







关于“SASRec 基于自注意力的序列推荐”这篇论文的学习笔记和代码复现可以看之前写的这两篇:
学习笔记——SASRec 基于自注意力的序列推荐-优快云博客
代码复现——SASRec 基于自注意力的序列推荐-优快云博客
这次是关于这篇论文的代码展示,全文一万六千多字,难免会有所疏漏,有任何问题欢迎指出。
需要完整代码压缩包的伙伴可以私信我(复现不易,分享难得,小偿即可,白嫖勿扰)。
1、项目代码结构

1.1、data文件夹中存放了各种经过处理的数据集

文本内容长这样

其中user-course_order.txt是由user-course_order.json得来的, user-course_order.json长这样:

1.2、jsonProcessing文件夹中存放的是各种数据处理代码
如何将json文件转换成模型所需的数据格式呢,在jsonProcessing文件夹下运行json2txt.py代码

import json
def read_json(file_path):
"""
读取JSON文件,文件中每一行都是一个独立的JSON对象。它将每一行解析为Python字典,并将所有用户存储在一个列表中。
"""
data = []
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
data.append(json.loads(line))
return data
def write_to_txt(users, output_file):
"""
遍历用户列表,对于每个用户,提取新用户ID和课程编号列表,并将它们转换为指定的格式(每行包含用户ID和课程ID),然后写入TXT文件。
"""
with open(output_file, 'w', encoding='utf-8') as file:
for user in users:
new_user_id = user['新用户id']
for course_id in user['course_order_numbered']:
file.write(f"{new_user_id} {course_id}\n")
# 主函数
def main():
"""
读取JSON文件中的用户数据。
遍历每个用户的数据,提取新用户ID和课程编号列表。
将这些数据转换为指定的格式,即每行包含用户ID和课程ID。
将转换后的数据写入TXT文件。
"""
user_json_path = '../data/selected_user_numbered.json' # 筛选后的用户JSON文件路径
output_txt_path = '../data/user-course_order.txt' # 输出TXT文件路径
# 读取筛选后的用户数据
filtered_users = read_json(user_json_path)
# 将用户数据写入TXT文件
write_to_txt(filtered_users, output_txt_path)
print(f'用户数据已写入 {output_txt_path}')
if __name__ == '__main__':
main()
要想得到selected_user_numbered_large.json文件,要先将原始慕课数据集进行处理。
1.2.1、原始的user.json,存放了所有学生的id、姓名、课程观看序列等信息

1.2.2、原始的course.json,存放了所有课程的id、课程名等信息

1.2.3、在jsonProcessing文件夹下运行course_number.py代码
先给课程重新编号,从1开始,得到course_numbered.json,其文件内容为:

代码为:
import json
def read_course_json(file_path):
"""
读取JSON文件,假设每个课程占一行。
"""
courses = []
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
courses.append(json.loads(line))
return courses
def assign_numbers(courses):
"""
为课程分配从1开始的编号。
"""
course_id_map = {}
for index, course in enumerate(courses, start=1):
course_id_map[course['id']] = index
return course_id_map
def write_courses_with_numbers(courses, course_id_map, output_file):
"""
将编号后的数据写入新的JSON文件。
"""
with open(output_file, 'w', encoding='utf-8') as file:
for course in courses:
# 创建一个新的字典,只包含编号、原编号和课程名
new_course = {
'新课程编号id': course_id_map[course['id']],
'原课程编号id': course['id'],
'课程名name': course['name']
}
# 将新的课程字典转换为JSON格式的字符串,并确保中文字符不被转义
json.dump(new_course, file, ensure_ascii=False)
file.write('\n')
