







 本文记录了作者参加MathorCup数学建模挑战赛的过程,重点介绍了数据清洗的步骤,包括处理空缺值、重复值和异常值,以及使用随机森林进行预测分析。通过对航空安全数据的预处理和模型构建,作者探讨了飞行技术评估和超限原因,并分享了学习心得。
本文记录了作者参加MathorCup数学建模挑战赛的过程,重点介绍了数据清洗的步骤,包括处理空缺值、重复值和异常值,以及使用随机森林进行预测分析。通过对航空安全数据的预处理和模型构建,作者探讨了飞行技术评估和超限原因,并分享了学习心得。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
2023年第十三届MathorCup高校数学建模挑战赛
在学校呆着无聊,参加了这次妈妈杯,学习一下数学建模。
这篇文章仅对我这第一次数学建模的过程做一个记录
以下是本篇文章所对应的题目
D题 航空安全风险分析和飞行技术评估问题
题目文档
提取码:1234
拿到题目后,思路那肯定是没有。
于是从第一题开始一点点学
环境配置
python3.8.5
tensorflow2.4.1
使用的是conda配的环境
一、数据清洗
第一题、第四题都用到了数据清洗,数据清洗主要流程有:处理空缺值、处理重复值、处理异常值
(一)处理空缺值
import missingno as msno
import pandas as pd
import numpy as np
# 读取文件
df = pd.read_csv('1.csv',low_memory=False,na_values='\t')
print(df.isna())
# 缺失值的无效矩阵的数据密集显示
fig1 = msno.matrix(df, labels=True)
b = fig1.get_figure()
b.savefig('a.png', pdi=500) # 保存图片
df.drop_duplicates(keep='first')
#2.清除缺失值
df=df.dropna(how="any", axis=0)
pd.DataFrame.to_csv(path_or_buf='1_2.csv',header=True, index=True,self=df)
all_cloumns=list(df)#获取所有列名
print(all_cloumns)
# 清除缺失值后,缺失值的无效矩阵的数据密集显示
df1 = pd.read_csv('1_2.csv',low_memory=False,na_values='\t')
fig1 = msno.matrix(df1, labels=True)
b = fig1.get_figure()
b.savefig('a_2.png', pdi=500) # 保存图片


处理重复值
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
from scipy import stats
df = pd.read_csv('1.csv')
for columns in df:
# 查看是否有重复值
print(df[columns].nunique())
# 检测重复值
print(df.duplicated()) # 出现为TRUE的则是重复值
# 提取重复值
print(df[df.duplicated()])
# 如果有重复值,则用df.drop_duplicated()方法去重
df=df.drop_duplicated()
pd.DataFrame.to_csv(path_or_buf='1_3.csv', header=True, index=True, self=df)
异常值处理
#查看是否服从正态分布
# pvalue大于0.05则认为数据呈正态分布
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
from scipy import stats
import numpy as np
df = pd.read_csv('1.csv')
mean = df['COG NORM ACCEL'].mean()
std = df['COG NORM ACCEL'].std()
print(stats.kstest(df['COG NORM ACCEL'],'norm',(mean,std)))
print(mean,std)
fig1,axes=plt.subplots(1,1)
sns.distplot(df['COG NORM ACCEL'])#kde和hist默认保留
