







给全连接层使用
动机
- 一个好的模型需要对输入数据的扰动鲁棒,即对于输入的噪音,能有一定的鲁棒性
- 使用有噪音的数据等价于Tikhonov正则
- 丢弃法:在层之间加入噪音
无偏差的加入噪音
- 对
x
\mathbf{x}
x加入噪音得到
x
‘
\mathbf{x}^{`}
x‘,加噪音是为了提高鲁棒性,因此我们希望加入噪音后不改变期望,即
E [ x ‘ ] = x \mathbf{E[x^{`}]=x} E[x‘]=x - 丢弃法对每个元素进行如下扰动

这种方法 E [ x i ‘ ] \mathbf{E[x_{i}^{`}]} E[xi‘]没有变化
使用丢弃法
- 通常将丢弃法作用在隐藏全连接层的输出上
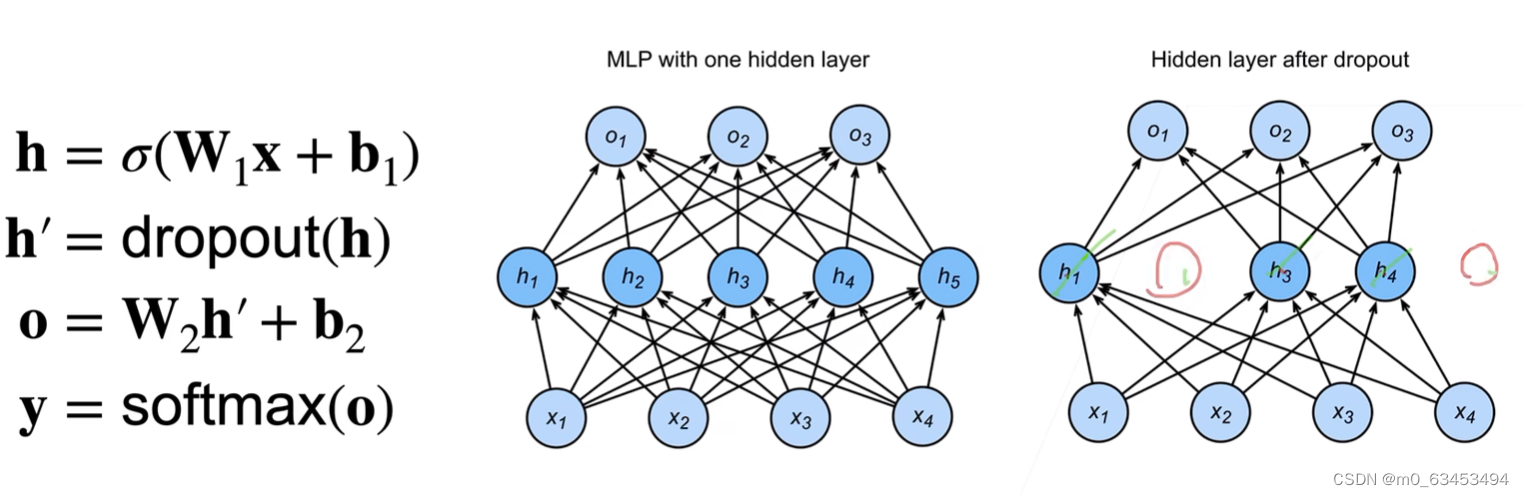
图中是对隐藏层采用dropout,即对于激活函数输出后的 h \mathbf{h} h,通过dropout以概率 p p p将值变为0,以概率 1 − p 1-p 1−p将值变为 h i 1 − p \frac{h_i}{1-p} 1−phi,可以看到右边 h 2 h_2 h2和 h 5 h_5 h5消失了,然后对于 o \mathbf{o} o的计算,参数来自于丢弃法作用后的 h ‘ \mathbf{h}^` h‘,再用softmax计算结果
推理中的丢弃法
- 正则项只在训练中使用:他们影响模型参数的更新
- 在推理过程中,丢弃法直接返回输入
h = d r o p o u t ( h ) \mathbf{h}=dropout(\mathbf{h}) h=dropout(h)- 这样也能保证确定性的输出
总结
- 丢弃法将一些输出项随机置0来控制模型复杂度
- 常作用在多层感知机的隐藏层输出上
- 丢弃概率是控制模型复杂度的超参数
dropout随机丢弃,如果想要保持结果可重复性,需要控制随机的seed,一个是randn的seed,一个是dropout参数,平时没必要可重复
丢弃法在训练时把某些神经元丢弃,在此时的训练不把这些神经元的参数更新,而在预测时网络中的神经元是没有丢弃的


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









