






Datawhale AI 夏令营---第四期(魔搭-从零入门AI生图)(小白文)
Task1
可图Kolors-LoRA风格故事挑战赛
任务一:参赛者需在可图Kolors 模型的基础上训练LoRA 模型,
任务二:基于LoRA模型生成 8 张图片组成连贯故事
例如:
向训练好的模型输入prompt,然后生成对应的图片。 如下:
1.prompt=“二次元,一个紫色短发小女孩,在家中沙发上坐着,双手托着腮,很无聊,全身,粉色连衣裙”,
2. prompt=“二次元,日系动漫,演唱会的观众席,人山人海,一个紫色短发小女孩穿着粉色吊带漏肩连衣裙坐在演唱会的观众席,舞台上衣着华丽的歌星们在唱歌”,
3. prompt=“二次元,一个紫色短发小女孩穿着粉色吊带漏肩连衣裙坐在演唱会的观众席,露出憧憬的神情”,
4. prompt=“二次元,一个紫色短发小女孩穿着粉色吊带漏肩连衣裙,对着流星许愿,闭着眼睛,十指交叉,侧面”,
5. prompt=“二次元,一个紫色中等长度头发小女孩穿着粉色吊带漏肩连衣裙,在练习室练习唱歌”,
6.prompt=“二次元,一个紫色长发小女孩穿着粉色吊带漏肩连衣裙,在练习室练习唱歌,手持话筒”
7.prompt=“二次元,紫色长发少女,穿着黑色连衣裙,试衣间,心情忐忑”,
8. prompt=“二次元,紫色长发少女,穿着黑色礼服,连衣裙,在台上唱歌”,

简单了解Kolors 模型


代码开源链接:https://github.com/Kwai-Kolors/Kolors
模型开源链接:https://modelscope.cn/models/Kwai-Kolors/Kolors
技术报告链接:https://github.com/Kwai-Kolors/Kolors/blob/master/imgs/Kolors_paper.pdf
魔搭研习社最佳实践说明:https://www.modelscope.cn/learn/575?pid=543
简单来讲 也是文本生图的模型,优点:对语言理解较深刻,可渲染中文



膜拜佬佬的文章【论文+中文文生图】
小白鼠的碎碎念:7月开源,好新;llm相关,萌新感到好难。
简单了解LoRA 模型
LoRA(Low-Rank Adaptation)是一种用于微调Stable Diffusion模型的训练技术。
LORA详解(史上最全)
LoRA的核心思想是通过将模型中的权重矩阵分解为低秩矩阵的乘积,从而减少参数的数量。在大型语言模型(如BERT、GPT)中,通常存在许多高维度的全连接层,LoRA通过对这些层的权重矩阵进行低秩分解,大幅降低了微调时的参数量。
LoRA的提出为大型预训练模型的广泛应用提供了一种更为经济有效的微调方式,使得在资源受限的条件下进行模型的特定任务优化成为可能
baseline
数据集构建:下载数据集kolors,处理数据集
#下载数据集
from modelscope.msdatasets import MsDataset
ds = MsDataset.load(
'AI-ModelScope/lowres_anime',
subset_name='default',
split='train',
cache_dir="/mnt/workspace/kolors/data"
)
import json, os
from data_juicer.utils.mm_utils import SpecialTokens
from tqdm import tqdm
os.makedirs("./data/lora_dataset/train", exist_ok=True)
os.makedirs("./data/data-juicer/input", exist_ok=True)
with open("./data/data-juicer/input/metadata.jsonl", "w") as f:
for data_id, data in enumerate(tqdm(ds)):
image = data["image"].convert("RGB")
image.save(f"/mnt/workspace/kolors/data/lora_dataset/train/{data_id}.jpg")
metadata = {"text": "二次元", "image": [f"/mnt/workspace/kolors/data/lora_dataset/train/{data_id}.jpg"]}
f.write(json.dumps(metadata))
f.write("\n")
# 处理数据集 并保存
data_juicer_config = """
# global parameters
project_name: 'data-process'
dataset_path: './data/data-juicer/input/metadata.jsonl' # path to your dataset directory or file
np: 4 # number of subprocess to process your dataset
text_keys: 'text'