# def write_courses_with_numbers(courses, course_id_map, output_file):
# """
# 将编号后的数据写入新的JSON文件。
# """
# # 创建一个新的列表,包含所有课程的编号信息
# numbered_courses = [
# {
# '新课程编号id': course_id_map[course['id']],
# '原课程编号id': course['id'],
# '课程名name': course['name']
# } for course in courses
# ]
# # 将新的课程列表转换为JSON格式的字符串,并确保中文字符不被转义
# with open(output_file, 'w', encoding='utf-8') as file:
# json.dump(numbered_courses, file, ensure_ascii=False, indent=4)
# 主函数
def main():
course_json_path = '/Dataset/MOOCCube/entities/course.json' # 课程JSON文件路径
output_file = '../data/course_numbered.json' # 输出文件路径
courses = read_course_json(course_json_path)
course_id_map = assign_numbers(courses)
write_courses_with_numbers(courses, course_id_map, output_file)
print(f'课程编号完成,共编号了 {len(courses)} 门课程。')
if __name__ == '__main__':
main()
1.2.4、在jsonProcessing文件夹下运行set_user_number.py代码
得到course_numbered.json文件后,给学生重新编号,从1开始,得到user_numbered.json
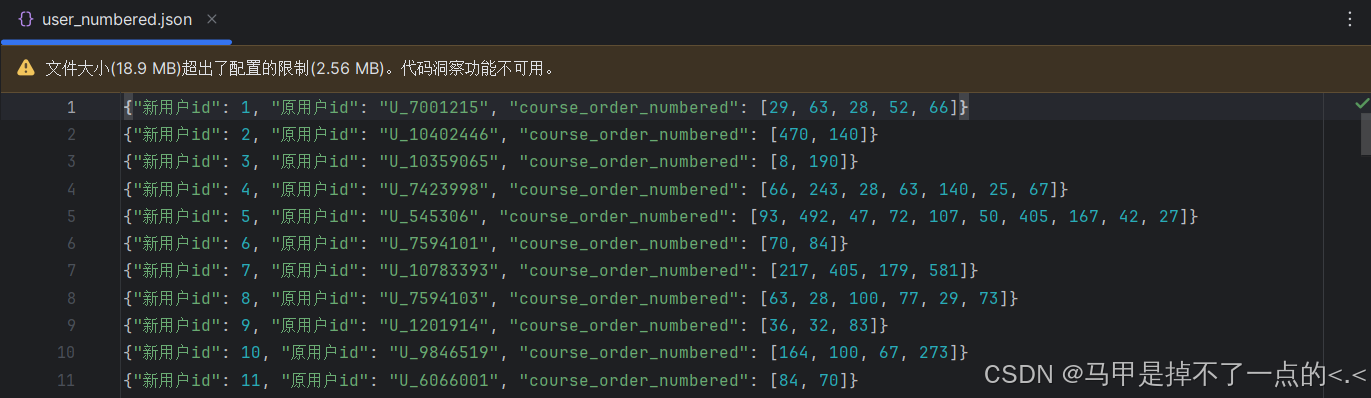
第一行内容代表用户1的课程观看顺序为:29, 63, 28, 52, 66,一共上了5节课。以此类推.....
import json
def read_json(file_path):
"""
读取JSON文件,假设文件中每一行都是一个独立的JSON对象。
"""
data = []
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
data.append(json.loads(line))
return data
def assign_numbers(data):
"""
为数据中的每个项分配从1开始的编号。
"""
id_map = {}
for index, item in enumerate(data, start=1):
id_map[item['id']] = index
return id_map
def update_course_orders(users, course_id_map):
"""
更新用户的课程订单为新的课程编号。
"""
for user in users:
user['course_order_numbered'] = [course_id_map[course_id] for course_id in user['course_order']]
user['新课程编号id'] = user['course_order_numbered']
del user['course_order']
def write_json(data, file_path):
"""
将数据写入指定的JSON文件。
"""
with open(file_path, 'w', encoding='utf-8') as file:
for item in data:
json.dump(item, file, ensure_ascii=False)
file.write('\n')
# 主函数
def main():
course_json_path = '../data/course_numbered.json'
user_json_path = 'D:/pythonCode/推荐系统/Dataset/MOOCCube/entities/user.json'
output_user_path = '../data/user_numbered.json'
# 读取课程数据并创建编号映射字典
courses = read_json(course_json_path)
course_id_map = {course['原课程编号id']: course['新课程编号id'] for course in courses}
# 读取用户数据
users = read_json(user_json_path)
# 为用户分配编号
user_id_map = assign_numbers(users)
# 更新用户课程订单为新编号
update_course_orders(users, course_id_map)
# print("新的用户编号映射(部分):")
# for key, value in list(selected_user_id_map.items())[:5]: # 打印前5个条目
# print(f"原用户id: {key}, 新用户id: {value}")
# 写入新的用户编号数据
write_json(
[{'新用户id': user_id_map[user['id']], '原用户id': user['id'], 'course_order_numbered': user['新课程编号id']}
for user in users], output_user_path)
print(f'用户编号完成,共编号了 {len(users)} 个用户。')
if __name__ == '__main__':
main()
1.2.5、在jsonProcessing文件夹下运行selected_user.py代码
对course_numbered.json文件进行筛选,去除课程观看数小于10的用户,其历史交互序列太少....
