器一起具备了一种带有优先级的层次关系,这对于保证 Java 程序的稳定运作很重要。
上文中曾提到,如果两个类的加载器不同,即使两个类来源于同一个字节码文件,那这两个类就必定不相等——双亲委派模型能够保证同一个类最终会被特定的类加载器加载。
Java 的类加载机制通过类加载器和类加载过程的合作,确保了 Java 程序的动态加载、灵活性和安全性。双亲委派模型进一步增强了这种机制的安全性和类之间的协调性。
11、jdk1.7和1.8的区别
Jdk1.7 与 jdk1.8的区别,最新的特征有哪些(美团,360,京东面试题目) - aspirant - 博客园
12、内存溢出的场景 √
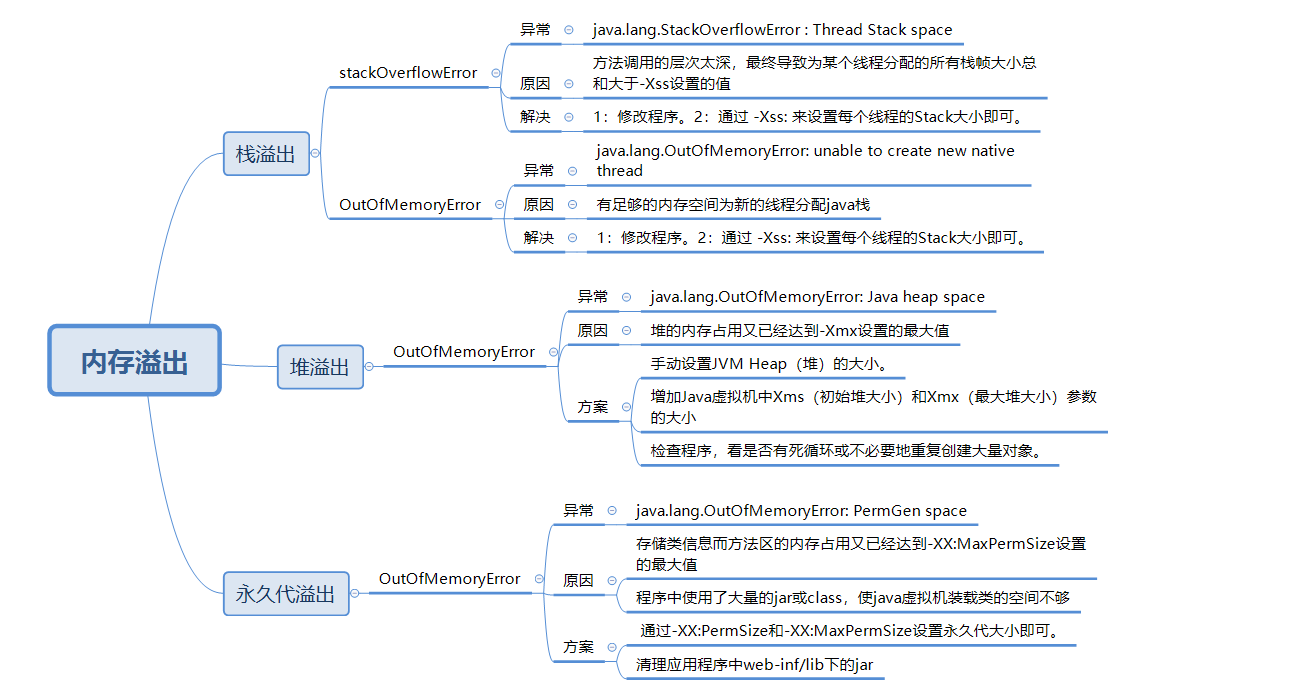
Java内存溢出即程序在申请内存时,没有足够的空间供其使用,出现out of memory。
常见于四种情况:
1、栈溢出(StackOverflowError)、
2、堆溢出(OutOfMemoryError:java heap space)、
3、永久代溢出(OutOfMemoryError: PermGen space)、
4、OutOfMemoryError:unable to create native thread,以下一一进行总结。
一、栈溢出 (java.lang.StackOverflowError : Thread Stack space)
java栈空间是线程私有的,是java方法执行的内存模型。每个方法执行时都会在java栈空间产生一个栈帧,存放方法的变量表,返回值等信息,方法的执行到结束就是一个栈帧入栈到出栈的过程。
栈溢出了,JVM依然是采用栈式的虚拟机,这个和C和Pascal都是一样的。函数的调用过程都体现在堆栈和退栈上了。调用构造函数的 “层”太多了,以致于把栈区溢出了。 通常来讲,一般栈区远远小于堆区的,因为函数调用过程往往不会多于上千层,而即便每个函数调用需要 1K的空间(这个大约相当于在一个C函数内声明了256个int类型的变量),那么栈区也不过是需要1MB的空间。通常栈的大小是1-2MB的。通俗一点讲就是单线程的程序需要的内存太大了。 通常递归也不要递归的层次过多,很容易溢出。
解决方法:1:修改程序。2:通过 -Xss: 来设置每个线程的Stack大小即可。
在Java虚拟机规范中,对这个区域规定了两种异常状况:StackOverflowError和OutOfMemoryError异常。
(1)StackOverflowError异常
stackOverFlowError 顾名思义 就是 栈溢出
每当java程序代码启动一个新线程时,Java虚拟机都会为它分配一个Java栈。Java栈以帧为单位保存线程的运行状态。当线程调用java方法时,虚拟机压入一个新的栈帧到该线程的java栈中。只要这个方法还没有返回,它就一直存在。如果线程的方法嵌套调用层次太多(如递归调用),随着java栈中帧的逐渐增多,最终会由于该线程java栈中所有栈帧大小总和大于-Xss设置的值,而产生StackOverflowError内存溢出异常。例子如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
-Xss为128k。其中的一次测试结果为,当count的值累加到2230时,发生如下异常:

Exception in thread "main" java.lang.StackOverflowError
at sun.nio.cs.UTF_8.updatePositions(UTF_8.java:77)
at sun.nio.cs.UTF_8$Encoder.encodeArrayLoop(UTF_8.java:564)
at sun.nio.cs.UTF_8$Encoder.encodeLoop(UTF_8.java:619)
at java.nio.charset.CharsetEncoder.encode(CharsetEncoder.java:561)
at sun.nio.cs.StreamEncoder.implWrite(StreamEncoder.java:271)
