







文章目录
1、NLP文本处理

NLP的目标
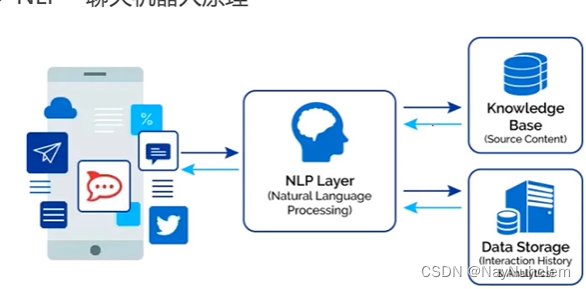
聊天机器人的主要目标是准确理解和解释用户输入。NLP 在此过程中发挥着至关重要的作用,它使聊天机器人能够理解并提取人类语言的含义。NLP 算法采用标记化、句法分析和语义解析等技术将用户消息分解为有意义的组件。通过破译用户查询的意图和上下文,聊天机器人可以提供适当的响应,从而实现更有效、更自然的对话。
NLP-聊天机器人的原理
核心原理是利用 机器学习 和 深度学习 算法,对大量的语料库进行训练和学习,从而实现对自然语言的理解和生成。
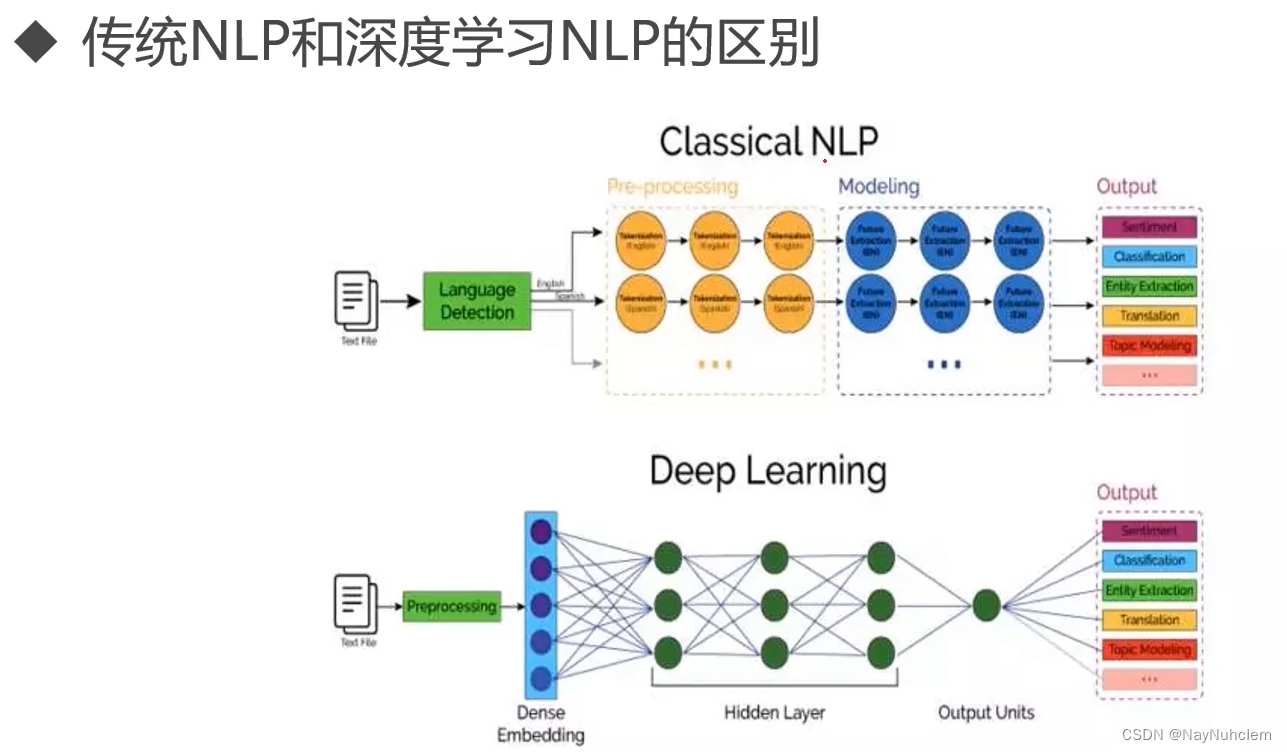
传统nlp与深度学习nlp的区别
输入没有区别,而深度学习nlp在网络结构做了一个预处理,同时深度学习NLP主要依赖于神经网络和大规模数据,而传统NLP则主要依赖于规则和手工工程。
2、文本处理方法
