







数据集
目标
知道数据集分为训练集和测试集
会使用sklearn的数据集
可用数据集
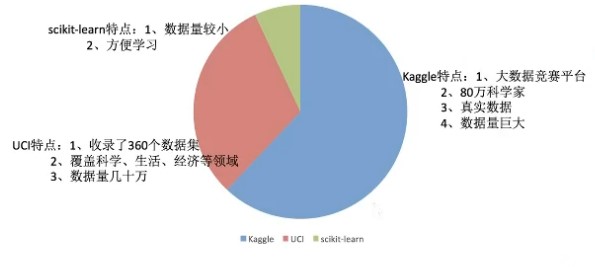
scikit-learn:https://scikit-learn.org/dev/preface.html
UCI数据集网站:https://archive.ics.uci.edu/ml/index.php
sklearn数据集
scikit-lear数据集API
sklearn.datasets
-
加载获取流行数据集
-
dataset.load_*() *代表数据集的名字
获取小规模数据集,数据包含在datasets里
-
datasets.fetch_*(data_home = None)
获取大规模数据集,需要从网络上下载,data_home 表示数据集下载的目录,默认是~/scikit_learn_data/
sklearn小数据集
举例:
鸢尾花数据集
sklearn.datasets.load_iris()
加载并返回鸢尾花数据集
| 名称 | 数量 |
|---|---|
| 类别 | 3 |
| 特征 | 4 |
| 样本数量 | 150 |
| 每个类别数量 | 50 |
波士顿房价数据集
sklearn.datasets.load_boston()
加载并返回波士顿房价数据集
| 名称 | 数量 |
|---|---|
| 目标类别 | 5-50 |
| 特征 | 13 |
| 样本数量 | 506 |
sklearn大数据集
sklearn数据集的使用
以鸢尾花数据集为例

sklearn数据集返回值
load和fetch返回的数据类型datasets.base.Bunch(继承自字典)
dict["key"] = values
bunch.key = values
- data:特征数据数组(特征值),是
- target:标签数组
- DESCR:数据描述
- feature_names:特征值
- target_names:标签名
from sklearn.datasets import load_iris
def datasets_demo():
#sklearn数据集的使用
#获取数据集
iris = load_iris()
print("鸢尾花数据集:\n",iris)
print("查看数据集描述:\n",iris["DESCR"])
print("查看特征值的名字:\n",iris.feature_names)
print("查看特征值:\n",iris.data,iris.data.shape)
print("查看目标值:\n",iris.target)
print("查看目标值的名字:\n",iris.target_names)
print("鸢尾花的描述:\n",iris.DESCR)
return None
if __name__ == "__main__":
datasets_demo()
数据集的划分
训练数据:用于训练、构建模型
测试数据:在模型检验时使用,用于评估模型是否有效
训练与测试 比例是 73 / 82
数据集划分api
| 训练集特征值 | 测试集特征值 | 训练集目标值 | 测试集目标值 |
|---|---|---|---|
| x_train | x_test | y_train | y_test |
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
def datasets_demo():
#获取数据集
iris = load_iris()
# 数据集的划分
x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.2,random_state=22,shuffle=False)
print("训练集的特征值:\n",x_train,x_train.shape) #测试数据占比0.2,训练数据则占比0.8
return None #random_state 代表随机种子编号 , shuffle代表 是否放回抽样
if __name__ == "__main__":
datasets_demo()



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