at sun.nio.cs.StreamEncoder.write(StreamEncoder.java:125)
at java.io.OutputStreamWriter.write(OutputStreamWriter.java:207)
at java.io.BufferedWriter.flushBuffer(BufferedWriter.java:129)
at java.io.PrintStream.write(PrintStream.java:526)
at java.io.PrintStream.print(PrintStream.java:597)
at java.io.PrintStream.println(PrintStream.java:736)
at com.demo.test.JavaVMStackSOF.method(JavaVMStackSOF.java:15)

随着-Xss参数值的增大,可以嵌套的方法调用层次也相应增加。综上所述,StackOverflowError异常是由于方法调用的层次太深,最终导致为某个线程分配的所有栈帧大小总和大于-Xss设置的值,从而发生StackOverflowError异常
(2)OutOfMemoryError异常
java程序代码启动一个新线程时,没有足够的内存空间为该线程分配java栈(一个线程java栈的大小由-Xss参数确定),jvm则抛出OutOfMemoryError异常。例子如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
-Xss为128k。其中的一次测试结果为,当count的值累加到11958时,发生如下异常:
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:693)
at com.demo.test.JavaVMStackOOM.main(JavaVMStackOOM.java:21)
随着-Xss参数值的增大,java程序可以创建的总线程数越少。
二、JVM Heap(堆)溢出:java.lang.OutOfMemoryError: Java heap space
Heap的大小是 新生代(Young Generation) 和 老年代(Tenured Generaion) 之和。在JVM中如果98%的时间是用于GC,且可用的Heap size 不足2%的时候将抛出此异常信息。
JVM在启动的时候会自动设置JVM Heap的值, 可以利用JVM提供的-Xmn -Xms -Xmx等选项可进行设置。
解决方法:手动设置JVM Heap(堆)的大小。
Java堆用于储存对象实例。当需要为对象实例分配内存,而堆的内存占用又已经达到-Xmx设置的最大值。将会抛出OutOfMemoryError异常。例子如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
然后在运行时设置jvm参数,如下:
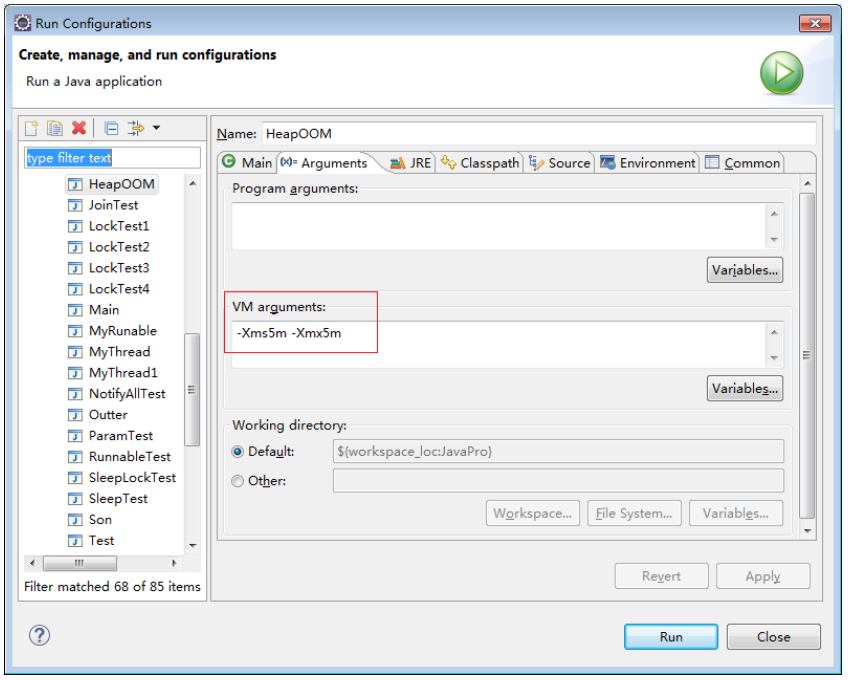
-Xmx为5m。其中的一次测试结果为,当count的值累加到360145时,发生如下异常:

Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:2245)
at java.util.Arrays.copyOf(Arrays.java:2219)
at java.util.ArrayList.grow(ArrayList.java:213)
at java.util.ArrayList.ensureCapacityInternal(ArrayList.java:187)
at java.util.ArrayList.add(ArrayList.java:411)
at com.demo.test.HeapOOM.main(HeapOOM.java:12)

修改-Xmx为10m。其中的一次测试结果为,当count的值累加到540217时,发生OutOfMemoryError异常。随着-Xmx参数值的增大,java堆中可以存储的对象也越多。