image_key: 'image'
image_special_token: '<__dj__image>'
export_path: './data/data-juicer/output/result.jsonl'
# process schedule
# a list of several process operators with their arguments
process:
- image_shape_filter:
min_width: 1024
min_height: 1024
any_or_all: any
- image_aspect_ratio_filter:
min_ratio: 0.5
max_ratio: 2.0
any_or_all: any
"""
with open("data/data-juicer/data_juicer_config.yaml", "w") as file:
file.write(data_juicer_config.strip())
!dj-process --config data/data-juicer/data_juicer_config.yaml
import pandas as pd
import os, json
from PIL import Image
from tqdm import tqdm
texts, file_names = [], []
os.makedirs("./data/lora_dataset_processed/train", exist_ok=True)
with open("./data/data-juicer/output/result.jsonl", "r") as file:
for data_id, data in enumerate(tqdm(file.readlines())):
data = json.loads(data)
text = data["text"]
texts.append(text)
image = Image.open(data["image"][0])
image_path = f"./data/lora_dataset_processed/train/{data_id}.jpg"
image.save(image_path)
file_names.append(f"{data_id}.jpg")
data_frame = pd.DataFrame()
data_frame["file_name"] = file_names
data_frame["text"] = texts
data_frame.to_csv("./data/lora_dataset_processed/train/metadata.csv", index=False, encoding="utf-8-sig")
data_frame
模型微调:模型微调训练
# 下载模型
from diffsynth import download_models
download_models(["Kolors", "SDXL-vae-fp16-fix"])
#模型训练
import os
cmd = """
python DiffSynth-Studio/examples/train/kolors/train_kolors_lora.py \
--pretrained_unet_path models/kolors/Kolors/unet/diffusion_pytorch_model.safetensors \
--pretrained_text_encoder_path models/kolors/Kolors/text_encoder \
--pretrained_fp16_vae_path models/sdxl-vae-fp16-fix/diffusion_pytorch_model.safetensors \
--lora_rank 16 \
--lora_alpha 4.0 \
--dataset_path data/lora_dataset_processed \
--output_path ./models \
--max_epochs 1 \
--center_crop \
--use_gradient_checkpointing \
--precision "16-mixed"
""".strip()
os.system(cmd)
图片生成:调用训练好的模型生成图片
from diffsynth import ModelManager, SDXLImagePipeline
from peft import LoraConfig, inject_adapter_in_model
import torch
def load_lora(model, lora_rank, lora_alpha, lora_path):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=lora_alpha,
init_lora_weights="gaussian",
target_modules=["to_q", "to_k", "to_v", "to_out"],
