




一、贝叶斯分类理论
贝叶斯分类理论是基于贝叶斯定理(Bayes' Theorem)的一种统计分类方法,广泛应用于机器学习和数据挖掘领域。它通过计算概率来进行分类,特别适合处理高维数据(如文本分类、垃圾邮件过滤等)。
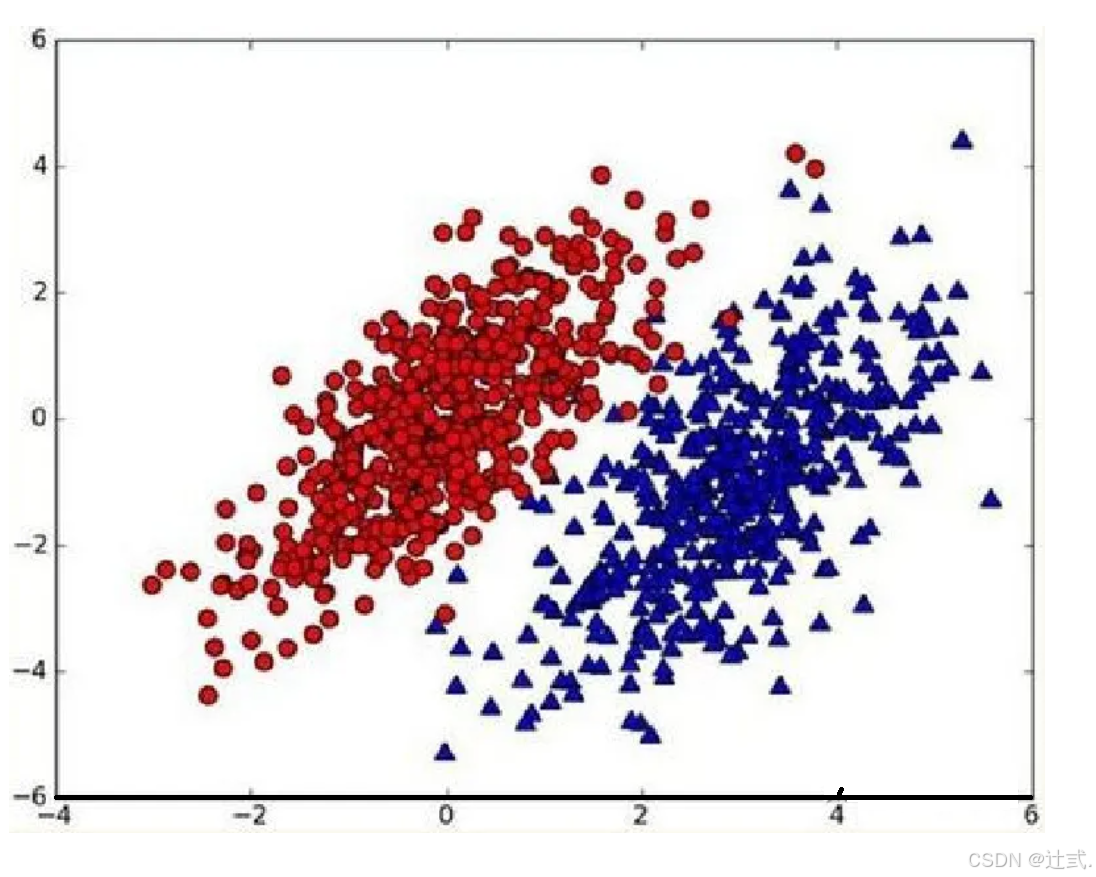
我们现在用p1(x,y)表示数据点(x,y)属于类别1(图中红色圆点表示的类别)的概率,用p2(x,y)表示数据点(x,y)属于类别2(图中蓝色三角形表示的类别)的概率,那么对于一个新数据点(x,y),可以用下面的规则来判断它的类别:
- 如果p1(x,y)>p2(x,y),那么类别为1
- 如果p1(x,y)<p2(x,y),那么类别为2
也就是说,我们会选择高概率对应的类别。这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。已经了解了贝叶斯决策理论的核心思想,那么接下来,就是学习如何计算p1和p2概率。
二、条件概率
1、条件概率的定义:
条件概率 P(xi∣Y) 表示在类别 YY 已知的情况下,特征 xixi 出现的概率。用公式表示为:
P(xi∣Y)=P(xi∩Y)/P(Y)
其中:
-
P(xi∩Y) 是特征 xi和类别 Y 同时发生的联合概率。
-
P(Y)是类别 Y的先验概率。
在朴素贝叶斯中,条件概率用于计算在给定类别下,所有特征联合出现的概率。
2、条件概率的计算:
条件概率的计算依赖于训练数据。以下是常见的计算方法:
(1)离散特征
对于离散特征(如文本分类中的单词出现与否),条件概率可以通过频率估计:

示例:
假设我们有一个文本分类任务,判断邮件是否为垃圾邮件。特征为单词“免费”是否出现。
-
在垃圾邮件中,“免费”出现了 10 次,总单词数为 100。
-
则条件概率为:

(2)连续特征
对于连续特征(如身高、体重),通常假设特征服从某种概率分布(如高斯分布),然后通过概率密度函数计算条件概率。
高斯分布下的条件概率:
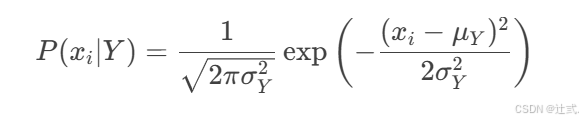
其中:
-
μY 是类别 Y下特征 xi 的均值。
-
σY 是类别 Y下特征 xi 的标准差。
三、全概率公式
除了条件概率以外,在计算p1和p2的时候,还要用到全概率公式,因此,这里继续推导全概率公式。假定样本空间S,是两个事件A与A'的和。
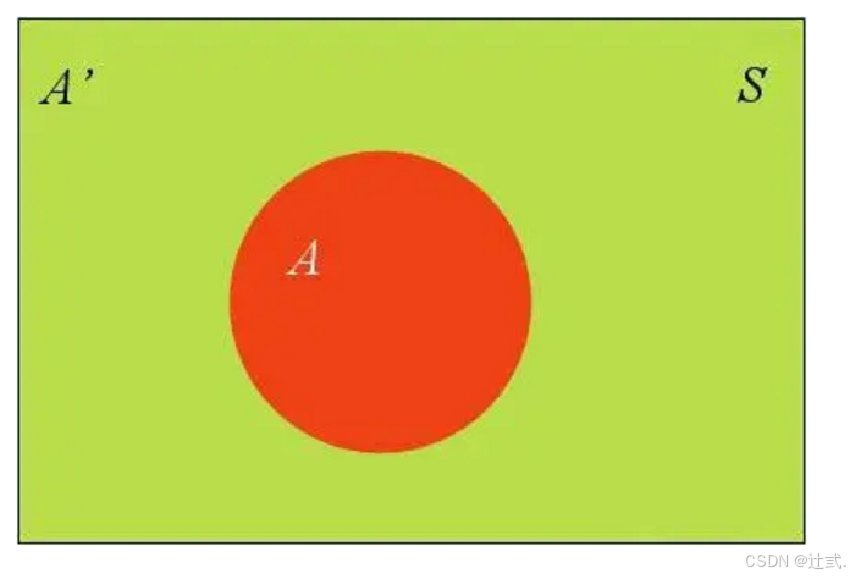
上图中,红色部分是事件A,绿色部分是事件A',它们共同构成了样本空间S。
在这种情况下,事件B可以划分成两个部分。