得到selected_user_numbered.json。
import json
def read_json(file_path):
"""
读取JSON文件,假设文件中每一行都是一个独立的JSON对象。
"""
data = []
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
data.append(json.loads(line))
return data
def assign_numbers(data):
"""
为数据中的每个项分配从1开始的编号。
"""
id_map = {}
for index, item in enumerate(data, start=1):
id_map[item['id']] = index
return id_map
def update_course_orders(users, course_id_map):
"""
更新用户的课程订单为新的课程编号。
"""
for user in users:
user['course_order_numbered'] = [course_id_map[course_id] for course_id in user['course_order']]
user['新课程编号id'] = user['course_order_numbered']
del user['course_order']
def write_json(data, file_path):
"""
将数据写入指定的JSON文件。
"""
with open(file_path, 'w', encoding='utf-8') as file:
for item in data:
json.dump(item, file, ensure_ascii=False)
file.write('\n')
def filter_users(users):
"""
剔除学习课程小于10门的用户。
"""
return [user for user in users if len(user['course_order_numbered']) >= 10]
# 主函数
def main():
course_json_path = '../data/course_numbered.json'
user_json_path = 'D:/pythonCode/推荐系统/Dataset/MOOCCube/entities/user.json'
selected_user_path = '../data/selected_user_numbered.json'
# 读取课程数据并创建编号映射字典
courses = read_json(course_json_path)
course_id_map = {course['原课程编号id']: course['新课程编号id'] for course in courses}
# 读取用户数据
users = read_json(user_json_path)
# 更新用户课程订单为新编号
update_course_orders(users, course_id_map)
# 剔除学习课程小于5门的用户
selected_users = filter_users(users)
# 重新编号,从1开始
selected_user_id_map = assign_numbers(selected_users)
# 写入筛选后的用户编号数据
write_json(
[{'新用户id': selected_user_id_map[user['id']], '原用户id': user['id'], 'course_order_numbered': user['新课程编号id']}
for user in selected_users], selected_user_path)
print(f'筛选后的用户编号完成,共编号了 {len(selected_users)} 个用户。')
if __name__ == '__main__':
main()
1.2.6、统计分析数据集情况
在jsonProcessing文件夹下运行statistics_user_course.py代码,得到的结果为:

import json
def read_json(file_path):
"""
读取JSON文件,假设文件中每一行都是一个独立的JSON对象。
"""
data = []
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
data.append(json.loads(line))
return data
def calculate_averages(filtered_users):
"""
计算平均每个用户观看的课程数和平均每个课程的被观看数。
"""
# 初始化变量,用于计算总的课程数量
total_courses = 0
# 初始化一个空字典,用于记录每个课程被观看的次数
every_course_view_count = {}
# 遍历筛选后的用户列表
for user in filtered_users:
# 获取当前用户的课程编号列表
course_list = user['course_order_numbered']
# 将当前用户的课程数量累加到总课程数量中
total_courses += len(course_list)
# 遍历当前用户的所有课程编号
for course_id in course_list:
# 如果课程编号已经在字典中,则增加该课程的观看次数
if course_id in every_course_view_count:
every_course_view_count[course_id] += 1
# 如果课程编号不在字典中,将其添加到字典中,并设置观看次数为1
else:
every_course_view_count[course_id] = 1