)
model = inject_adapter_in_model(lora_config, model)
state_dict = torch.load(lora_path, map_location="cpu")
model.load_state_dict(state_dict, strict=False)
return model
# Load models
model_manager = ModelManager(torch_dtype=torch.float16, device="cuda",
file_path_list=[
"models/kolors/Kolors/text_encoder",
"models/kolors/Kolors/unet/diffusion_pytorch_model.safetensors",
"models/kolors/Kolors/vae/diffusion_pytorch_model.safetensors"
])
pipe = SDXLImagePipeline.from_model_manager(model_manager)
# Load LoRA
pipe.unet = load_lora(
pipe.unet,
lora_rank=16, # This parameter should be consistent with that in your training script.
lora_alpha=2.0, # lora_alpha can control the weight of LoRA.
lora_path="models/lightning_logs/version_0/checkpoints/epoch=0-step=500.ckpt"
)
# 生成图像
torch.manual_seed(0)
image = pipe(
prompt="二次元,一个紫色短发小女孩,在家中沙发上坐着,双手托着腮,很无聊,全身,粉色连衣裙",
negative_prompt="丑陋、变形、嘈杂、模糊、低对比度",
cfg_scale=4,
num_inference_steps=50, height=1024, width=1024,
)
image.save("1.jpg")
torch.manual_seed(1)
image = pipe(
prompt="二次元,日系动漫,演唱会的观众席,人山人海,一个紫色短发小女孩穿着粉色吊带漏肩连衣裙坐在演唱会的观众席,舞台上衣着华丽的歌星们在唱歌",
negative_prompt="丑陋、变形、嘈杂、模糊、低对比度",
cfg_scale=4,
num_inference_steps=50, height=1024, width=1024,
)
image.save("2.jpg")
# ......
import numpy as np
from PIL import Image
images = [np.array(Image.open(f"{i}.jpg")) for i in range(1, 9)]
image = np.concatenate([
np.concatenate(images[0:2], axis=1),
np.concatenate(images[2:4], axis=1),
np.concatenate(images[4:6], axis=1),
np.concatenate(images[6:8], axis=1),
], axis=0)
image = Image.fromarray(image).resize((1024, 2048))
image
最后,生成图片质量很高。

Task2 精读代码
AI生图基础知识
AI生图模型:通过海量的图库和文本描述的深度神经网络学习,最终的目标是可以根据输入的指示(不管是文本还是图片还是任何)生成符合语义的图片。
AI生图模型获得图片生成能力主要是通过 学习 图片描述 以及 图片特征,尝试将这两者进行一一对应,存储在自己的记忆里
AI生图历史
20世纪70年代 :艺术家哈罗德·科恩(Harold Cohen)发明AARON,可通过机械臂输出作画。

2012年 吴恩达使用卷积神经网络(CNN),可生成“猫脸”。

2015年,谷歌推出了“深梦”(Deep Dream)图像生成工具,可以基于给定的图片生成梦幻版图片(类似一个高级滤镜)
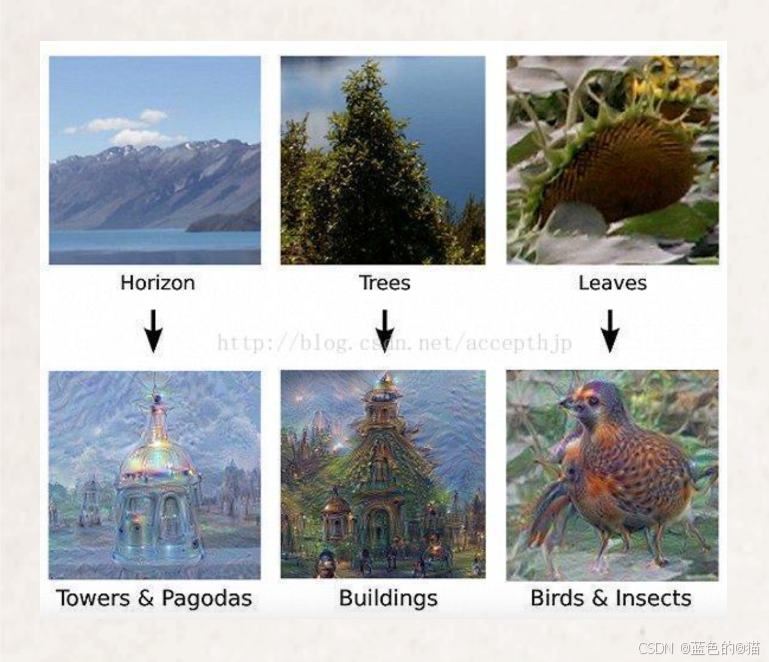
2021 年 1 月 OpenAI 推出DALL-E模型(GPT-3 语言处理模型的一个衍生版本),能文本生图

2022年8月,AI生图真正走进了大众的视野,让各个领域无法忽视。
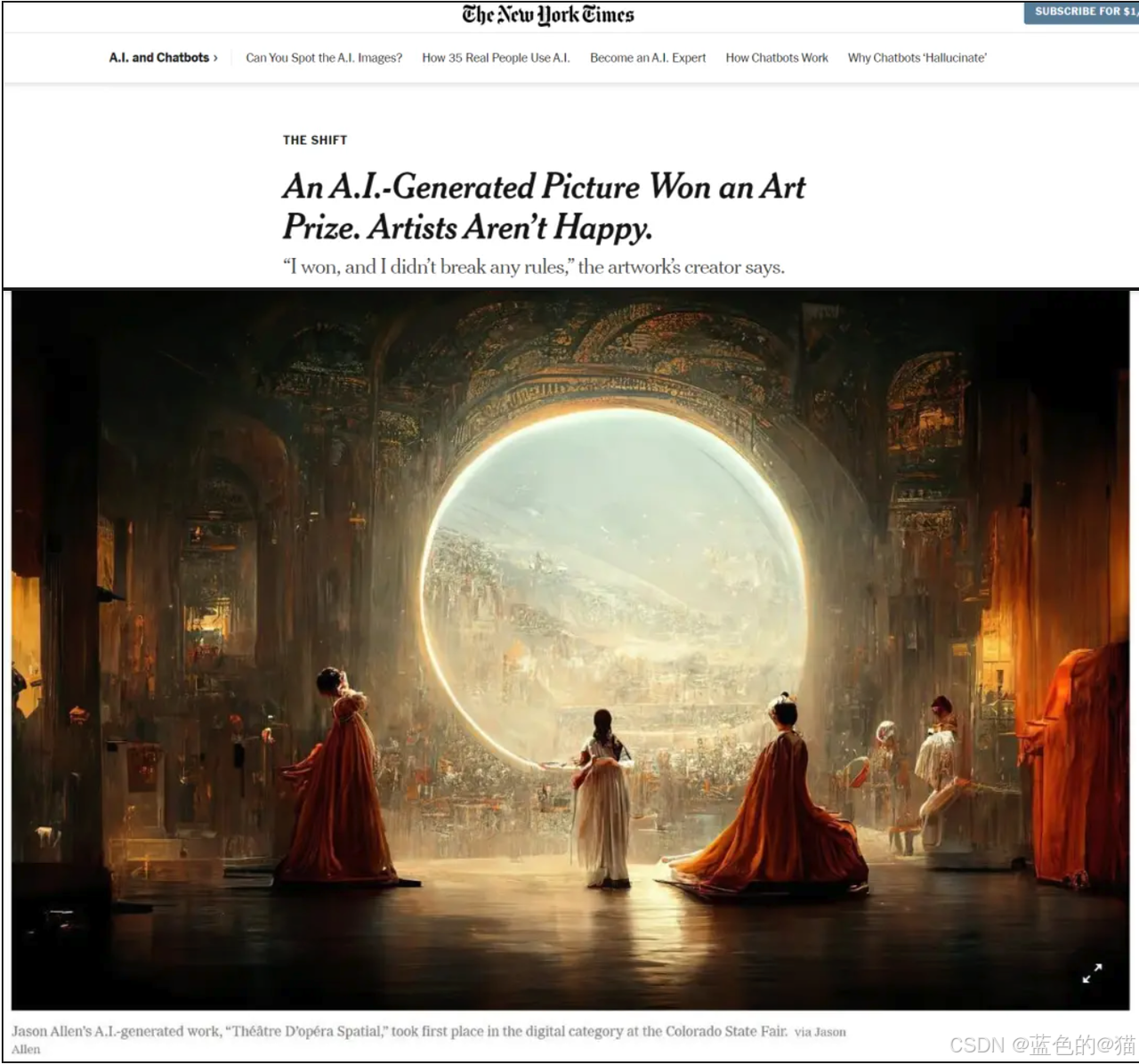
当时让AI生图破圈的是AI绘画作品《太空歌剧院》,该作品在美国科罗拉多州举办的新兴数字艺术家竞赛中获得了比赛“数字艺术/数字修饰照片”类别一等奖。
小前沿
过去文生图主要以 SD 系列基础模型为主,仅支持英文的prompt。
kolors(可图)是支持中文的文生图模型,文生图的prompt格式较为固定。
可图优质咒语书!!!