文本处理方法处理前面的TF-IDF,Jieba分词,还有Onehot(独热编码),Onehot(独热编码)可以将类别变量转换为数字型变量(变得稀疏)如下图。
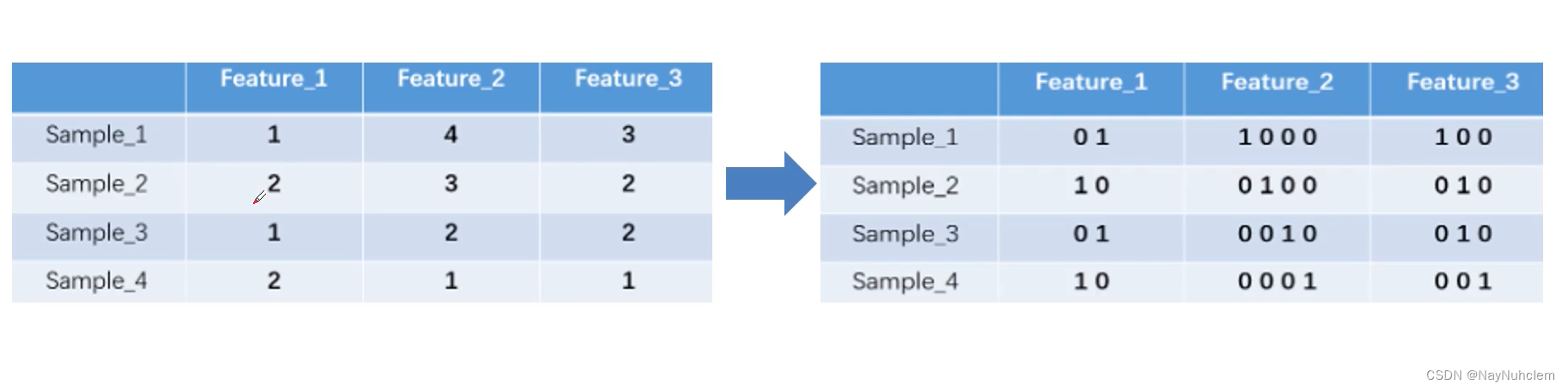

当词特别多时,那么编码维度非常大,计算量也会很大。一般我们会采用新的文本处理方法Word2vec和Stopwords,Word2vec把每一个词映射成一个二维向量,该向量就代表这个词。