fig1.savefig('A.png',dpi=500)
#但是并不是正态分布,于是平均值上下四倍的标准值作为界限,去除异常值
a = mean + std*4
b = mean - std*4
df = df[(df['COG NORM ACCEL'] <= a) & (df['COG NORM ACCEL'] >= b)]
pd.DataFrame.to_csv(path_or_buf='1_1_1.csv',header=True, index=True,self=df)
#绘制清洗完的数值分布图
fig1,axes=plt.subplots(1,1)
sns.distplot(df['COG NORM ACCEL'])#kde和hist默认保留
fig1.savefig('A_1.png',dpi=500)
相关度分析
import os
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from scipy import stats
import statsmodels.api as sm
import statsmodels.formula.api as smf
# 导入案例中的数据
df = pd.read_csv('1_1_1.csv')
# df = df[df['Acc'] == 1] # 筛选已开卡数据
# df = df.astype({'avg_exp': 'float64', 'avg_exp_ln': 'float64'}) # 修改字段数据类型
# 连续变量, 共6个
cons_df = df[['COG NORM ACCEL', 'PITCH ATT', 'CAP WHL 1 POSN','CAP CLM 1 POSN', 'WIND SPD(ADIRU)', 'PITCH ATT RATE']]
# 绘制两两间的散点图
fig = plt.figure(figsize=(20, 10))
axs = fig.subplots(6, 6)
for i in range(6):
for j in range(6):
axs[i, j].scatter(cons_df.iloc[:, i], cons_df.iloc[:, j])
plt.show()
df=cons_df.corr()
outputpath='相关性.csv'
df.to_csv(outputpath,sep=',',index=False,header=False)

这里说一下这个图该怎么看,对角线是自己和自己的相关性,当其它适合df[i]的相关性(i=0;i<6;i++)。总之,越趋近于一条y=x的线,就越相关
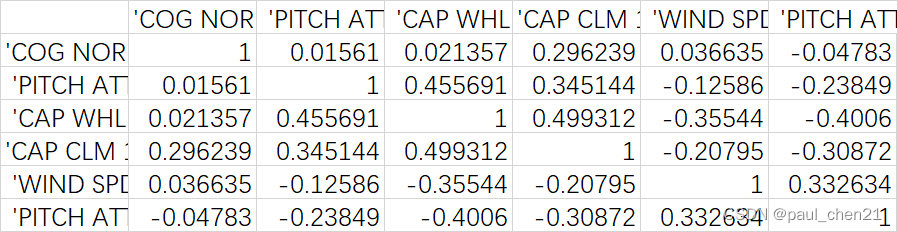
这是相关性系数,越接近1越相关
二、寻找降落时间
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt, ticker
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from scipy import stats
import numpy as np
#选取了两个较相关和一个不相关的三列来绘图
df = pd.read_csv('1ultra.csv',index_col=0)
plt.plot(df['GMT'], df['COG NORM ACCEL']-1, label="X", color="green", marker='*')
plt.plot(df['GMT'], df['PITCH ATT RATE'], label="X", color="blue", marker='*')
plt.plot(df['GMT'], df['CAP CLM 1 POSN'], label="X", color="orange", marker='*')
plt.legend() # 显示图例
plt.ylabel('time cost')
plt.show()
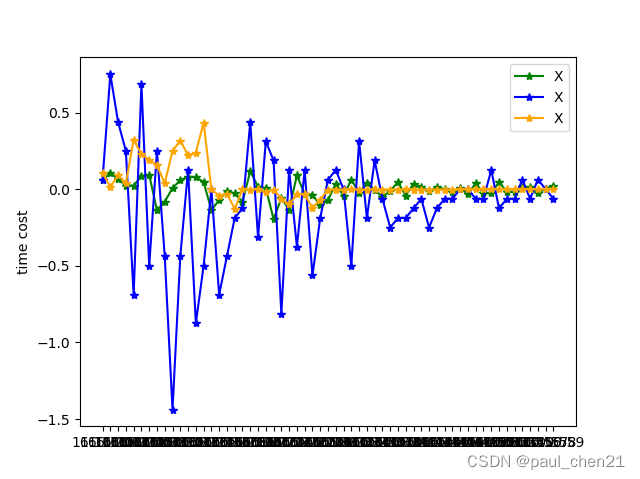
可见在16:10左右落地,找到落地点后可以删去多余的数据,使得图像聚焦在降落时刻
三、超限原因
分析飞机在哪些航线或者在哪些机场容易出现何种超限
这题主要是用excel做的,数据透视表。
一些图片
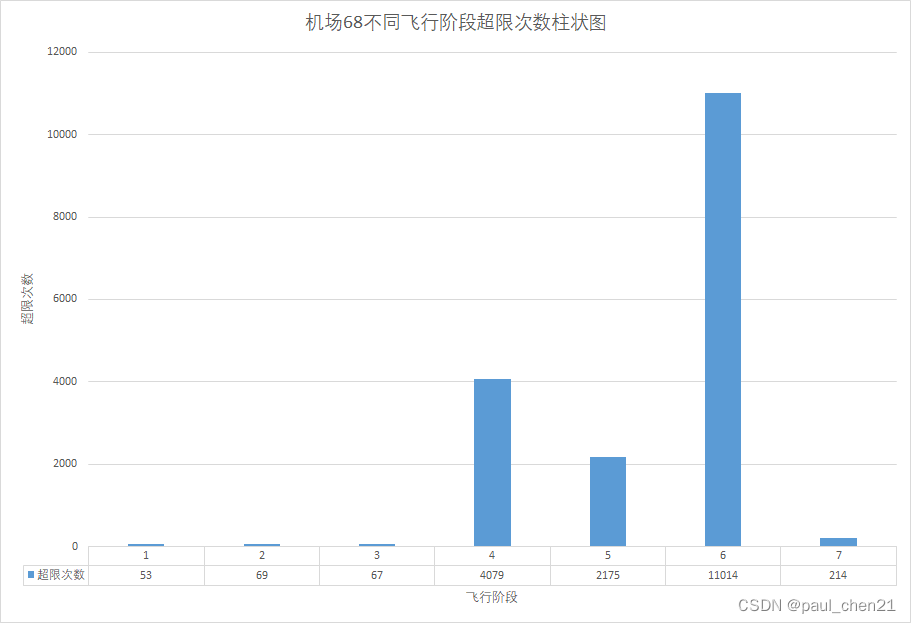
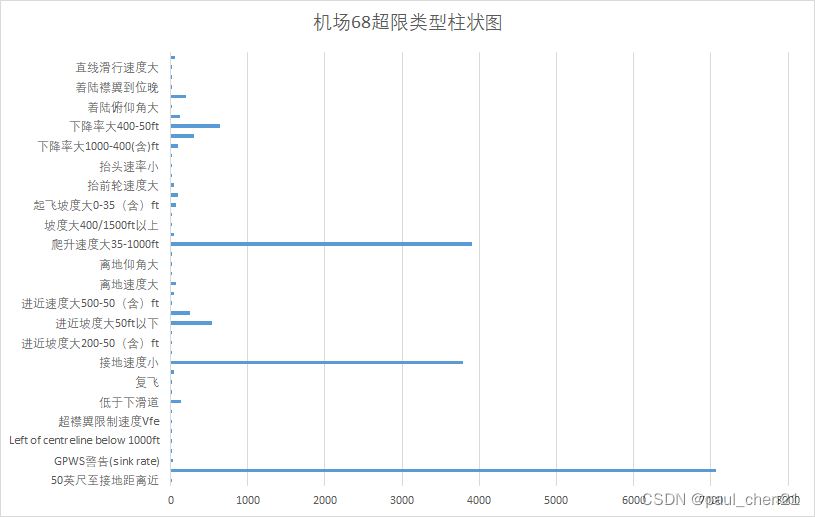
四、随机森林
好了,前面仅仅是一些处理,这个是真的难