# 通过将总的课程数量除以用户数量,计算平均每个用户观看的课程数
average_courses_per_user = total_courses / len(filtered_users)
# 通过将所有课程的观看次数之和除以课程数量,计算平均每个课程的被观看数
average_views_per_course = sum(every_course_view_count.values()) / len(every_course_view_count)
# 返回总用户数、总课程观看数、平均每个用户观看的课程数和平均每个课程的被观看数
return len(filtered_users), total_courses, average_courses_per_user, average_views_per_course
# 主函数
def main():
user_json_path = '../data/selected_user_numbered.json'
"""已经有了一个经过筛选的用户JSON文件(即selected_user_numbered.json),
其中包含学习课程数量大于或等于10门的用户。代码读取这个文件,然后计算所需的平均值。"""
# 读取筛选后的用户数据
filtered_users = read_json(user_json_path)
# 计算平均值
sum_users, sum_courses, avg_courses_per_user, avg_views_per_course = calculate_averages(filtered_users)
print(f'总用户数: {sum_users:.2f}')
print(f'总课程观看数: {sum_courses:.2f}')
print(f'平均每个用户观看的课程数: {avg_courses_per_user:.2f}')
print(f'平均每个课程的被观看数: {avg_views_per_course:.2f}')
if __name__ == '__main__':
main()
1.2.7、在jsonProcessing文件夹下运行json2txt.py代码
最终就得到了符合模型输入的txt文本文件,其文本内容在1.1章中查看。
import json
def read_json(file_path):
"""
读取JSON文件,文件中每一行都是一个独立的JSON对象。它将每一行解析为Python字典,并将所有用户存储在一个列表中。
"""
data = []
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
data.append(json.loads(line))
return data
def write_to_txt(users, output_file):
"""
遍历用户列表,对于每个用户,提取新用户ID和课程编号列表,并将它们转换为指定的格式(每行包含用户ID和课程ID),然后写入TXT文件。
"""
with open(output_file, 'w', encoding='utf-8') as file:
for user in users:
new_user_id = user['新用户id']
for course_id in user['course_order_numbered']:
file.write(f"{new_user_id} {course_id}\n")
# 主函数
def main():
"""
读取JSON文件中的用户数据。
遍历每个用户的数据,提取新用户ID和课程编号列表。
将这些数据转换为指定的格式,即每行包含用户ID和课程ID。
将转换后的数据写入TXT文件。
"""
user_json_path = '../data/selected_user_numbered_large.json' # 筛选后的用户JSON文件路径
output_txt_path = '../data/user-course_order_large.txt' # 输出TXT文件路径
# 读取筛选后的用户数据
filtered_users = read_json(user_json_path)
# 将用户数据写入TXT文件
write_to_txt(filtered_users, output_txt_path)
print(f'用户数据已写入 {output_txt_path}')
if __name__ == '__main__':
main()
1.3、日志
这四个文件夹是日志文件夹,在main.py运行后会自动生成,如果项目从未运行过,应该是不会有这四个文件夹的。每个文件夹有Test和Val日志,并且会有模型的权重文件(pth)
其文件结构长这样:
1.4、main.py,主函数
这是主函数的参数设置截图,都有详细的中文注释。默认数据集是ml-1m,我指定为课程数据集。
1.5、model.py
对transformer模型的定义,没有采用对比学习。
import numpy as np
import torch
class PointWiseFeedForward(torch.nn.Module):
def __init__(self, hidden_units, dropout_rate):
super(PointWiseFeedForward, self).__init__()
self.conv1 = torch.nn.Conv1d(hidden_units, hidden_units, kernel_size=1)
self.dropout1 = torch.nn.Dropout(p=dropout_rate)
self.relu = torch.nn.ReLU()
self.conv2 = torch.nn.Conv1d(hidden_units, hidden_units, kernel_size=1)
self.dropout2 = torch.nn.Dropout(p=dropout_rate)
def forward(self, inputs):