Stopwords:停用词是指搜索引擎已编程忽略的常用词(例如“the”,“a”,“an”,“in”)

3、Word2Vec
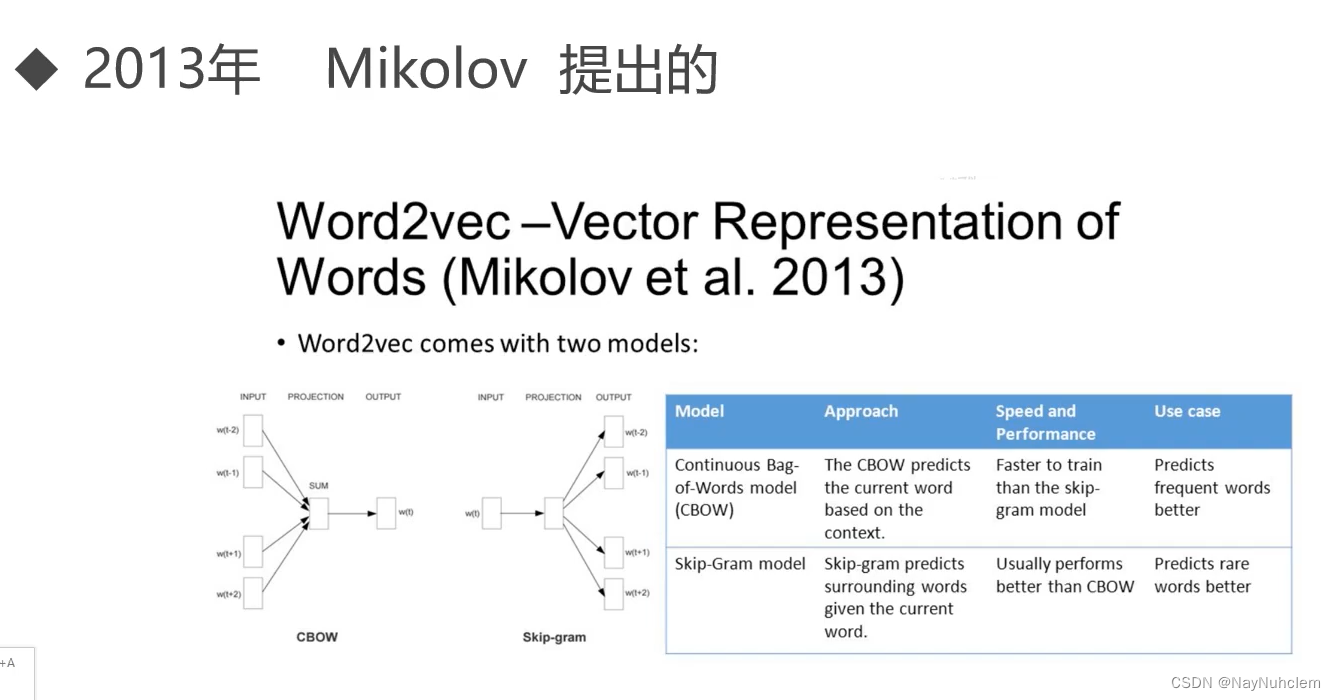
3.1word2vec模式下的两个模型:CBOW和SkipGram
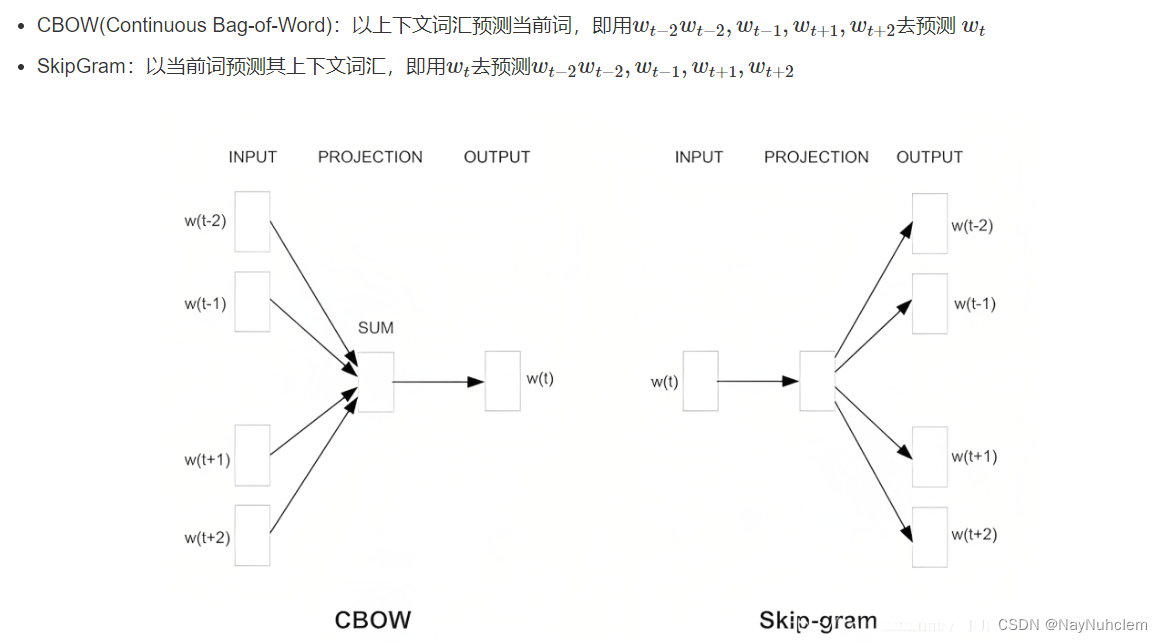

Word2Vec用神经网络把词转成向量的模型。
