






一、什么是KNN算法?
KNN(K-Nearest Neighbor)算法是机器学习算法中最基础、最简单的算法之一。它既能用于分类,也能用于回归。KNN通过测量不同特征值之间的距离来进行分类。
KNN算法的思想非常简单:对于任意n维输入向量,分别对应于特征空间中的一个点,输出为该特征向量所对应的类别标签或预测值。
KNN算法是一种非常特别的机器学习算法,因为它没有一般意义上的学习过程。它的工作原理是利用训练数据对特征向量空间进行划分,并将划分结果作为最终算法模型。存在一个样本数据集合,也称作训练样本集,并且样本集中的每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。
二、创造自己的数据集
创建的数据集变量有平均一周学习时长、入学以来获得奖学金次数(共3次)、是否参加学术项目研究或学术社团(参加为1,没有参加为0)、对本专业的热爱程度(3分制)
数据集目的是预测大二下期末成绩等级
拥有的数据集如下:
| 平均一周学习时长 | 入学以来获得奖学金次数 | 是否参加学术项目研究或学术社团 | 对本专业的热爱程度 | 期末成绩等级 |
| 15 | 3 | 1 | 3 | 一等 |
| 10 | 1 | 1 | 2 | 一等 |
| 2 | 1 | 0 | 1 | 三等 |
| 2 | 0 | 0 | 1 | 三等 |
| 10 | 3 | 0 | 2 | 一等 |
| 8 | 1 | 0 | 3 | 二等 |
| 8 | 2 | 1 | 3 | 二等 |
| 5 | 0 | 0 | 1 | 三等 |
| 6 | 1 | 0 | 2 | 三等 |
测试的数据集如下:
| 平均一周学习时长 | 入学以来获得奖学金次数 | 是否参加学术项目研究或学术社团 | 对本专业的热爱程度 |
| 12 | 2 | 1 | 3 |
| 2 | 0 | 0 | 2 |
| 7 | 0 | 0 | 2 |
三、代码实现算法
导入拥有的数据集:
def createDataSet() :
# 八组特征
group = np.array([[15,3,1,3],[10,1,1,2],[2,1,0,1],[2,0,0,1],[10,3,0,2],[8,1,0,3],[8,2,1,3],[5,0,0,1],[6,1,0,2]])
# 八组特征的标签
labels = ['一等','一等','三等','三等','一等','二等','二等','三等','三等']
return group, labelsKNN算法主体代码:
def classify(inX,dataSet,labels,k):
dataSetSize=dataSet.shape[0]
diffMat=tile(inX,(dataSetSize,1))-dataSet
sqDiffMat=diffMat**2
sqDistances=sqDiffMat.sum(axis=1)
distances=sqDistances**0.5
sortedDistIndices=distances.argsort()
classCount={}
for i in range(k):
voteIlabel=labels[sortedDistIndices[i]]
classCount[voteIlabel]=classCount.get(voteIlabel,0)+1
sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]导入测试的数据集并进行测试
假设K值为2进行测试:
if __name__ == '__main__':
group, labels = createDataSet()
t1 = classify([12,2,1,3], group, labels, 2)
print('预测到该同学成绩为:',t1)
t2 = classify([2,0,0,2], group, labels, 2)
print('预测到该同学成绩为:', t2)
t3= classify([7,0,0,2], group, labels, 2)
print('预测到该同学成绩为:', t3)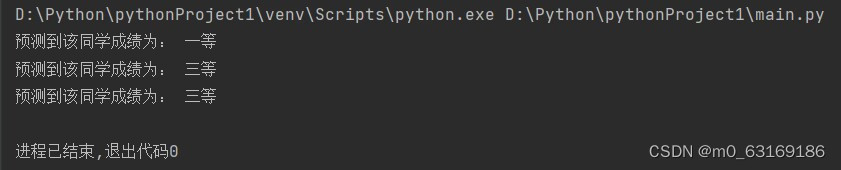
假设K值为3进行测试:
if __name__ == '__main__':
group, labels = createDataSet()
t1 = classify([12,2,1,3], group, labels, 3)
print('预测到该同学成绩为:',t1)
t2 = classify([2,0,0,2], group, labels, 3)
print('预测到该同学成绩为:', t2)
t3= classify([7,0,0,2], group, labels, 3)
print('预测到该同学成绩为:', t3)
四、总结
KNN算法的优点:
- 简单有效
- 重新训练代价低
- 算法复杂度低
- 适用大样本自动分类
KNN算法的缺点:
- 惰性学习
- 类别分类不标准化
- 输出可解释性不强
- 计算量较大

















 3825
3825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