outputs = self.dropout2(self.conv2(self.relu(self.dropout1(self.conv1(inputs.transpose(-1, -2))))))
outputs = outputs.transpose(-1, -2) # as Conv1D requires (N, C, Length)
outputs += inputs
return outputs
# pls use the following self-made multihead attention layer
# in case your pytorch version is below 1.16 or for other reasons
# https://github.com/pmixer/TiSASRec.pytorch/blob/master/model.py
class SASRec(torch.nn.Module):
def __init__(self, user_num, item_num, args):
super(SASRec, self).__init__()
self.user_num = user_num
self.item_num = item_num
self.dev = args.device
# TODO: loss += args.l2_emb for regularizing embedding vectors during training
# https://stackoverflow.com/questions/42704283/adding-l1-l2-regularization-in-pytorch
self.item_emb = torch.nn.Embedding(self.item_num + 1, args.hidden_units, padding_idx=0)
self.pos_emb = torch.nn.Embedding(args.maxlen + 1, args.hidden_units, padding_idx=0)
self.emb_dropout = torch.nn.Dropout(p=args.dropout_rate)
self.attention_layernorms = torch.nn.ModuleList() # to be Q for self-attention
self.attention_layers = torch.nn.ModuleList()
self.forward_layernorms = torch.nn.ModuleList()
self.forward_layers = torch.nn.ModuleList()
self.last_layernorm = torch.nn.LayerNorm(args.hidden_units, eps=1e-8)
for _ in range(args.num_blocks):
new_attn_layernorm = torch.nn.LayerNorm(args.hidden_units, eps=1e-8)
self.attention_layernorms.append(new_attn_layernorm)
new_attn_layer = torch.nn.MultiheadAttention(args.hidden_units,
args.num_heads,
args.dropout_rate)
self.attention_layers.append(new_attn_layer)
new_fwd_layernorm = torch.nn.LayerNorm(args.hidden_units, eps=1e-8)
self.forward_layernorms.append(new_fwd_layernorm)
new_fwd_layer = PointWiseFeedForward(args.hidden_units, args.dropout_rate)
self.forward_layers.append(new_fwd_layer)
def log2feats(self, log_seqs): # TODO: fp64 and int64 as default in python, trim?
seqs = self.item_emb(torch.LongTensor(log_seqs).to(self.dev))
seqs *= self.item_emb.embedding_dim ** 0.5
poss = np.tile(np.arange(1, log_seqs.shape[1] + 1), [log_seqs.shape[0], 1])
# TODO: directly do tensor = torch.arange(1, xxx, device='cuda') to save extra overheads
poss *= (log_seqs != 0)
seqs += self.pos_emb(torch.LongTensor(poss).to(self.dev))
seqs = self.emb_dropout(seqs)
tl = seqs.shape[1] # time dim len for enforce causality
attention_mask = ~torch.tril(torch.ones((tl, tl), dtype=torch.bool, device=self.dev))
for i in range(len(self.attention_layers)):
seqs = torch.transpose(seqs, 0, 1)
Q = self.attention_layernorms[i](seqs)
mha_outputs, _ = self.attention_layers[i](Q, seqs, seqs,
attn_mask=attention_mask)