魔搭社区还开源了专门的各种风格的可图优质咒语书,可以针对600+种不同风格,完善prompt,生成各种风格图片。

代码解读
代码的主体架构
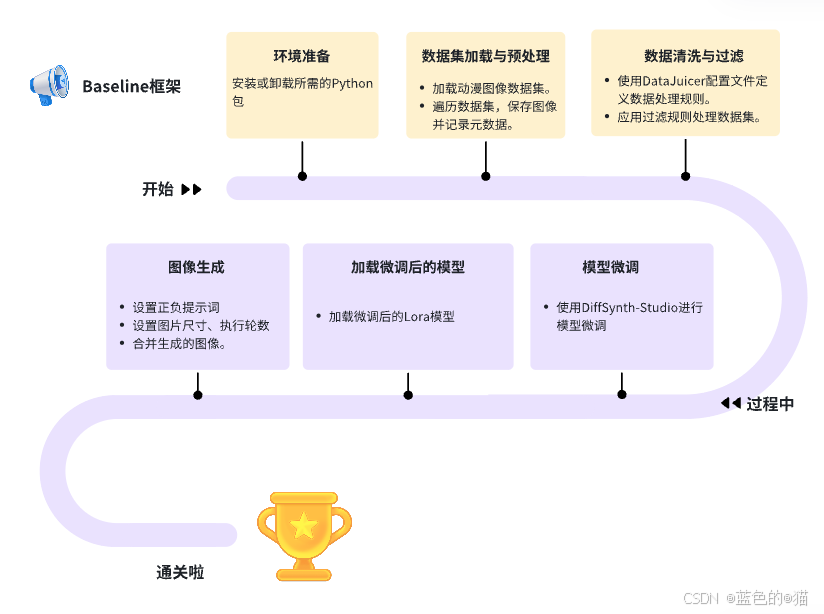
代码解读
# 安装 Data-Juicer 和 DiffSynth-Studio
!pip install simple-aesthetics-predictor # 安装simple-aesthetics-predictor
!pip install -v -e data-juicer # 安装data-juicer
!pip uninstall pytorch-lightning -y # 卸载pytorch-lightning
!pip install peft lightning pandas torchvision # 安装 peft lightning pandas torchvision
!pip install -e DiffSynth-Studio # 安装DiffSynth-Studio
# 从魔搭数据集中下载数据集AI-ModelScope/lowres_anime
from modelscope.msdatasets import MsDataset #引入数据集模块msdatasets
ds = MsDataset.load(
'AI-ModelScope/lowres_anime',
subset_name='default',
split='train',
cache_dir="/mnt/workspace/kolors/data" # 指定缓存目录
) # 从魔搭数据集中下载数据集AI-ModelScope/lowres_anime,赋值给参数ds
# 生成数据集
import json, os # 导入json和os模块
from data_juicer.utils.mm_utils import SpecialTokens # 导入SpecialTokens
from tqdm import tqdm # 导入tqdm进度条管理
os.makedirs("./data/lora_dataset/train", exist_ok=True) # 创建文件夹./data/lora_dataset/train
os.makedirs("./data/data-juicer/input", exist_ok=True) # 创建文件夹./data/data-juicer/input
with open("./data/data-juicer/input/metadata.jsonl", "w") as f:
for data_id, data in enumerate(tqdm(ds)): # 遍历数据集ds
image = data["image"].convert("RGB") # 将数据集的图片转换为RGB
image.save(f"/mnt/workspace/kolors/data/lora_dataset/train/{data_id}.jpg") # 保存数据集的图片
metadata = {"text": "二次元", "image": [f"/mnt/workspace/kolors/data/lora_dataset/train/{data_id}.jpg"]} # 生成当前图片的索引数据
f.write(json.dumps(metadata)) # 将索引数据写入文件./data/data-juicer/input/metadata.jsonl
f.write("\n")
# 配置data-juicer,并进行数据筛选过滤
# 配置过滤的规则
data_juicer_config = """
# global parameters
project_name: 'data-process' # 名称
dataset_path: './data/data-juicer/input/metadata.jsonl' # 你前面生成的数据的索引文件
np: 4 # 线程数
text_keys: 'text' # 文件./data/data-juicer/input/metadata.jsonl的描述的字段名
image_key: 'image' # 文件./data/data-juicer/input/metadata.jsonl的图片字段名
image_special_token: '<__dj__image>'
export_path: './data/data-juicer/output/result.jsonl' # 筛选通过的图片结果保存的的索引文件
# process schedule
# a list of several process operators with their arguments
# 过滤的规则
process:
- image_shape_filter: # 图片尺寸过滤
min_width: 1024 # 最小宽度1024
min_height: 1024 # 最小高度1024
any_or_all: any # 符合前面条件的图片才会被保留
- image_aspect_ratio_filter: # 图片长宽比过滤
min_ratio: 0.5 # 最小长宽比0.5
max_ratio: 2.0 # 最大长宽比2.0
any_or_all: any # 符合前面条件的图片才会被保留
"""
# 保存data-juicer配置到data/data-juicer/data_juicer_config.yaml
with open("data/data-juicer/data_juicer_config.yaml", "w") as file:
file.write(data_juicer_config.strip())
# data-juicer开始执行数据筛选
!dj-process --config data/data-juicer/data_juicer_config.yaml
