







 文章介绍了SqueezeNet,一种旨在减少参数和计算需求的轻量级网络结构,通过FireModule的1x1和3x3卷积实现高效性能。文章详细阐述了FireModule的设计,比较了不同版本的SqueezeNet特点,并探讨了其在资源有限环境中的优势。
文章介绍了SqueezeNet,一种旨在减少参数和计算需求的轻量级网络结构,通过FireModule的1x1和3x3卷积实现高效性能。文章详细阐述了FireModule的设计,比较了不同版本的SqueezeNet特点,并探讨了其在资源有限环境中的优势。
简介
SqueezeNet是一种轻量级卷积神经网络架构,旨在保持较高性能的同时减少模型的参数数量和计算复杂度。由于其小尺寸和高效性能,SqueezeNet适用于在资源受限的环境中部署,如移动设备和嵌入式系统。
SqueezeNet是通过使用一种"Fire Module"的结构来减小网络的深度和参数量。Fire Module包含一个称为"Squeeze"层和一个称为"Expand"层的组合。"Squeeze"层主要执行特征压缩,通过使用1x1卷积核来减小通道数量,从而降低模型的参数数量。"Expand"层使用1x1和3x3卷积核来增加通道数量,以产生更丰富的特征表示。
整个SqueezeNet网络由多个这样的Fire Modules组成,其中间使用了池化层来减小空间尺寸。
论文地址:https://arxiv.org/abs/1602.07360
Fire Module
它的结构图如下所示:
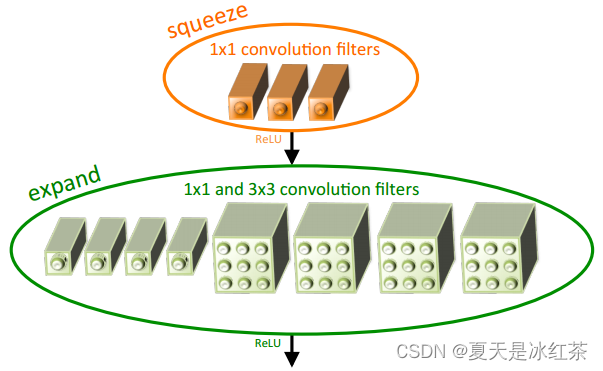
Fire 模块它是通过使用 1x1 的卷积核来进行压缩。1x1 卷积可以降低输入特征图的通道数,从而减少每个位置上的参数数量。如果一个模型中有很多层使用了 1x1 卷积,整个模型的参数数量会相对较小。同时,1x1 卷积通常比较轻量级,计算量相对较小。这也就意味着计算复杂度的减小,因为计算复杂度与参数数量相关。最后将经过不同卷积操作得到的特征在通道维度上拼接在一起。
class Fire(nn.Module):
def __init__(self, inplanes, squeeze_planes, expand1x1_planes, expand3x3_planes):
super(Fire, self).__init__()
self.inplanes = inplanes
self.squeeze = nn.Conv2d(inplanes, squeeze_planes, kernel_size=1)
self.expand1x1 = nn.Conv2d(squeeze_planes, expand1x1_planes,
kernel_size=1)
self.expand3x3 = nn.Conv2d(squeeze_planes, expand3x3_planes,
kernel_size=3, padding=1)
self.activation = nn.ReLU(inplace=True)
def forward(self, x):
x = self.activation(self.squeeze(x))
return torch.cat([
self.activation(self.expand1x1(x)),
self.activation(self.expand3x3(x))
], dim=1)我想大家使用Conv+BN+ReLU使用习惯了,这里面没有使用BN是因为会引入额外的参数和计算,像这种轻量级的网络结构中,可能不太需要 BN 层,因为模型本身较浅,梯度的变化也不会过于剧烈。
SqueezeNet的两个版本的特点
以下是一些个人的见解:
卷积核的大小和步幅,在1_0版本当中第一个卷积层使用的是核大小为7,而1_1版本当中的卷积核为3,这可能导致更大的感受野。
输出通道数,在1_0版本中,第一个卷积层输出通道为 96,而1_1版本中为 64。这也意味着1_1版本的模型整体更加轻量。1_0 Total params: 737,476,1_1 Total params: 724,548
采用了 Dropout 在训练期间有助于防止过拟合。
class SqueezeNet(nn.Module):
def __init__(self, version='1_0', num_classes=1000):
super(SqueezeNet, self).__init__()
self.num_classes = num_classes
if version == '1_0':
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=7, stride=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(96, 16, 64, 64),