# need_weights=False) this arg do not work?
seqs = Q + mha_outputs
seqs = torch.transpose(seqs, 0, 1)
seqs = self.forward_layernorms[i](seqs)
seqs = self.forward_layers[i](seqs)
log_feats = self.last_layernorm(seqs) # (U, T, C) -> (U, -1, C)
return log_feats
def forward(self, user_ids, log_seqs, pos_seqs): # for training
log_feats = self.log2feats(log_seqs) # user_ids hasn't been used yet
pos_embs = self.item_emb(torch.LongTensor(pos_seqs).to(self.dev))
pos_logits = (log_feats * pos_embs).sum(dim=-1)
return pos_logits # pos_pred
def predict(self, user_ids, log_seqs, item_indices): # for inference
log_feats = self.log2feats(log_seqs) # user_ids hasn't been used yet
final_feat = log_feats[:, -1, :] # only use last QKV classifier, a waste
item_embs = self.item_emb(torch.LongTensor(item_indices).to(self.dev)) # (U, I, C)
logits = item_embs.matmul(final_feat.unsqueeze(-1)).squeeze(-1)
return logits # preds # (U, I)
1.6、utils.py
工具库,没有采用对比学习,代码太长了,三百多行,我这里只展示evaluate_valid和evaluate_test,并且能够计算NDCG@k 和 HR@k,k=1, 2, 5, 10。官方源码只能计算NDCG@10 和 HR@10。
def evaluate_test(model, dataset, args):
"""
在测试集上评估模型的性能。
参数:
model: 要评估的推荐模型。
dataset: 包含训练集、验证集、测试集、用户总数和物品总数的数据集。
args: 包含模型参数的命名空间。
返回:
tuple: 包含 NDCG 和 HR 的评估结果,每个都有一个 k=1, 2, 5, 10 的值。
"""
# 深拷贝数据集,以免在评估过程中修改原始数据
[train, valid, test, usernum, itemnum] = copy.deepcopy(dataset)
# 初始化 NDCG 和 HR 的累计值
NDCG = {k: 0.0 for k in [1, 2, 5, 10]}
HR = {k: 0.0 for k in [1, 2, 5, 10]}
valid_user = 0.0 # 有效用户计数器
# 根据用户数量,选择一定数量的用户进行评估
if usernum > 10000:
users = random.sample(range(1, usernum + 1), 10000)
else:
users = range(1, usernum + 1)
# 遍历用户,进行评估
for u in users:
if len(train[u]) < 1 or len(test[u]) < 1:
continue
seq = np.zeros([args.maxlen], dtype=np.int32)