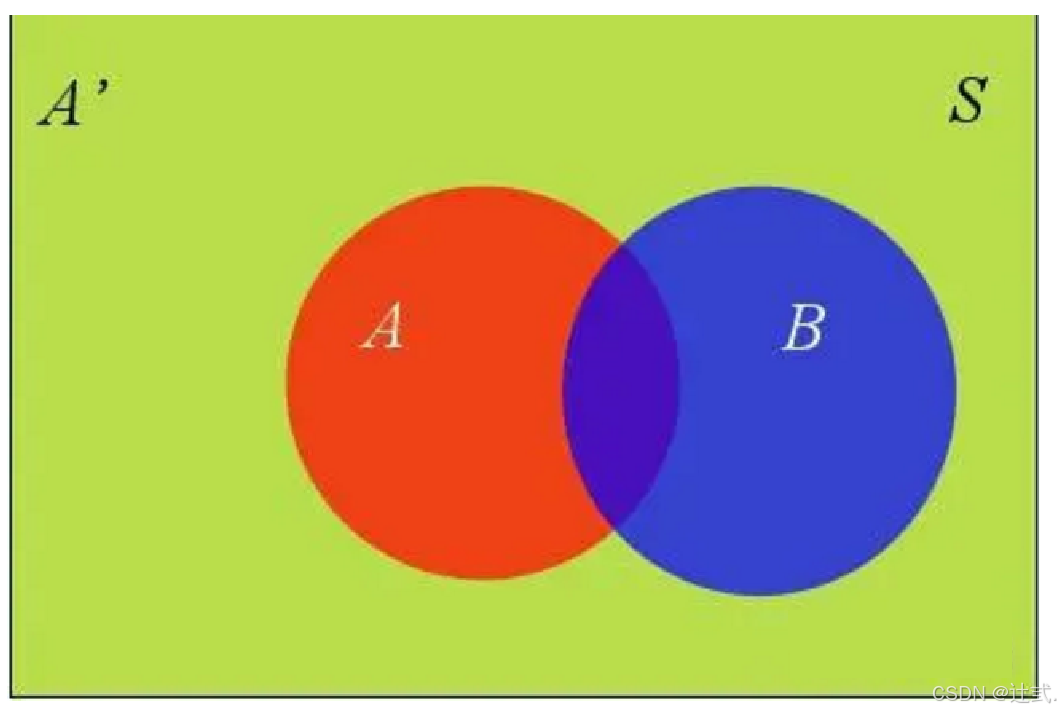
即:
𝑃(𝐵)=𝑃(𝐵∩𝐴)+𝑃(𝐵∩𝐴′)
在上面的推导当中,我们已知
𝑃(𝐵∩𝐴)=𝑃(𝐵|𝐴)𝑃(𝐴)
所以:
𝑃(𝐵)=𝑃(𝐵|𝐴)𝑃(𝐴)+𝑃(𝐵|𝐴′)𝑃(𝐴′)
这就是全概率公式。它的含义是,如果A和A'构成样本空间的一个划分,那么事件B的概率,就等于A和A'的概率分别乘以B对这两个事件的条件概率之和。
将这个公式代入上一节的条件概率公式,就得到了条件概率的另一种写法:
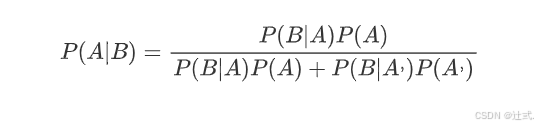
四、贝叶斯推断
对条件概率公式进行变形,可以得到如下形式:
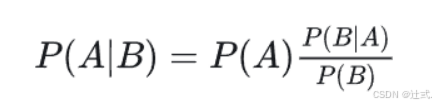
我们把P(A)称为"先验概率"(Prior probability),即在B事件发生之前,我们对A事件概率的一个判断。
P(A|B)称为"后验概率"(Posterior probability),即在B事件发生之后,我们对A事件概率的重新评估。
P(B|A)/P(B)称为"可能性函数"(Likelyhood),这是一个调整因子,使得预估概率更接近真实概率。
所以,条件概率可以理解成下面的式子:
后验概率 = 先验概率x调整因子
这就是贝叶斯推断的含义。我们先预估一个"先验概率",然后加入实验结果,看这个实验到底是增强还是削弱了"先验概率",由此得到更接近事实的"后验概率"。
五、朴素贝叶斯推断
理解了贝叶斯推断,那么让我们继续看看朴素贝叶斯。贝叶斯和朴素贝叶斯的概念是不同的,区别就在于“朴素”二字,朴素贝叶斯对条件概率分布做了条件独立性的假设。 比如下面的公式,假设有n个特征:
根据贝叶斯定理,后验概率 P(a|X) 可以表示为:
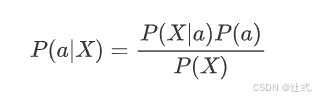
其中:
-
P(X|a) 是给定类别 ( a ) 下观测到特征向量 $X=(x_1, x_2, ..., x_n) $的概率;
-
P(a) 是类别 a 的先验概率;
-
P(X) 是观测到特征向量 X 的边缘概率,通常作为归一化常数处理。
朴素贝叶斯分类器的关键假设是特征之间的条件独立性,即给定类别 a ,特征 xi 和 xj (其中 i != j 相互独立。)
因此,我们可以将联合概率 P(X|a) 分解为各个特征的概率乘积:
将这个条件独立性假设应用于贝叶斯公式,我们得到:
这样,朴素贝叶斯分类器就可以通过计算每种可能类别的条件概率和先验概率,然后选择具有最高概率的类别作为预测结果。
这样我们就可以进行计算了。如果有些迷糊,让我们从一个例子开始讲起,你会看到贝叶斯分类器很好懂,一点都不难。