Fire(128, 16, 64, 64),
Fire(128, 32, 128, 128),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(256, 32, 128, 128),
Fire(256, 48, 192, 192),
Fire(384, 48, 192, 192),
Fire(384, 64, 256, 256),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(512, 64, 256, 256),
)
elif version == '1_1':
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(64, 16, 64, 64),
Fire(128, 16, 64, 64),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(128, 32, 128, 128),
Fire(256, 32, 128, 128),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(256, 48, 192, 192),
Fire(384, 48, 192, 192),
Fire(384, 64, 256, 256),
Fire(512, 64, 256, 256),
)
else:
raise ValueError("Unsupported SqueezeNet version {version}:"
"1_0 or 1_1 expected".format(version=version))
# Final convolution is initialized differently from the rest
final_conv = nn.Conv2d(512, self.num_classes, kernel_size=1)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
final_conv,
nn.ReLU(inplace=True),
nn.AdaptiveAvgPool2d((1, 1))
)
for m in self.modules():
if isinstance(m, nn.Conv2d):
if m is final_conv:
init.normal_(m.weight, mean=0.0, std=0.01)
else:
init.kaiming_uniform_(m.weight)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return torch.flatten(x, 1)结构图如下所示:
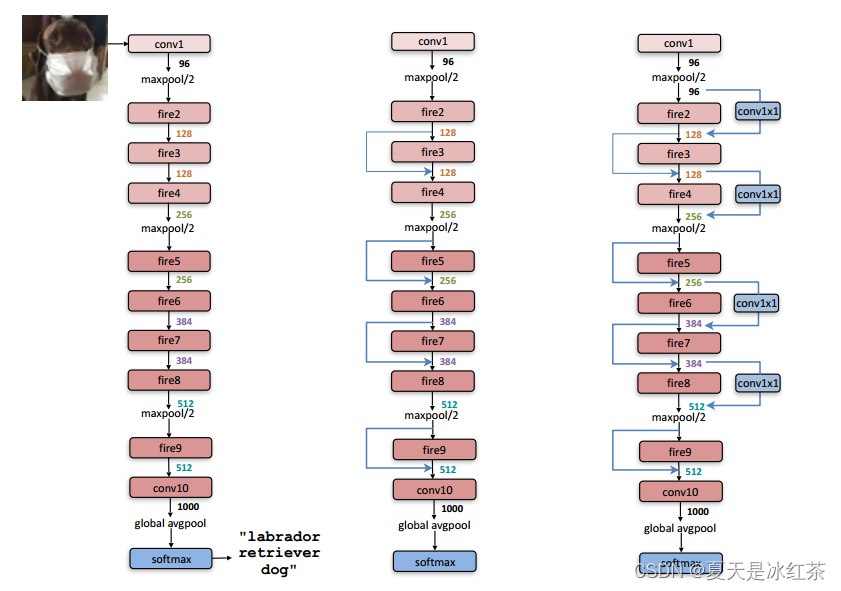
下面是论文作者提供的一些细节和设计的选择
- 1x1和3x3滤波器的输出尺寸一致性:为了确保1x1和3x3滤波器的输出在高度和宽度上一致,作者在expand模块的3x3滤波器的输入数据周围添加了1像素的零填充。
- 激活函数的选择:使用了ReLU作为squeeze和expand层的激活函数。
- Dropout的应用:在fire9模块之后应用了Dropout,丢弃率为50%。
- 无全连接层:SqueezeNet没有使用全连接层,这个设计灵感来源于NiN(Lin et al., 2013)架构。
- 学习率和训练策略:在训练SqueezeNet时,初始学习率为0.04,通过线性递减学习率的方式进行训练。
我感觉它给出的这些放在现在看来都比较的常规了(当时可能比较新颖),现在也有很多的其他方式去和技术去提升。
SqueezeNet分类实验测试
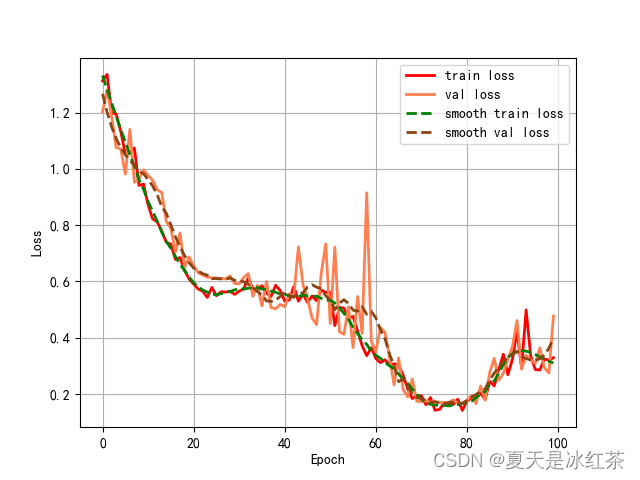
100轮训练和验证损失记录
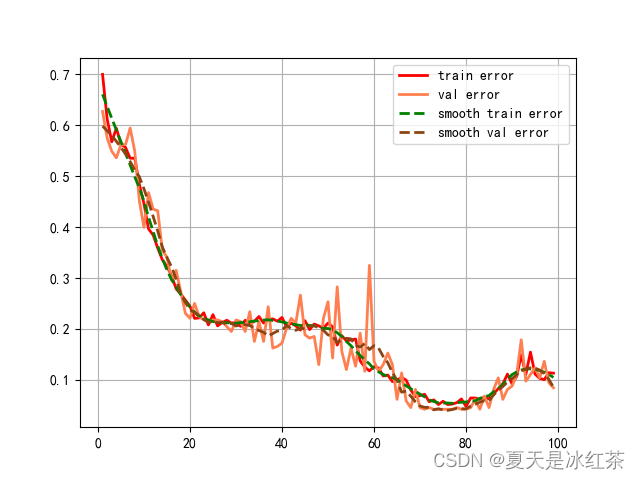
100轮错误率记录

验证集记录最佳的指标
总结
SqueezeNet相对于传统的深层CNN模型,如VGG或ResNet,具有更小的模型大小和更少的参数,但在一些任务上仍能取得不错的性能。这使得SqueezeNet成为在资源受限环境中进行实时图像分类等应用的有力选择。
目前我也是在学习的阶段,学习这一部分也是为了积累轻量化模型的方法,因为因为轻量化模型在移动设备、嵌入式系统以及一些资源受限的环境中都具有重要的应用价值。


















 1188
1188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











