





经过第一次训练后发现,模型出现了过拟合现象:
因此我们扩大了数据集数量,此次共爬取20230867字,格式如下:
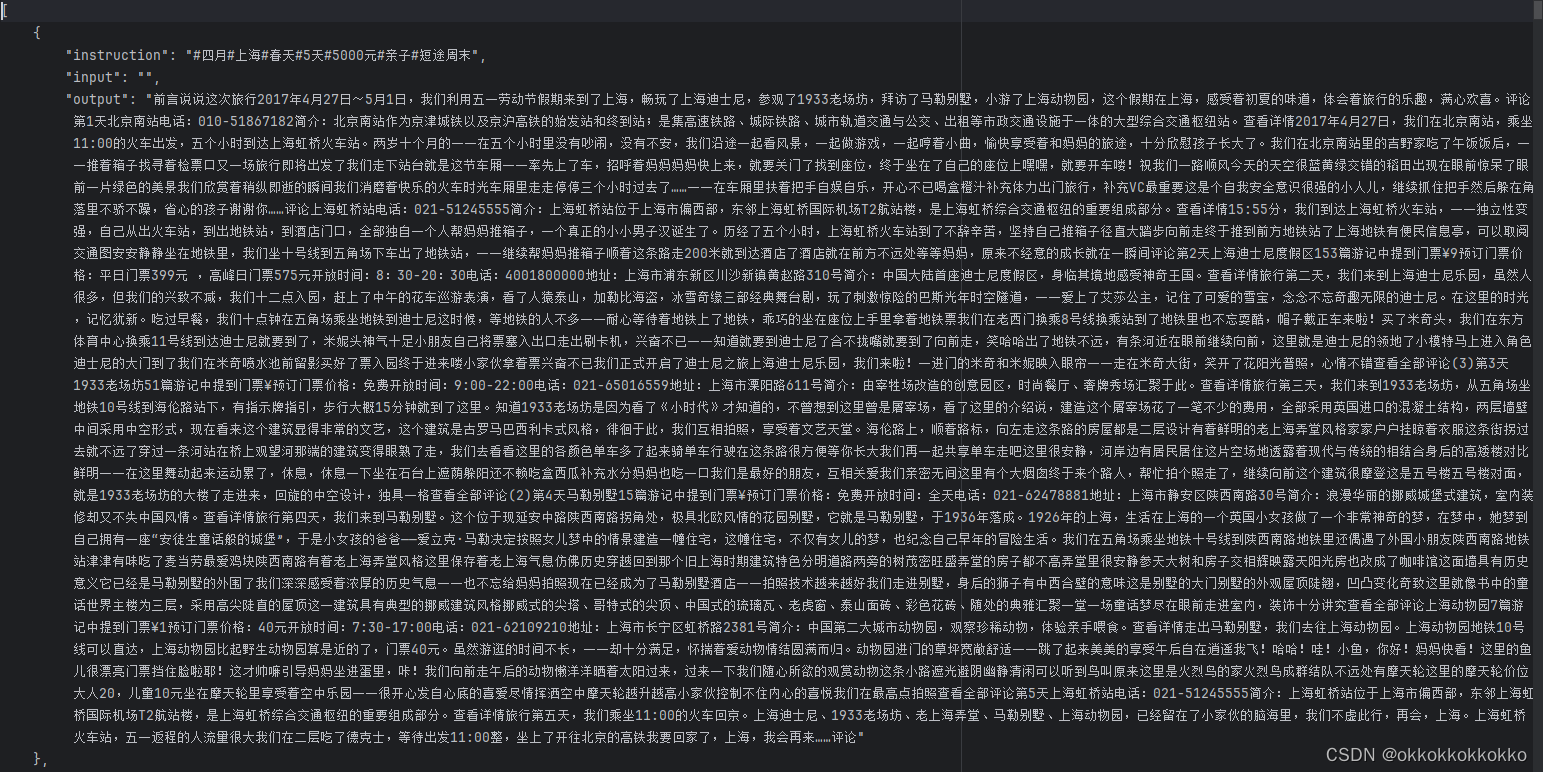
其中有超过10000条json数据,里面包含了每一条的攻略信息
其中标签信息重复过多,因此我们单独对标签数据进行去重:

发现其内容质量较高,重新送入模型中训练
预览训练代码
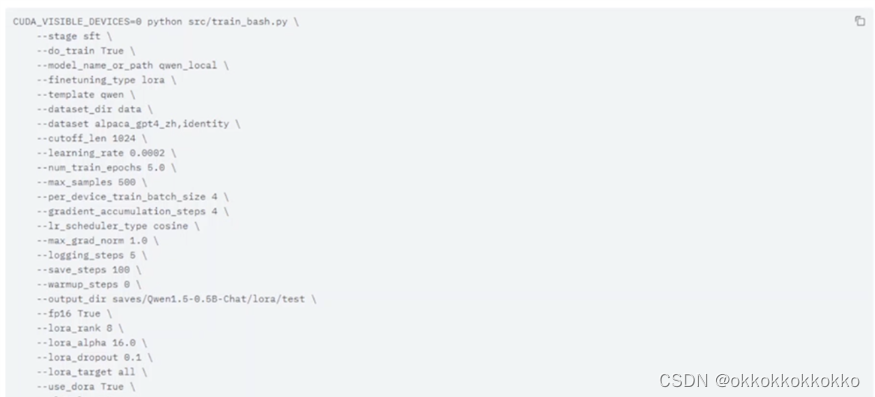
训练开始,此次共训练了13H(时间好长),因此没来得及保存结束时的输出信息(睡着了),训练过程loss如下: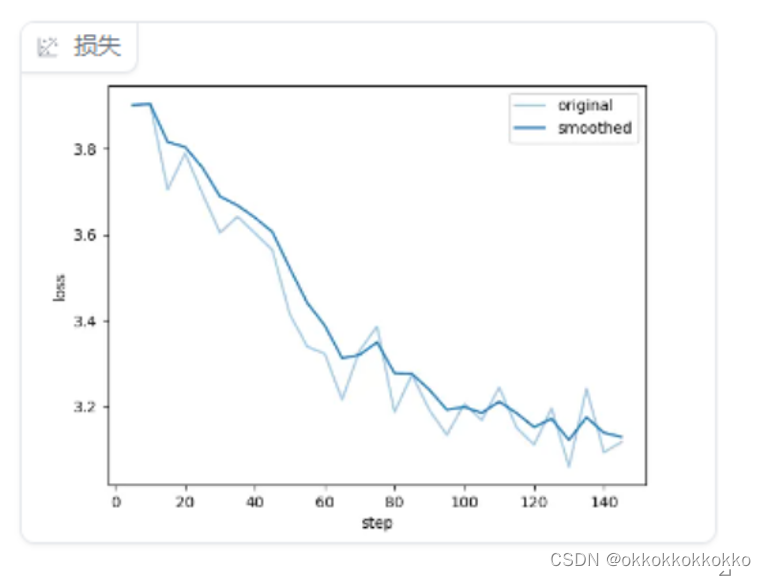
此次模型效果更佳,且加入了多地的信息
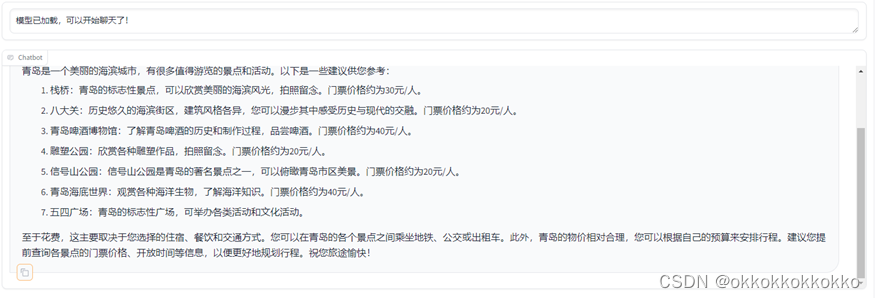
训练完成,接下来导出模型

经过第一次训练后发现,模型出现了过拟合现象:
因此我们扩大了数据集数量,此次共爬取20230867字,格式如下:
其中有超过10000条json数据,里面包含了每一条的攻略信息
其中标签信息重复过多,因此我们单独对标签数据进行去重:
发现其内容质量较高,重新送入模型中训练
预览训练代码
训练开始,此次共训练了13H(时间好长),因此没来得及保存结束时的输出信息(睡着了),训练过程loss如下:
此次模型效果更佳,且加入了多地的信息
训练完成,接下来导出模型

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