资质一共有六类,用one-hot进行编码,得到一个6*6的矩阵
数据集前一半训练,后一半测试
import pybaobabdt
import pydot
import numpy as np
import pandas as pd
import scipy.stats as stats
import matplotlib.pyplot as plt
from sklearn import metrics
from openpyxl import load_workbook
from sklearn.tree import export_graphviz
from sklearn.ensemble import RandomForestRegressor
import os
import glob
import openpyxl
import numpy as np
import pandas as pd
import seaborn as sns
import tensorflow as tf
import scipy.stats as stats
import matplotlib.pyplot as plt
from sklearn import metrics
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import regularizers
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.layers.experimental import preprocessing
from sklearn.preprocessing import OneHotEncoder
from sklearn import tree
from sklearn.datasets import load_wine
import pydotplus
train_data_path = 'TrainData.csv'
test_data_path = 'TestData.csv'
write_excel_path = 'ParameterResult_ML.xlsx'
tree_graph_dot_path = 'tree.dot'
tree_graph_png_path = 'tree.png'
random_seed = 44
random_forest_seed = np.random.randint(low=1, high=230)
# LoadData函数,加载全部数据
def LoadData(DataPath):
MyData = pd.read_csv(DataPath) # 加载DataPath路径所指定的数据,names中的内容为各列的名称
return MyData
# 初始数据处理,需要先把csv中含有,,的数据把,,去掉
MyData = LoadData("附件3:飞行参数测量数据.csv") # 调用LoadData函数,获取数据
# MyData = MyData.dropna(how="any", axis=0)
MyData = MyData.dropna(how="all", axis=1)
pd.DataFrame.to_csv(path_or_buf='1.csv', header=True, index=True, self=MyData, encoding="GBK")
MyData.head(5)
#进行one-hot编码
ohe = OneHotEncoder(handle_unknown='ignore')
# print(ohe.fit(MyData))
# print(ohe.categories_)
ohe_column = pd.get_dummies(MyData['落地主操控人员资质'],prefix='落地主操控人员资质')
print(ohe_column)
# count=pd.DataFrame(MyData['落地主操控人员资质'].value_counts())
# print(count)
# test_data_1
test_data_1=MyData.drop(['落地主操控人员资质'," V2_Method"," Vref_Method"," RoD_Method"," MACH_Method"],axis=1)
print(test_data_1)
test_data_1=test_data_1.join(ohe_column)#将不该要的列删掉,把one-hot编码加在最后