# 通过前面通过data-juicer筛选的图片索引信息./data/data-juicer/output/result.jsonl,生成数据集
import pandas as pd # 导入pandas
import os, json # 导入os和json
from PIL import Image # 导入Image
from tqdm import tqdm # 导入tqdm进度条管理
texts, file_names = [], [] # 定义两个空列表,分别存储图片描述和图片名称
os.makedirs("./data/lora_dataset_processed/train", exist_ok=True) # 创建文件夹./data/lora_dataset_processed/train
with open("./data/data-juicer/output/result.jsonl", "r") as file: # 打开前面data-juicer筛选的图片索引文件./data/data-juicer/output/result.jsonl
for data_id, data in enumerate(tqdm(file.readlines())): # 遍历文件./data/data-juicer/output/result.jsonl
data = json.loads(data) # 将json字符串转换为对象
text = data["text"] # 获取对象中的text属性,也就是图片的描述信息
texts.append(text) # 将图片的描述信息添加到texts列表中
image = Image.open(data["image"][0]) # 获取对象中的image属性,也就是图片的路径,然后用这个路径打开图片
image_path = f"./data/lora_dataset_processed/train/{data_id}.jpg" # 生成保存图片的路径
image.save(image_path) # 将图片保存到./data/lora_dataset_processed/train文件夹中
file_names.append(f"{data_id}.jpg") # 将图片名称添加到file_names列表中
data_frame = pd.DataFrame() # 创建空的DataFrame
data_frame["file_name"] = file_names # 将图片名称添加到data_frame中
data_frame["text"] = texts # 将图片描述添加到data_frame中
data_frame.to_csv("./data/lora_dataset_processed/train/metadata.csv", index=False, encoding="utf-8-sig") # 将data_frame保存到./data/lora_dataset_processed/train/metadata.csv
data_frame # 查看data_frame
# 下载可图模型
from diffsynth import download_models # 导入download_models
download_models(["Kolors", "SDXL-vae-fp16-fix"]) # 下载可图模型
# DiffSynth-Studio提供了可图的Lora训练脚本,查看脚本信息
!python DiffSynth-Studio/examples/train/kolors/train_kolors_lora.py -h
# 执行可图Lora训练
import os
cmd = """
python DiffSynth-Studio/examples/train/kolors/train_kolors_lora.py \ # 选择使用可图的Lora训练脚本DiffSynth-Studio/examples/train/kolors/train_kolors_lora.py
--pretrained_unet_path models/kolors/Kolors/unet/diffusion_pytorch_model.safetensors \ # 选择unet模型
--pretrained_text_encoder_path models/kolors/Kolors/text_encoder \ # 选择text_encoder
--pretrained_fp16_vae_path models/sdxl-vae-fp16-fix/diffusion_pytorch_model.safetensors \ # 选择vae模型
--lora_rank 16 \ # lora_rank 16 表示在权衡模型表达能力和训练效率时,选择了使用 16 作为秩,适合在不显著降低模型性能的前提下,通过 LoRA 减少计算和内存的需求
--lora_alpha 4.0 \ # 设置 LoRA 的 alpha 值,影响调整的强度
--dataset_path data/lora_dataset_processed \ # 指定数据集路径,用于训练模型
--output_path ./models \ # 指定输出路径,用于保存模型
--max_epochs 1 \ # 设置最大训练轮数为 1
--center_crop \ # 启用中心裁剪,这通常用于图像预处理
--use_gradient_checkpointing \ # 启用梯度检查点技术,以节省内存
--precision "16-mixed" # 指定训练时的精度为混合 16 位精度(half precision),这可以加速训练并减少显存使用
""".strip()
os.system(cmd) # 执行可图Lora训练