| 纹理 | 色泽 | 鼔声 | 类别 | |
|---|---|---|---|---|
| 1 | 清晰 | 清绿 | 清脆 | 好瓜 |
| 2 | 模糊 | 乌黑 | 浊响 | 坏瓜 |
| 3 | 模糊 | 清绿 | 浊响 | 坏瓜 |
| 4 | 清晰 | 乌黑 | 沉闷 | 好瓜 |
| 5 | 清晰 | 清绿 | 浊响 | 好瓜 |
| 6 | 模糊 | 乌黑 | 沉闷 | 坏瓜 |
| 7 | 清晰 | 乌黑 | 清脆 | 好瓜 |
| 8 | 模糊 | 清绿 | 沉闷 | 好瓜 |
| 9 | 清晰 | 乌黑 | 浊响 | 坏瓜 |
| 10 | 模糊 | 清绿 | 清脆 | 好瓜 |
| 11 | 清晰 | 清绿 | 沉闷 | ? |
| 12 | 模糊 | 乌黑 | 浊响 | ? |
示例:
p(a|X) = p(X|a)* p(a)/p(X) #贝叶斯公式
p(X|a) = p(x1,x2,x3...xn|a) = p(x1|a)*p(x2|a)*p(x3|a)...p(xn|a)
p(X) = p(x1,x2,x3...xn) = p(x1)*p(x2)*p(x3)...p(xn)
p(a|X) = p(x1|a)*p(x2|a)*p(x3|a)...p(xn|a) * p(a) / p(x1)*p(x2)*p(x3)...p(xn) #朴素贝叶斯公式
P(好瓜)=(好瓜数量)/所有瓜
P(坏瓜)=(坏瓜数量)/所有瓜
p(纹理清晰)=(纹理清晰数量)/所有瓜
p(纹理清晰|好瓜)= 好瓜中纹理清晰数量/好瓜数量
p(纹理清晰|坏瓜)= 坏瓜中纹理清晰数量/坏瓜数量
p(好瓜|纹理清晰,色泽清绿,鼓声沉闷)
=【p(好瓜)】*【p(纹理清晰,色泽清绿,鼓声沉闷|好瓜)】/【p(纹理清晰,色泽清绿,鼓声沉闷)】
=【p(好瓜)】*【p(纹理清晰|好瓜)*p(色泽清绿|好瓜)*p(鼓声沉闷|好瓜)】/【p(纹理清晰)*p(色泽清绿)*p(鼓声沉闷)】
p(坏瓜|纹理清晰,色泽清绿,鼓声沉闷)
=【p(坏瓜)*p(纹理清晰|坏瓜)*p(色泽清绿|坏瓜)*p(鼓声沉闷|坏瓜)】/【p(纹理清晰)*p(色泽清绿)*p(鼓声沉闷)】
从公式中判断"p(好瓜|纹理清晰,色泽清绿,鼓声沉闷)"和"p(坏瓜|纹理清晰,色泽清绿,鼓声沉闷)"时,因为它们的分母
值是相同的,[值都是p(纹理清晰)*p(色泽清绿)*p(鼓声沉闷)],所以只要计算它们的分子就可以判断是"好瓜"还是"坏瓜"之间谁大谁小了,所以没有必要计算分母
p(好瓜) = 6/10
p(坏瓜)=4/10
p(纹理清晰|好瓜) = 4/6
p(色泽清绿|好瓜) = 4/6
p(鼓声沉闷|好瓜) = 2/6
