







在前段时间我学习了一些简单的机器学习算法,今天终于到来了聚类算法的学习。聚类算法与前面的算法最主要的不同是其属于无监督算法。
内容为自己总结,若有疑惑欢迎留下评论一起讨论~~~
email:yuhan.huang@whu.edu.cn
源代码![]() https://github.com/pilipala5/sklearn/blob/master/code/8_Kmeans.ipynb
https://github.com/pilipala5/sklearn/blob/master/code/8_Kmeans.ipynb
创作不易,谢谢大家的点赞与评论~ :)
监督 or 无监督?
这里我就以自己浅薄的认知来给大家介绍一下监督算法与无监督算法。二者之间最本质的特征其实就是在于数据本身是否带有标签。
监督算法的数据基本上全为数据 + 标签的格式,这意味着在进行机器学习的过程中,我们基本上都是让模型去学习特征与标签之间的关系。有的时候我会觉得这反而就是简单的让模型去进行记忆操作。因此这也是为什么需要对数据集进行划分并进行验证的目的。
而无监督算法的数据并不存在标签数据,而是通过内部的计算自己进行特征的计算并得到标签。我会觉得无监督算法大多时候具有严格的数学推论过程。
而聚类算法本身也是很多样的。聚类,顾名思义,就是把类别相同的特征聚集在一起。其在现代工业与学术的意义十分重大,应用场景包括分类、降维...这里我们也不介绍太多,大家能理解其应用场景,知道什么时候用这个就行。
Kmeans
kmeans是聚类算法中比较简单也是比较有效的一种算法。其对于一堆一堆的数据比较好用,但是对于数据之间有交互的情况不大好用(比如圆环图)。感兴趣的可以自己去搜一搜。这里我们给大家简单讲一下原理。
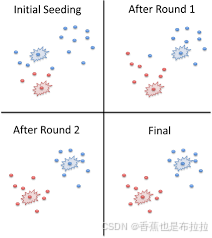
大家可以看这个流程图,基本覆盖了Kmeans的流程。首先我们需要确定n个聚类中心,这个n是我们自己输入的函数参数哈,并不是模型计算出来的。(或许有的同学会疑惑,那我怎么知道多少个聚类中心是最好的??? 别着急,后面会有讲解)
确定聚类中心的数目后,我们会随机初始化几个点位当作我们的聚类中心(目前主流的Kmean函数都是用的kmean++的初始化方法,效果好,不用修改初始化方案)。然后我们对于每一个点,计算其到所有聚类中心的距离,选择距离最小的聚类中心,这个点就属于这个类。
所有点都进行第二步的计算后,我们需要更新聚类中心。具体步骤为:把一类中所有点的平均值作为新的聚类中心,然后再重复第二部的计算。
一直迭代第二部和第三步,若聚类中心的变化小于某个阈值,认为变化不大,停止迭代。
没错! Kmeans聚类的原理就是这么简单! 自己用C++写个函数实现Kmeans也只需要100多行代码。有兴趣的可以自己实现,我这里主要是讲怎么用sklearn使用。
案例