# 加载lora微调后的模型
from diffsynth import ModelManager, SDXLImagePipeline # 导入ModelManager和SDXLImagePipeline
from peft import LoraConfig, inject_adapter_in_model # 导入LoraConfig和inject_adapter_in_model
import torch # 导入torch
# 加载LoRA配置并注入模型
def load_lora(model, lora_rank, lora_alpha, lora_path):
lora_config = LoraConfig(
r=lora_rank, # 设置LoRA的秩(rank)
lora_alpha=lora_alpha, # 设置LoRA的alpha值,控制LoRA的影响权重
init_lora_weights="gaussian", # 初始化LoRA权重为高斯分布
target_modules=["to_q", "to_k", "to_v", "to_out"], # 指定要应用LoRA的模块
)
model = inject_adapter_in_model(lora_config, model) # 将LoRA配置注入到模型中
state_dict = torch.load(lora_path, map_location="cpu") # 加载LoRA微调后的权重
model.load_state_dict(state_dict, strict=False) # 将权重加载到模型中,允许部分权重不匹配
return model # 返回注入LoRA后的模型
# 加载预训练模型
model_manager = ModelManager(
torch_dtype=torch.float16, # 设置模型的数据类型为float16,减少显存占用
device="cuda", # 指定使用GPU进行计算
file_path_list=[
"models/kolors/Kolors/text_encoder", # 文本编码器的路径
"models/kolors/Kolors/unet/diffusion_pytorch_model.safetensors", # UNet模型的路径
"models/kolors/Kolors/vae/diffusion_pytorch_model.safetensors" # VAE模型的路径
]
)
# 初始化图像生成管道
pipe = SDXLImagePipeline.from_model_manager(model_manager) # 从模型管理器中加载模型并初始化管道
# 加载并应用LoRA权重到UNet模型
pipe.unet = load_lora(
pipe.unet,
lora_rank=16, # 设置LoRA的秩(rank),与训练脚本中的参数保持一致
lora_alpha=2.0, # 设置LoRA的alpha值,控制LoRA对模型的影响权重
lora_path="models/lightning_logs/version_0/checkpoints/epoch=0-step=500.ckpt" # 指定LoRA权重的文件路径
)
# 生成图像
torch.manual_seed(0) # 设置随机种子,确保生成的图像具有可重复性。如果想要每次生成不同的图像,可以将种子值改为随机值。
image = pipe(
prompt="二次元,一个紫色短发小女孩,在家中沙发上坐着,双手托着腮,很无聊,全身,粉色连衣裙", # 设置正向提示词,用于指导模型生成图像的内容
negative_prompt="丑陋、变形、嘈杂、模糊、低对比度", # 设置负向提示词,模型会避免生成包含这些特征的图像
cfg_scale=4, # 设置分类自由度 (Classifier-Free Guidance) 的比例,数值越高,模型越严格地遵循提示词
num_inference_steps=50, # 设置推理步数,步数越多,生成的图像细节越丰富,但生成时间也更长
height=1024, width=1024, # 设置生成图像的高度和宽度,这里生成 1024x1024 像素的图像
)
image.save("1.jpg") # 将生成的图像保存为 "1.jpg" 文件
# 图像拼接,展示总体拼接大图
import numpy as np # 导入numpy库,用于处理数组和数值计算
from PIL import Image # 导入PIL库中的Image模块,用于图像处理
images = [np.array(Image.open(f"{i}.jpg")) for i in range(1, 9)] # 读取1.jpg到8.jpg的图像,转换为numpy数组,并存储在列表images中
image = np.concatenate([ # 将四组图像在垂直方向上拼接
np.concatenate(images[0:2], axis=1), # 将第1组(images[0:2])的两张图像在水平方向上拼接
np.concatenate(images[2:4], axis=1), # 将第2组(images[2:4])的两张图像在水平方向上拼接
np.concatenate(images[4:6], axis=1), # 将第3组(images[4:6])的两张图像在水平方向上拼接
np.concatenate(images[6:8], axis=1), # 将第4组(images[6:8])的两张图像在水平方向上拼接
], axis=0) # 将四组拼接后的图像在垂直方向上拼接
image = Image.fromarray(image).resize((1024, 2048)) # 将拼接后的numpy数组转换为图像对象,并调整大小为1024x2048像素
image # 输出最终生成的图像对象,用于显示图像
基于话剧的连环画制作