p(纹理清晰|坏瓜) = 1/4
p(色泽清绿|坏瓜) = 1/4
p(鼓声沉闷|坏瓜) = 1/4
把以上计算代入公式的分子
p(好瓜)*p(纹理清晰|好瓜)*p(色泽清绿|好瓜)*p(鼓声沉闷|好瓜) = 4/45
p(坏瓜)*p(纹理清晰|坏瓜)*p(色泽清绿|坏瓜)*p(鼓声沉闷|坏瓜) = 1/160
所以
p(好瓜|纹理清晰,色泽清绿,鼓声沉闷) > p(坏瓜|纹理清晰,色泽清绿,鼓声沉闷),
所以把(纹理清晰,色泽清绿,鼓声沉闷)的样本归类为好瓜
六、sklearn API
sklearn.naive_bayes.MultinomialNB()
estimator.fit(x_train, y_train)
y_predict = estimator.predict(x_test)
七、sklearn 示例
示例:用朴素贝叶斯算法对鸢尾花的分类
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
# 1)获取数据
news =load_iris()
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target)
# 3)特征工程:不用做标准化
# 4)朴素贝叶斯算法预估器流程
estimator = MultinomialNB()
estimator.fit(x_train, y_train)
# 5)模型评估
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
# 6)预测
index=estimator.predict([[2,2,3,1]])
print("预测:\n",index,news.target_names,news.target_names[index])
八、贝叶斯分类优缺点
贝叶斯分类的优点
1、**简单高效:** 计算速度快,适合大规模数据。
2、**对小规模数据表现良好:** 即使在数据量较少的情况下也能表现良好。
3、**可解释性强:** 基于概率模型,结果易于解释。
4、**对缺失数据不敏感:** 可以处理缺失值。
贝叶斯分类的缺点
1、**独立性假设:** 朴素贝叶斯假设特征之间相互独立,这在现实中往往不成立。
2、**先验概率的影响:** 如果先验概率不准确,分类结果可能会受到影响。
3、**对输入数据敏感:** 如果特征分布不符合假设(如高斯分布),分类效果可能较差。

















 2768
2768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