三、永久代溢出 ( PermGen space溢出: java.lang.OutOfMemoryError: PermGen space )
PermGen space的全称是Permanent Generation space,是指内存的永久保存区域。为什么会内存溢出,这是由于这块内存主要是被JVM存放Class和Meta信息的,Class在被Load的时候被放入PermGen space区域,它和存放Instance的Heap区域不同,sun的 GC不会在主程序运行期对PermGen space进行清理,所以如果你的APP会载入很多CLASS的话,就很可能出现PermGen space溢出。一般发生在程序的启动阶段。
解决方法: 通过-XX:PermSize和-XX:MaxPermSize设置永久代大小即可。
方法区用于存放java类型的相关信息,如类名、访问修饰符、常量池、字段描述、方法描述等。在类装载器加载class文件到内存的过程中,虚拟机会提取其中的类型信息,并将这些信息存储到方法区。当需要存储类信息而方法区的内存占用又已经达到-XX:MaxPermSize设置的最大值,将会抛出OutOfMemoryError异常。对于这种情况的测试,基本的思路是运行时产生大量的类去填满方法区,直到溢出。这里需要借助CGLib直接操作字节码运行时,生成了大量的动态类。例子如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
-XX:MaxPermSize为10m。其中的一次测试结果为,当count的值累加到800时,发生如下异常:
Caused by: java.lang.OutOfMemoryError: PermGen space
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:792)
... 8 more
随着-XX:MaxPermSize参数值的增大,java方法区中可以存储的类型数据也越多。
四、OutOfMemoryError
操作系统对每个进程的内存都是有一定限制的,当堆内存和非堆内存分配过大时,剩余的内存不足以创建足够的线程栈,就会产生OutOfMemoryError。因此我们可以增大进程占用的总内存或减小堆内存等来解决问题。
1、PermGen space
发生这种问题的原意是程序中使用了大量的jar或class,使java虚拟机装载类的空间不够,与Permanent Generation space有关。解决这类问题有以下两种办法:
1.1、增加java虚拟机中的XX:PermSize和XX:MaxPermSize参数的大小,其中XX:PermSize是初始永久保存区域大 小,XX:MaxPermSize是最大永久保存区域大小。如针对tomcat6.0,在catalina.sh 或catalina.bat文件中一系列环境变量名说明结束处(大约在70行左右) 增加一行: JAVA_OPTS=" -XX:PermSize=64M -XX:MaxPermSize=128m" 如果是windows服务器还可以在系统环境变量中设置。感觉用tomcat发布sprint+struts+hibernate架构的程序时很容易发生这种内存溢出错误。使用上述方法,我成功解决了部署ssh项目的tomcat服务器经常宕机的问题。
1.2、清理应用程序中web-inf/lib下的jar,如果tomcat部署了多个应用,很多应用都使用了相同的jar,可以将共同的jar移到 tomcat共同的lib下,减少类的重复加载。这种方法是网上部分人推荐的,我没试过,但感觉减少不了太大的空间,最靠谱的还是第一种方法。
2、OutOfMemoryError: Java heap space
发生这种问题的原因是java虚拟机创建的对象太多,在进行垃圾回收之间,虚拟机分配的到堆内存空间已经用满了,与Heap space有关。解决这类问题有两种思路:
2.1、检查程序,看是否有死循环或不必要地重复创建大量对象。找到原因后,修改程序和算法。 我以前写一个使用K-Means文本聚类算法对几万条文本记录(每条记录的特征向量大约10来个)进行文本聚类时,由于程序细节上有问题,就导致了 Java heap space的内存溢出问题,后来通过修改程序得到了解决。
2.2、增加Java虚拟机中Xms(初始堆大小)和Xmx(最大堆大小)参数的大小。如:set JAVA_OPTS= -Xms256m -Xmx1024m
13、static介绍一下,代码块执行顺序 √
众所周知 在android中static 修饰的会被称之为 静态常量,静态变量, 静态方法 ,还有就是静态代码块,用static{ // 代码块 非static修饰的方法,变量,常量, 是不能再静态代码块中使用的 } 表示。
static修饰的 是跟着类走的, 而不是跟随对象,这个大家都是知道的。 那么大家是否知道它们之间的运行顺序的关系呢? 今天, 我就给大家简单讲解一下吧。
静态常量,静态变量,静态方法, 大家都知道是通过类名直接调用的(例如:Demo.getStatic() )。但是静态代码块 大家都没有主动调用过 对吧。 那它 到底什么时候被执行呢? 让我来揭晓吧, 其实只要你的代码在任意地方,动用了静态代码块所属的类中的 任意东西, 那么该静态代码块 就会马上执行(说白了就是 静态代码块是这个类最先执行的代码, 但前提是你要使用这个类, 不使用的话, 这个类中的静态代码块是不会执行的 与静态变量相比就是看代码编写的前后顺序,和静态方法有很大的区别)。 当一个类中 有多个静态代码块的时候,是按照代码编写的上下顺序先后执行的。
静态代码块 与 静态变量之间的关系:
如果你想正确使用两者的话, 个人建议 你必须把静态变量定义在静态代码块的前面, 因为两个的执行是会根据代码编写的顺序来决定的。这个比较难理解, 我来举个例子吧, 情况下面代码:
public class Demo{
public static int i;
static{
i = 20;
//这里的i, 是可以被用作运算的。
}
}
这时候如果你在main函数输出i, 那么i=20;
public class Demo{
static{
i = 20;
//这里的i, 是不能被用作运算的, 因为本质上 i 还未被定义
}
public static int i;
}
这时候如果你在main函数输出i, 那么i=20;
public class Demo{
static{
i = 20;
//这里的i, 是不能被用作运算的, 因为本质上 i 还未被定义
}
public static int i = 1;
}
//但是如果我们给静态的i附上一个初始值后,那么结果就变了。
这时候如果你在main函数输出i, 那么i=1;
上述的代码 就其实就是进一步说明 静态变量 和static修改的静态代码块 运行的顺序是根据代码编写的先后, 而且第二种写法毫无意义。 未了避免出现不必要的麻烦, 本人强制建议, 不管是否有在静态代码块中使用 静态变量, 都应当把静态变量写在 静态代码块的上方。 静态常量的情况 和静态变量是一样, 这里就不在做说明了。
类内容(静态变量、静态初始化块) => 实例内容(变量、初始化块、构造器)
父类的(静态变量、静态初始化块)=> 子类的(静态变量、静态初始化块)=> 父类的(变量、初始化块、构造器)=> 子类的(变量、初始化块、构造器)
示例如下:(结果见注释)
1 class A {
2 public A() {
3 System.out.println("Constructor A.");
4 }
5
6 {
7 System.out.println("Instance Block A.");
8 }
9 static {
10 System.out.println("Static Block A.");
11 }
12
13 public static void main(String[] args) {
14 new A();/*
15 * Static Block A. Instance Block A. Constructor A.