prompt制作
用如下prompt询问gpt,通义千问等模型,制作prompt
你是一个文生图专家,我们现在要做一个实战项目,就是要编排一个文生图话剧
话剧由8张场景图片生成,你需要输出每张图片的生图提示词
具体的场景图片
1、女主正在上课
2、开始睡着了
3、进入梦乡,梦到自己站在路旁
4、王子骑马而来
5、两人相谈甚欢
6、一起坐在马背上
7、下课了,梦醒了
8、又回到了学习生活中
生图提示词要求
1、风格为古风
2、根据场景确定是使用全身还是上半身
3、人物描述
4、场景描述
5、做啥事情
例子:
古风,水墨画,一个黑色长发少女,坐在教室里,盯着黑板,深思,上半身,红色长裙
女主正在上课
提示词: 古风,水墨画,一个黑色长发少女,穿着红色长裙,坐在古朴的教室里,盯着竹简上的文字,表情专注,环境安静且充满书香气息,上半身,手中握着毛笔。
开始睡着了
提示词: 古风,水墨画,一个黑色长发少女,穿着红色长裙,坐在教室里,眼皮逐渐沉重,头微微倾斜,进入浅睡,身旁的窗外微风吹拂,烛火轻轻摇曳,上半身。
进入梦乡,梦到自己站在路旁
提示词: 古风,水墨画,一个黑色长发少女,穿着红色长裙,站在古老的青石路旁,四周环绕着朦胧的雾气,远处隐约可见山峦与竹林,神情迷茫,全身。
王子骑马而来
提示词: 古风,水墨画,一个俊美的王子,身着白色锦袍,骑着白色骏马,马蹄轻踏在青石路上,身后飘动着长长的披风,背景是茂密的竹林,王子目光温柔地看向前方,全身。
两人相谈甚欢
提示词: 古风,水墨画,一个黑色长发少女与身着白色锦袍的王子并肩而立,四目相对,神情欢快,两人站在竹林边的青石路上,周围鸟语花香,微风拂面,全身。
一起坐在马背上
提示词: 古风,水墨画,一个黑色长发少女与白衣王子同乘一匹白马,王子双手握缰绳,少女坐在前方,微微侧头,露出甜美的笑容,背景是辽阔的青山与竹林,全身。
下课了,梦醒了
提示词: 古风,水墨画,一个黑色长发少女,坐在教室里,猛然惊醒,神情恍惚,手中的毛笔轻微颤动,周围依旧是静谧的学习环境,烛火依旧摇曳,上半身。
又回到了学习生活中
提示词: 古风,水墨画,一个黑色长发少女,穿着红色长裙,坐在古朴的教室里,继续认真学习,手握毛笔,脸上带着平静的神情,窗外阳光透过纸窗洒进,桌上铺着竹简,上半身。
使用上述提示词稍作修改后生成如下图片:

Task3
任务一: 了解微调的基本原理及各种参数
任务二: 学习并使用ComfyUI来实现一个更加高度定制的文生图
Lora微调
LoRA (Low-Rank Adaptation) 微调是一种用于在预训练模型上进行高效微调的技术。它可以通过高效且灵活的方式实现模型的个性化调整,使其能够适应特定的任务或领域,同时保持良好的泛化能力和较低的资源消耗。这对于推动大规模预训练模型的实际应用至关重要。
模型微调:当模型在某方面能力不足,此时我们向模型提高该方面的数据让其学习,改动模型参数。
全量微调
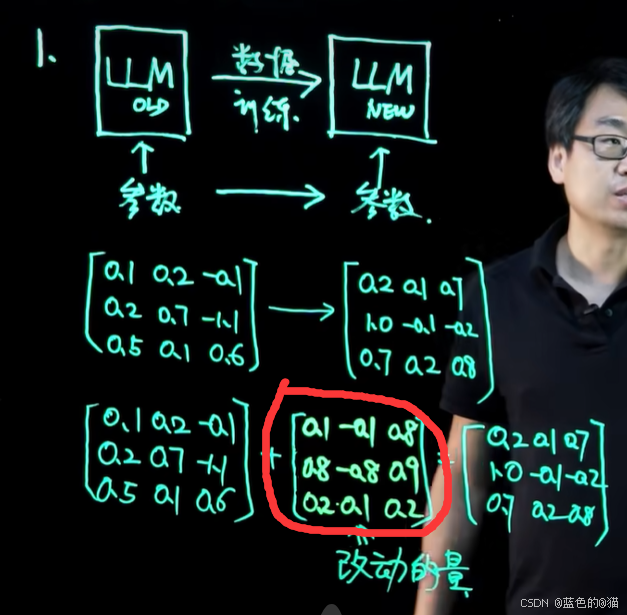
全量微调:假设模型参数为左边33矩阵, 我们让模型从新的数据中学习,获得33的改动的量。
全量参数 Fine-tune 需要调整模型全部参数,随着预训练模型规模的不断扩大(GPT-3,175B),全量 Fine-tune 的资源压力也倍增。
模型参数量太大,微调所需资源也很大
lora微调
模型微调:增强模型在某一方面的能力,原来模型强大能力不要太多减弱
新知识相较于 模型原有的知识量 是较少的
因此,耗费大量资源做全量微调,而全量微调中的参数很可能有所重复(低维知识在高维空间表现,对应矩阵的秩肯定不够,矩阵是线性相关的),是糟糕的
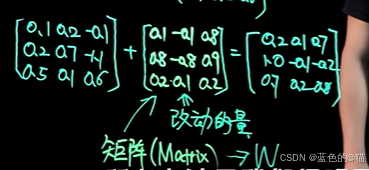
可以将改矩阵W分解为AB
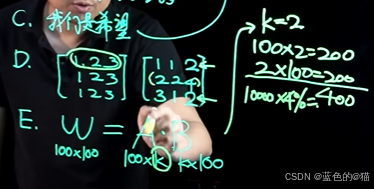
也正因此,我们可以通过学习 A*B 来达到学习 W的目标(需要学习的参数量大大降低)

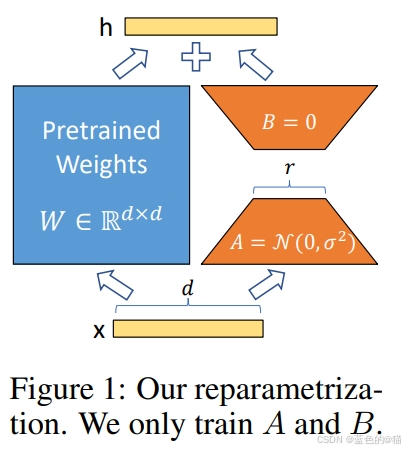
代码理解
import os
cmd = """
python DiffSynth-Studio/examples/train/kolors/train_kolors_lora.py \ # 选择使用可图的Lora训练脚本DiffSynth-Studio/examples/train/kolors/train_kolors_lora.py
--pretrained_unet_path models/kolors/Kolors/unet/diffusion_pytorch_model.safetensors \ # 选择unet模型
--pretrained_text_encoder_path models/kolors/Kolors/text_encoder \ # 选择text_encoder
--pretrained_fp16_vae_path models/sdxl-vae-fp16-fix/diffusion_pytorch_model.safetensors \ # 选择vae模型
--lora_rank 16 \ # lora_rank 16 表示在权衡模型表达能力和训练效率时,选择了使用 16 作为秩,适合在不显著降低模型性能的前提下,通过 LoRA 减少计算和内存的需求
--lora_alpha 4.0 \ # 设置 LoRA 的 alpha 值,影响调整的强度
--dataset_path data/lora_dataset_processed \ # 指定数据集路径,用于训练模型
--output_path ./models \ # 指定输出路径,用于保存模型
--max_epochs 1 \ # 设置最大训练轮数为 1
--center_crop \ # 启用中心裁剪,这通常用于图像预处理
--use_gradient_checkpointing \ # 启用梯度检查点技术,以节省内存