# test_data_1 = test_data_1.dropna(how="any", axis=0)
test_data_1 = test_data_1.dropna(how="all", axis=1)
print(test_data_1)
pd.DataFrame.to_csv(path_or_buf='1.csv',header=True, index=True,self=test_data_1,encoding="GBK")
TrainData=test_data_1.sample(frac=0.5,random_state=21)
pd.DataFrame.to_csv(path_or_buf='TrainData.csv',header=True, index=True,self=TrainData,encoding="GBK")
TestData=test_data_1.drop(TrainData.index)
pd.DataFrame.to_csv(path_or_buf='TestData.csv',header=True, index=True,self=TestData,encoding="GBK")
print(TestData)
#以上都是在对数据进行预处理
train_data = pd.read_csv(train_data_path, header=0, encoding="gbk", nrows=162)
test_data = pd.read_csv(test_data_path, header=0, encoding="gbk", nrows=162)
# Separate independent and dependent variables
train_Y = np.array(
train_data.loc[:, ['落地主操控人员资质_A', '落地主操控人员资质_C', '落地主操控人员资质_F', '落地主操控人员资质_J', '落地主操控人员资质_M', '落地主操控人员资质_T']])
train_X = train_data.drop(
['机型', '落地主操控', '落地主操控人员资质_A', '落地主操控人员资质_C', '落地主操控人员资质_F', '落地主操控人员资质_J', '落地主操控人员资质_M', '落地主操控人员资质_T'], axis=1)
#将训练集分为特征和标签
train_X.fillna(train_X.mean(), inplace=True) # 填充均值,结果他还有空值,我服了
#
train_Y_column_name = list(train_Y)
train_X_column_name = list(train_X.columns)
train_X = np.array(train_X)
print(train_Y_column_name)
test_Y = np.array(
test_data.loc[:, ['落地主操控人员资质_A', '落地主操控人员资质_C', '落地主操控人员资质_F', '落地主操控人员资质_J', '落地主操控人员资质_M', '落地主操控人员资质_T']])
test_X = test_data.drop(
['机型', '落地主操控', '落地主操控人员资质_A', '落地主操控人员资质_C', '落地主操控人员资质_F', '落地主操控人员资质_J', '落地主操控人员资质_M', '落地主操控人员资质_T'], axis=1)
#将测试集分为特征和标签
test_X.fillna(test_X.mean(), inplace=True) # 填充均值
test_X = np.array(test_X)
# Build RF regression model
print(train_X.shape)
print(train_Y.shape)
print(test_Y.shape)
# test_Y = np.transpose(test_Y)
# test_X = np.transpose(test_X)
# print(test_Y.shape) # 输出结果应为(6,1183)
# train_X = np.dot(train_X, test_X)
# test_Y = np.dot(train_Y, test_Y)
print(train_X.shape)
print(test_X.shape)
print(test_Y.shape) # 输出结果应为(6,1183)
random_forest_model = RandomForestRegressor(n_estimators=200, random_state=0)