idx = args.maxlen - 1
# 将验证集中的第一个物品放在序列的最后
seq[idx] = valid[u][0]
idx -= 1
for i in reversed(train[u]):
seq[idx] = i
idx -= 1
if idx == -1:
break
rated = set(train[u])
rated.add(0)
item_idx = [test[u][0]]
for _ in range(100):
t = np.random.randint(1, itemnum + 1)
while t in rated:
t = np.random.randint(1, itemnum + 1)
item_idx.append(t)
# 使用模型对用户u的序列和物品列表进行预测
predictions = -model.predict(*[np.array(l) for l in [[u], [seq], item_idx]])
predictions = predictions[0] # 获取第一个用户u的预测结果
# 获取测试集中第一个物品的预测排名
rank = predictions.argsort().argsort()[0].item()
# 更新有效用户计数器
valid_user += 1
for k in [1, 2, 5, 10]:
if rank < k:
HR[k] += 1
NDCG[k] += 1 / np.log2(rank + 2)
# 每处理100个用户,打印一个点以显示进度
if valid_user % 100 == 0:
print('.', end="")
sys.stdout.flush()
# 计算并返回平均 NDCG 和 HR
NDCG_avg = {k: NDCG[k] / valid_user if valid_user > 0 else 0 for k in [1, 2, 5, 10]}
HR_avg = {k: HR[k] / valid_user if valid_user > 0 else 0 for k in [1, 2, 5, 10]}
return NDCG_avg, HR_avg
def evaluate_valid(model, dataset, args):
"""
在验证集上评估模型的性能。
参数:
model: 要评估的推荐模型。
dataset: 包含训练集、验证集、测试集、用户总数和物品总数的数据集。
args: 包含模型参数的命名空间。
返回:
tuple: 包含 NDCG@k 和 HR@k 的评估结果,k=1, 2, 5, 10。
"""
# 深拷贝数据集,以免在评估过程中修改原始数据
[train, valid, test, usernum, itemnum] = copy.deepcopy(dataset)
# 初始化 NDCG 和 HR 的累计值
NDCG = {k: 0.0 for k in [1, 2, 5, 10]} # 使用字典存储不同 k 值的 NDCG
HR = {k: 0.0 for k in [1, 2, 5, 10]} # 使用字典存储不同 k 值的 HR
valid_user = 0.0 # 有效用户计数器
# 根据用户数量,选择一定数量的用户进行评估
if usernum > 10000:
users = random.sample(range(1, usernum + 1), 10000)
else:
users = range(1, usernum + 1)
# 遍历用户,进行评估
for u in users:
if len(train[u]) < 1 or len(valid[u]) < 1: continue
seq = np.zeros([args.maxlen], dtype=np.int32)
idx = args.maxlen - 1
for i in reversed(train[u]):
seq[idx] = i