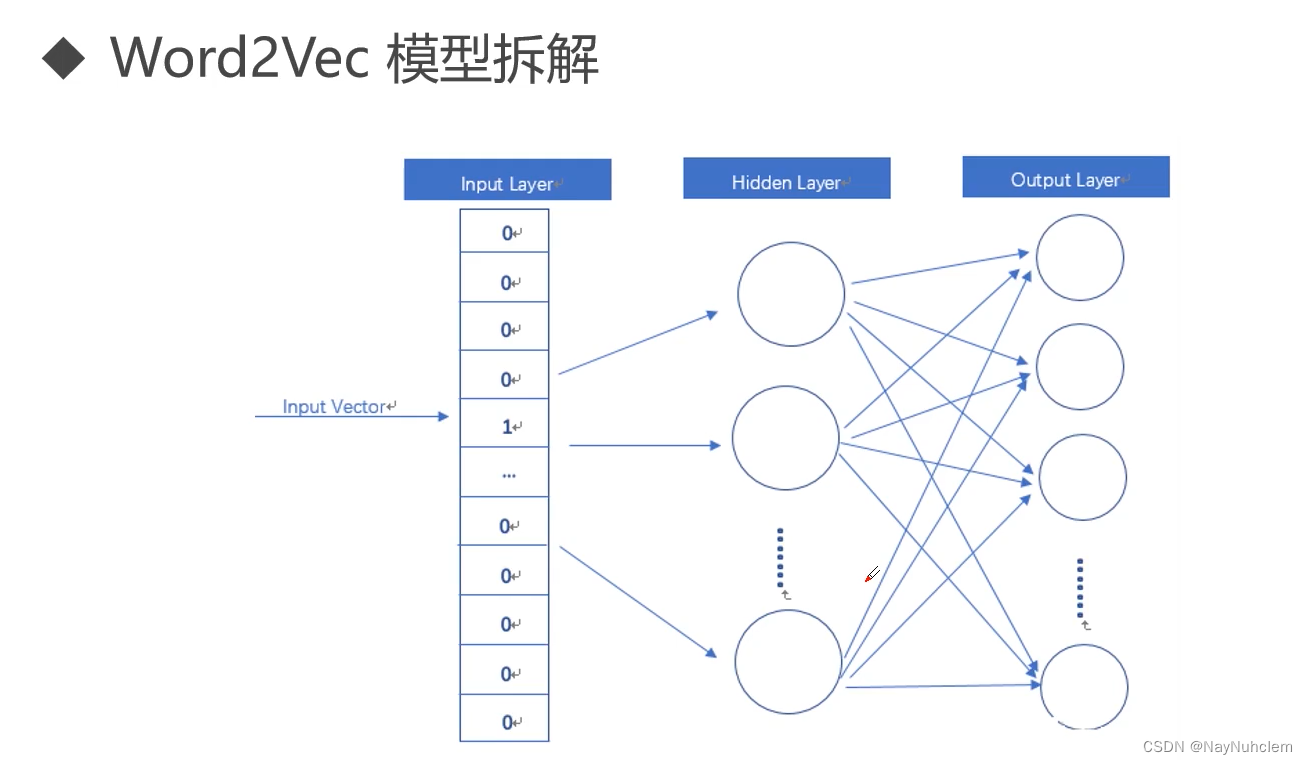
3.2word2vec模式分解
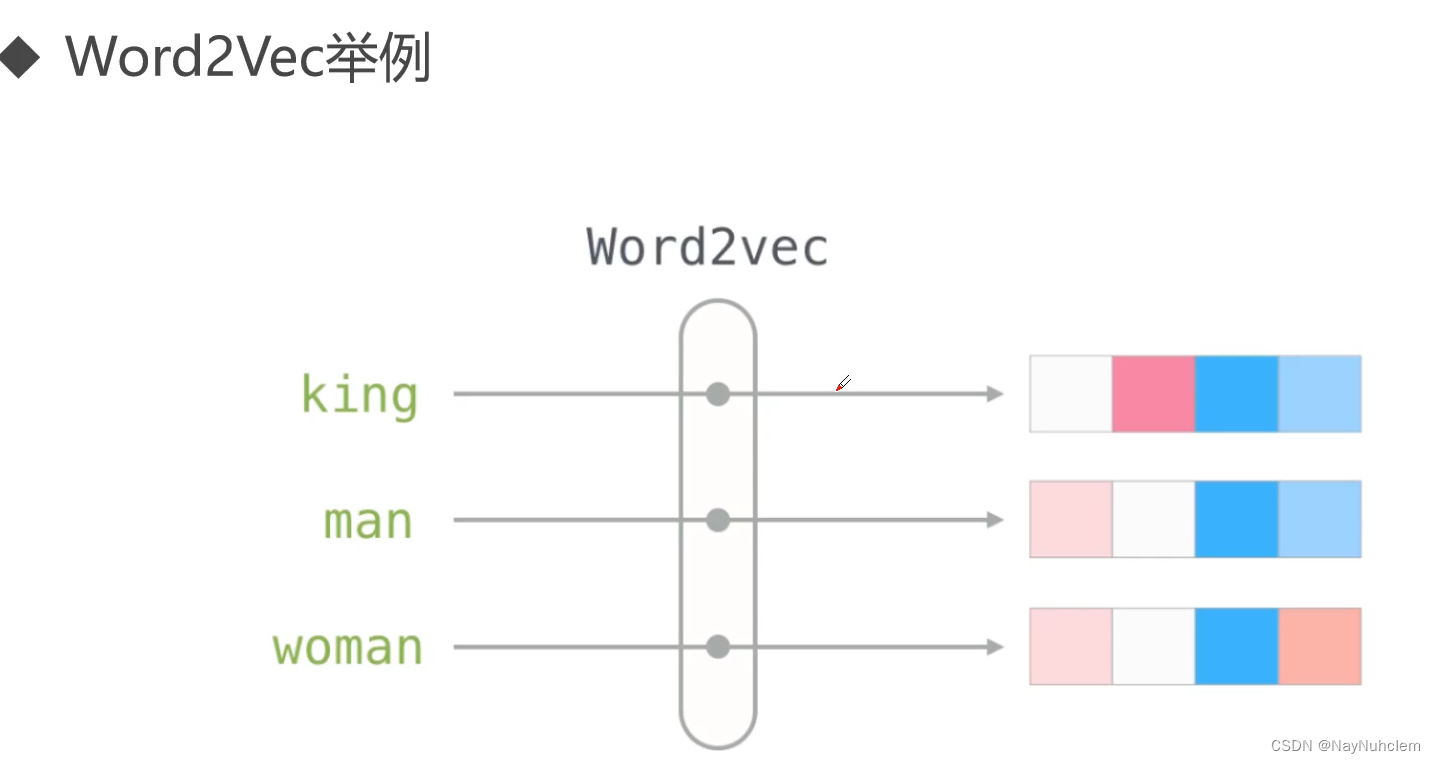
3.3word2vec发展

3.4word2vec的不足

3.5word2vec的改进
但是在平时中使用word2vec更多
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