random_forest_model.fit(train_X, train_Y)
print(random_forest_model.score(test_X, test_Y))
#这里可以可视化随机森林的决策过程
# Estimators = random_forest_model.estimators_
# for index, model in enumerate(Estimators):
# filename = 'iris_' + str(index) + '.pdf'
# dot_data = tree.export_graphviz(model , out_file=None,
# special_characters=True)
# graph = pydotplus.graph_from_dot_data(dot_data)
# graph.write_pdf(filename)
# Predict test set data
random_forest_predict = random_forest_model.predict(test_X)
random_forest_error = random_forest_predict - test_Y
# Draw test plot
plt.figure(1)
plt.clf()
ax = plt.axes(aspect='equal')
plt.scatter(test_Y, random_forest_predict, c='green')
plt.xlabel('test_Y')
plt.ylabel('random_forest_predict')
Lims = [0, 1.5]
plt.xlim(Lims)
plt.ylim(Lims)
plt.plot(Lims, Lims)
plt.grid(False)
plt.figure(2)
plt.clf()
plt.hist(random_forest_error)
plt.xlabel('Prediction Error')
plt.ylabel('Count')
plt.grid(False)
plt.show()
# Verify the accuracy
# random_forest_pearson_r = stats.pearsonr(test_Y, random_forest_predict)
random_forest_R2 = metrics.r2_score(test_Y, random_forest_predict)
random_forest_RMSE = metrics.mean_squared_error(test_Y, random_forest_predict) ** 0.5
print('and RMSE is {0}.'.format(random_forest_RMSE))
# Save key parameters
excel_file = load_workbook(write_excel_path)
excel_all_sheet = excel_file.sheetnames
excel_write_sheet = excel_file[excel_all_sheet[0]]
# excel_write_sheet = excel_file.active
max_row = excel_write_sheet.max_row
excel_write_content = [random_forest_R2, random_forest_RMSE, random_seed,
random_forest_seed]
for i in range(len(excel_write_content)):
exec("excel_write_sheet.cell(max_row+1,i+1).value=excel_write_content[i]")
excel_file.save(write_excel_path)
于是得到了这两张图
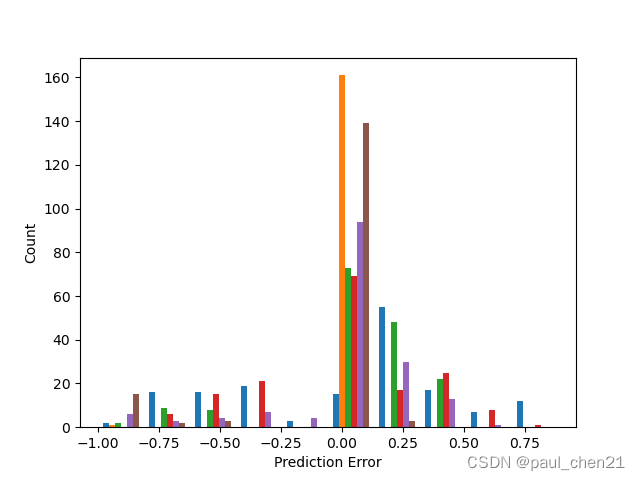
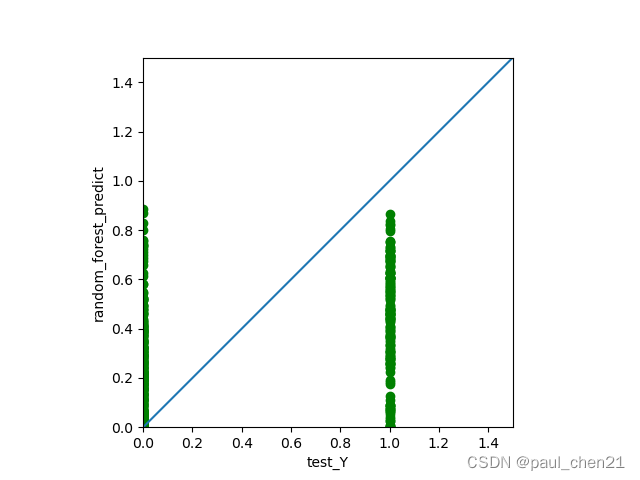
不过我做的正确率较低,只有20.4%的正确率
总结
第五题随便水过去了
不过前四个题至少让我熟练了数据清洗…
期待下次比赛



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