idx -= 1
if idx == -1: break
rated = set(train[u])
rated.add(0)
item_idx = [valid[u][0]]
for _ in range(100):
t = np.random.randint(1, itemnum + 1)
while t in rated: t = np.random.randint(1, itemnum + 1)
item_idx.append(t)
predictions = -model.predict(*[np.array(l) for l in [[u], [seq], item_idx]])
predictions = predictions[0]
rank = predictions.argsort().argsort()[0].item()
valid_user += 1
for k in [1, 2, 5, 10]:
if rank < k:
HR[k] += 1
NDCG[k] += 1 / np.log2(rank + 2)
if valid_user % 100 == 0:
print('.', end="")
sys.stdout.flush()
# 计算并返回平均 NDCG@k 和 HR@k
NDCG_avg = {k: NDCG[k] / valid_user if valid_user > 0 else 0 for k in [1, 2, 5, 10]}
HR_avg = {k: HR[k] / valid_user if valid_user > 0 else 0 for k in [1, 2, 5, 10]}
return NDCG_avg, HR_avg
2、项目运行效果
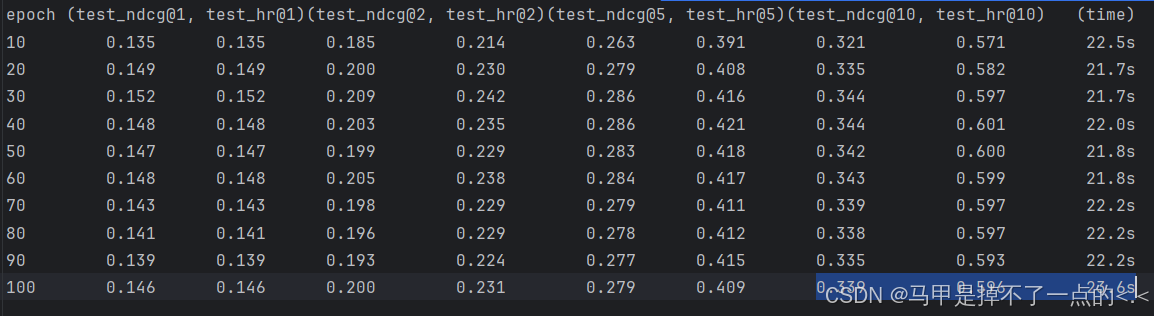
未引入对比学习其结果为:
avg_test_ndcg@10=0.338, avg_test_hr@10=0.5933, avg_time=22.17s/10epoch,RX1650
引入对比学习后,其结果为:
avg_test_ndcg@10=0.4773, avg_test_hr@10=0.7467, avg_time=23.36s/10epoch
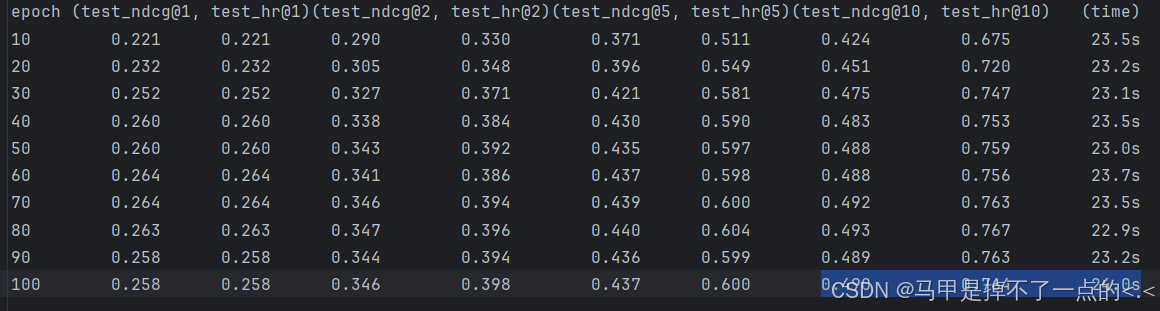
对比原先结果,性能提升明显:
avg_test_ndcg@10=0.338,avg_test_hr@10=0.5933,avg_time=22.17s/10epoch
3、改进,使得精度提升
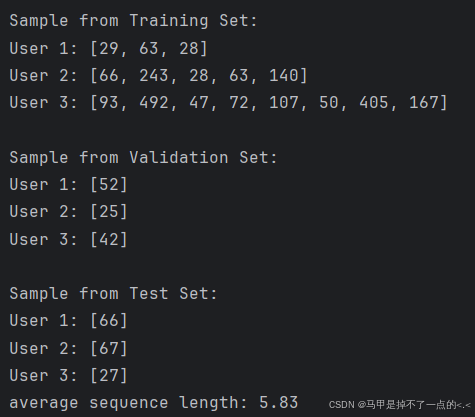
将原先筛选用户的条件由10改为5,使得数据集增加。
经过筛选,统计出用户和课程的数量、平均每个用户观看的课程数、平均每个课程的被观看数
总用户数: 34917.00;总课程观看数: 273397.00
平均每个用户观看的课程数: 7.83;平均每个课程的被观看数: 391.69。如下图:

用户平均交互序列长度为5.83,交互比之前更加稀疏:
再次运行,其结果为:
avg_test_ndcg@10=0.5587,avg_test_hr@10=0.8184,avg_time= 148.14s/10epoch
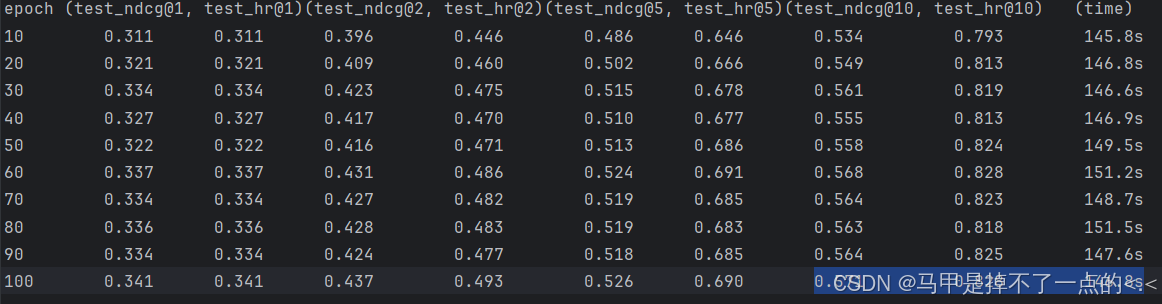
对比第二节的结果,性能提升巨大:
avg_test_ndcg@10=0.4773,avg_test_hr@10=0.7467,avg_time=23.36s/10epoch
以上就是我对于这篇论文的一个复现代码,大家可以借鉴借鉴,学习代码思想,自己创作。
需要完整代码压缩包的伙伴可以私信我(复现不易,分享难得,小偿即可,白嫖勿扰)。



















 1335
1335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