16 */
17 }
18 }
19
20 class B extends A {
21 public B() {
22 System.out.println("Constructor B.");
23 }
24
25 {
26 System.out.println("Instance Block B.");
27 }
28 static {
29 System.out.println("Static Block B.");
30 }
31
32 public static void main(String[] args) {
33 new A();/*
34 * Static Block A. Static Block B. Instance Block A. Constructor A.
35 */
36 System.out.println();
37 new B();/*
38 * Instance Block A. Constructor A. Instance Block B. Constructor B.
39 */// 静态成员和静态初始化块只会执行一次。
40 }
41 }
一个变量,若显示初始化、初始化块对该变量赋值、构造方法对该变量赋值同时存在,则变量最终值如何确定?按1节中所述的执行顺序确定。
这里考虑初始化块在变量定义之前的情形,此时会造成迷惑。
初始化块可以对在它之后定义的变量赋值,但不能访问(如打印)。如:
1 static {
2 a = 3;
3 // int b=a;//Cannot reference a field before it is defined
4 // System.out.println(a);//Cannot reference a field before it is defined
5 }
6 static int a = 1;
“对变量值的影响”是指 对变量赋值的初始化块位于变量定义之前 时,变量的最终值根据变量定义时是否显示初始化而会有不同结果(若初始化块位于变量定义之后,那么变量的值显然很容易就确定了,不会造成迷惑)。如:
1 class Test {
2 static {
3 a = 3;
4 // int b=a;//Cannot reference a field before it is defined
5 // System.out.println(a);//Cannot reference a field before it is defined
6 b = 3;
7 }
8 static int a = 1;
9 static int b;
10
11 public static void main(String[] args) {
12 System.out.println(a);//1
13 System.out.println(b);//3
14 }
15 }
判断方法:
显示初始化内部隐含 定义变量和对变量进行赋值的初始化块两部分,所以初始化块和显示初始化哪个在后变量的最终值就是该值。
更多示例:
1:
1 class C {
2
3 static {
4 a = 2;
5 b = 2;
6 }
7 static int a;
8 static int b = 1;
9
10 public C() {
11 e = 3;
12 }
13
14 {
15 c = 2;
16 d = 2;
17 e = 2;
18 }
19 int c;
20 int d = 1;
21 int e = 1;
22
23 public static void main(String[] args) {
24 System.out.println(C.a);//2
25 System.out.println(C.b);//1
26 System.out.println(new C().c);//2
27 System.out.println(new C().d);//1
28 System.out.println(new C().e);//3
29 }
2:
1 class C {
2 public C() {
3 }
4
5 {
6 a = 3;
7 }
8 static {
9 a = 2;
10 }
11 static int a;
12 static int b;
13
14 public static void main(String[] args) {
15 System.out.println(C.a);// 2
16 System.out.println(new C().a);// 3
17 System.out.println(C.b);// 0
18 }
19 }
3:
1 class C {
2 // 以下关于静态初始化的
3 static {
4 a = 2;
5 }
6 static int a = 1;
7 static int b = 1;
8 static {
9 b = 2;
10 c = 2;
11 }
12 static int c;
13
14 {
15 d = 2;
16 }
17 int d = 1;
18 int e = 1;
19 {
20 e = 2;
21 f = 2;
22 }
23 int f;
24
25 public static void main(String[] args) {
26 System.out.println(C.a);// 1
27 System.out.println(C.b);// 2
28 System.out.println(new C().c);// 2
29 System.out.println(new C().d);// 1
30 System.out.println(new C().e);// 2
31 System.out.println(new C().f);// 2
32 }
33 }
执行顺序:
1、类内容(静态变量、静态初始化块) => 实例内容(变量、初始化块、构造器)
2、父类的(静态变量、静态初始化块)=> 子类的(静态变量、静态初始化块)=> 父类的(变量、初始化块、构造器)=> 子类的(变量、初始化块、构造器)
初始化块可以对在它之后定义的变量赋值,但不能访问(如打印)。
变量最终值:一个变量,若显示初始化、初始化块对该变量赋值、构造方法对该变量赋值同时存在,则变量最终值如何确定:
1、按执行顺序
2、若对变量赋值的初始化块在变量定义前时:若变量显示初始化了则最终为显示初始化值,否则为初始化块的赋值。

















 1589
1589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