这里我们生成多个二维点进行聚类分析。首先我们需要导入所需要的包。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score然后,我们自己简单生成几个点作为聚类分析。这里我们用了四个中心点,生成四堆点集。
# create our datasets
center_points = [[3, 1], [1, 9], [5, 5], [10, 10]]
number_points = 1000
data = []
for _ in range(number_points):
i = np.random.randint(0, len(center_points))
data.append([np.random.normal(1, 0.8) + center_points[i][0], np.random.normal(1, 0.8) + center_points[i][1]])所生成的数据集如下:
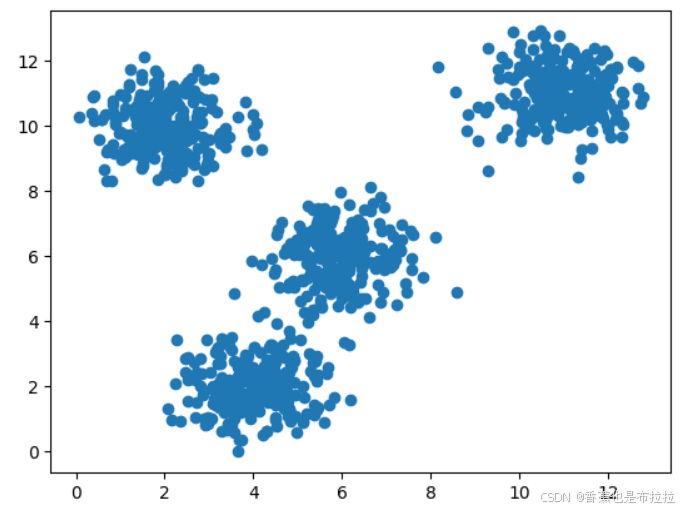
肉眼可见,大概是4堆吧。接下来我们进行聚类,并通过轮廓系数确定最佳的聚类中心数目。
你们只需要知道,轮廓系数越高越好就行。
# use kmeans to cluster, and use silhouette scores to find best cluster number
scores = []
for i in range(3, 8):
kmeans = KMeans(n_clusters=i, random_state=42).fit(data)
scores.append(silhouette_score(data, kmeans.labels_))可视化出来大概是这个样子:
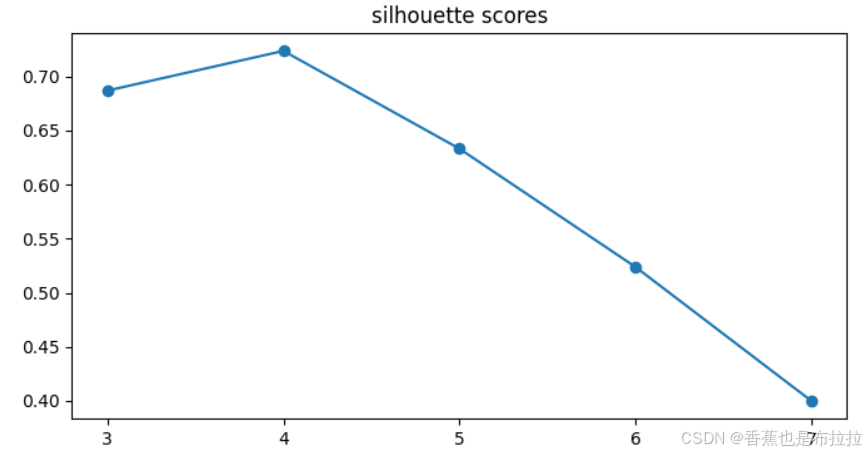
可以看到,聚类中心为4最合适。与我们生成的数据集符合。
接下来对中心点和类别进行可视化。
kmeans = KMeans(n_clusters=4).fit(data)
# visualization cluster results
plt.figure()
plt.title('cluster results')
plt.scatter([p[0] for p in data], [p[1] for p in data], c=kmeans.labels_, s=1, label="data points")
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], c='k', s=50, label='centers')
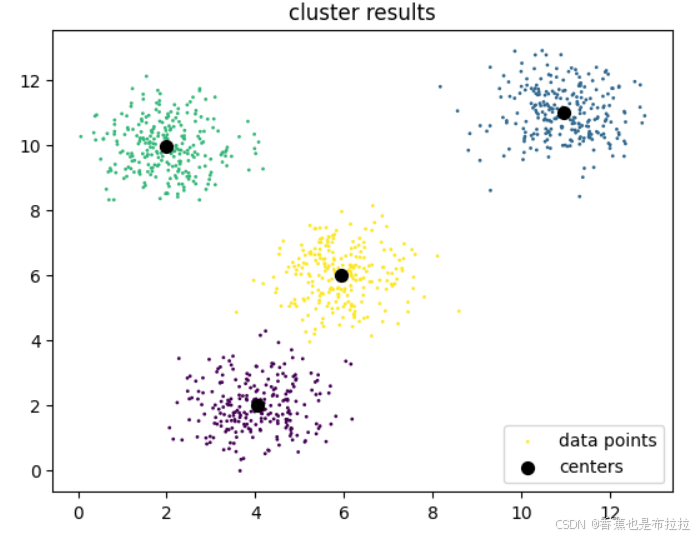
plt.legend()结果如下,可以看出来Kmeans对于这种一堆一堆的数据效果还是比较好的。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











