







值得注意的是,一张数据表中只能有一个聚集索引。
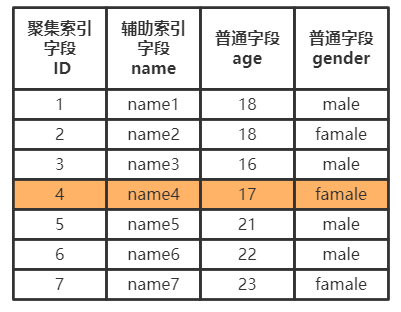
辅助索引
========
辅助索引的树最底层的叶子节点并不会存储一整行记录,而是只存储单列索引的数据,并且还存储了聚集索引的信息。
通过辅助索引进行查询时,先拿到自身索引字段的数据,再通过聚集索引拿到整行记录,也就是说辅助索引拿一整行记录而言需要最少两次查询。
而一张数据表中可以有多个辅助索引。
创建索引
========
索引类型
========
索引名类型INDEX(field)普通索引,只加速查找,无约束条件PRIMARY KEY(field)主键索引,加速查找,非空且唯一约束UNIQUE(field)唯一索引,加速查找,唯一约束INDEX(field1,field2)联合普通索引PRIMARY KEY(field1,field2)联合主键索引UNIQUE(field1,field2)联合唯一索引FULLTEXT(field)全文索引SPATIAL(field)空间索引
举个例子来说,比如你在为某商场做一个会员卡的系统。
这个系统有一个会员表有下列字段:会员编号 INT
会员姓名 VARCHAR(10)
会员身份证号码 VARCHAR(18)
会员电话 VARCHAR(10)
会员住址 VARCHAR(50)
会员备注信息 TEXT
那么这个 会员编号,作为主键,使用 PRIMARY
会员姓名 如果要建索引的话,那么就是普通的 INDEX
会员身份证号码 如果要建索引的话,那么可以选择 UNIQUE (唯一的,不允许重复)
除此之外还有全文索引,即FULLTEXT
会员备注信息如果需要建索引的话,可以选择全文搜索。用于搜索很长一篇文章的时候,效果最好。用在比较短的文本,如果就一两行字的,普通的 INDEX 也可以。
但其实对于全文搜索,我们并不会使用MySQL自带的该索引,而是会选择第三方软件如Sphinx,专门来做全文搜索。
其他的如空间索引SPATIAL,了解即可,几乎不用
各个索引的应用场景索引定义
语法介绍
========
索引应当再建立表时就进行创建,如果表中已有大量数据,再进行创建索引会花费大量的时间。
– 方法一:创建表时
CREATE TABLE 表名 (
字段名1 数据类型 [完整性约束条件…],
字段名2 数据类型 [完整性约束条件…],
[UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY [索引名] (字段名[(长度)] [ASC |DESC]) );-- 方法二:CREATE在已存在的表上创建索引
CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名
ON 表名 (字段名[(长度)] [ASC |DESC]) ;
– 方法三:ALTER TABLE在已存在的表上创建索引
ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX
索引名 (字段名[(长度)] [ASC |DESC]) ; – 删除索引:DROP INDEX 索引名 ON
【一线大厂Java面试题解析+后端开发学习笔记+最新架构讲解视频+实战项目源码讲义】
浏览器打开:qq.cn.hn/FTf 免费领取
表名字;
功能测试
========
– 准备表,注意此时表没有设置任何类型的索引
create table s1(
id int,
number varchar(20)
);
– 创建存储过程,实现批量插入记录delimiter − − 声 明 存 储 过 程 的 结 束 符 号 为 -- 声明存储过程的结束符号为 −−声明存储过程的结束符号为 create procedure auto_insert1()
BEGIN
declare i int default 1; – 声明定义变量
while(i < 1000000) do
insert into s1 values
(i,concat(‘第’, i, ‘条记录’));
set i = i + 1;
end while;
END $$ – 存储过程创建完毕delimiter ;-- 调用存储过程,自动插入一百万条数据call auto_insert1();
在无索引的情况下,查找 id 为 567891 的这条记录,耗时 0.03s
mysql> select * from s1 where id = 567891;
±-------±-------------------+| id | number |±-------±-------------------+| 567891 | 第567891条记录 |
±-------±-------------------+1 row in set (0.33 sec)
接下来为 id 字段建立主键索引后再进行查找,耗时为 0.00s


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