--precision "16-mixed" # 指定训练时的精度为混合 16 位精度(half precision),这可以加速训练并减少显存使用
""".strip()
os.system(cmd) # 执行可图Lora训练

-
UNet:负责根据输入的噪声和文本条件生成图像。在Stable Diffusion模型中,UNet接收由VAE编码器产生的噪声和文本编码器转换的文本向量作为输入,并预测去噪后的噪声,从而生成与文本描述相符的图像
-
VAE:生成模型,用于将输入数据映射到潜在空间,并从中采样以生成新图像。在Stable Diffusion中,VAE编码器首先生成带有噪声的潜在表示,这些表示随后与文本条件一起输入到UNet中
-
文本编码器:将文本输入转换为模型可以理解的向量表示。在Stable Diffusion模型中,文本编码器使用CLIP模型将文本提示转换为向量,这些向量与VAE生成的噪声一起输入到UNet中,指导图像的生成过程
ComfyUI
ComfyUI 是GUI的一种,是基于节点工作的用户界面,主要用于操作图像的生成技术,ComfyUI 的特别之处在于它采用了一种模块化的设计,把图像生成的过程分解成了许多小的步骤,每个步骤都是一个节点。这些节点可以连接起来形成一个工作流程,这样用户就可以根据需要定制自己的图像生成过程。
速通ComfyUI工作流
首先在魔搭社区开一个实例
在/mnt/workspace路径下先下载Comfyui安装文件
git lfs install
git clone https://www.modelscope.cn/datasets/maochase/kolors_test_comfyui.git
mv kolors_test_comfyui/* ./
rm -rf kolors_test_comfyui/
然后挪动task1中微调完成Lora文件
mkdir -p /mnt/workspace/models/lightning_logs/version_0/checkpoints/
mv epoch=0-step=500.ckpt /mnt/workspace/models/lightning_logs/version_0/checkpoints/
进入ComfyUI的安装文件并一键执行安装程序
当执行到最后一个节点的内容输出了一个访问的链接的时候,复制链接到浏览器中访问
教程
-
不带lora的工作流:
load对应json文件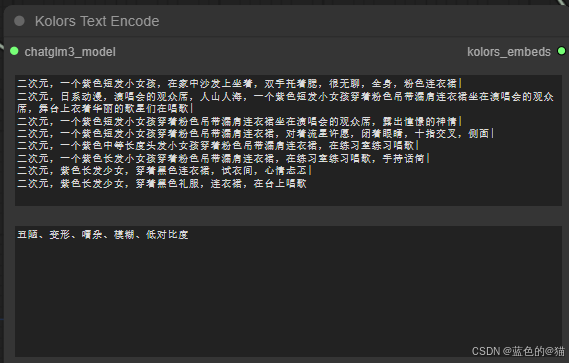 生成的图片:
生成的图片: 
-
带lora的工作流:
load对应json文件:
最后生成的图片:

训练提交
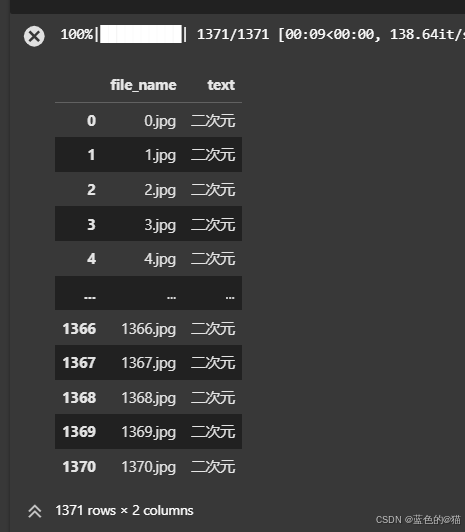
在魔搭找到一个古风数据集,但是一直加载不上。
随之发现:
前文baseline是过滤出1024 * 1024的图片
1400多张过滤出了100多张图片
这里我们更改为最小尺寸为512*512,随即过滤出1300多张
随之改动baseline,并重新微调
之后尝试利用 comfyui进行图片生成:
二次元,一个 黑色长直发,双眼大而清澈,肤色白皙,脸庞柔美 的少女,穿着红色长裙,坐在教室里,盯着竹简上的文字,表情专注,环境安静且充满书香气息,上半身,手中握着毛笔。|
二次元,一个 黑色长直发,双眼大而清澈,肤色白皙,脸庞柔美 的少女,穿着红色长裙,坐在教室里,眼皮逐渐沉重,头微微倾斜,进入浅睡,身旁的窗外微风吹拂,烛火轻轻摇曳,上半身。|
二次元,一个 黑色长直发,双眼大而清澈,肤色白皙,脸庞柔美 的少女,穿着红色长裙,站在古老的青石路旁,四周环绕着朦胧的雾气,远处隐约可见山峦与竹林,神情迷茫,全身。|
二次元,一个 黑色长直发,双眼大而清澈,肤色白皙,脸庞柔美 的少女,穿着红色长裙,与身着白色锦袍的王子并肩而立,四目相对,神情欢快,两人站在竹林边的青石路上,周围鸟语花香,微风拂面,全身。|
二次元,一个 黑色长直发,双眼大而清澈,肤色白皙,脸庞柔美 的少女,穿着红色长裙,与白衣王子同乘一匹白马,王子双手握缰绳,少女坐在前方,微微侧头,露出甜美的笑容,背景是辽阔的青山与竹林,全身。|
二次元,一个 黑色长直发,双眼大而清澈,肤色白皙,脸庞柔美 的少女,穿着红色长裙,坐在教室里,猛然惊醒,神情恍惚,手中的毛笔轻微颤动,周围依旧是静谧的学习环境,烛火依旧摇曳,上半身。|
二次元,一个 黑色长直发,双眼大而清澈,肤色白皙,脸庞柔美 的少女,穿着红色长裙,坐在古朴的教室里,继续认真学习,手握毛笔,脸上带着平静的神情,窗外阳光透过纸窗洒进,桌上铺着竹简,上半身。|
二次元,一个 黑色长直发,双眼大而清澈,肤色白皙,脸庞柔美 的少女,穿着红色长裙,站在古老的青石路旁,四周环绕着朦胧的雾气,远处隐约可见山峦与竹林,神情迷茫,全身。
丑陋、变形、嘈杂、模糊、低对比度

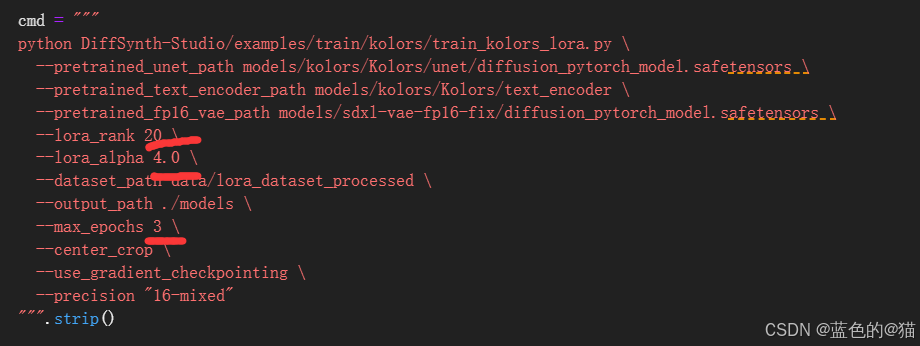
经过一番周折
又改变了参数训练训练 改为
然后生成一堆图片
# torch.manual_seed(0)
# image = pipe(
# prompt="古风,水墨画,一个黑色长发少女,鹅蛋脸,穿着红色长裙,坐在古朴的教室里,盯着竹简上的文字,表情专注,环境安静且充满书香气息,上半身,手中握着毛笔",
# negative_prompt="丑陋、变形、嘈杂、模糊、低对比度",
# cfg_scale=4,
# num_inference_steps=50, height=1024, width=1024,
# )
# image.save("1.jpg")
sttr="""
二次元,日系,王昭君,粉色长发少女,穿着粉色吊带露肩连衣裙,坐在演唱会的观众席上,舞台上华丽的歌星们在唱歌。女孩的目光充满了憧憬,她被这次演唱会深深吸引,心中种下了一个梦想。 漂亮,可爱,可爱,卡哇伊|
二次元,日系,王昭君,粉色长发少女,穿着粉色吊带露肩连衣裙,坐在演唱会的观众席上,露出憧憬的神情。她深深被舞台上的表演打动,心中开始幻想自己有一天也能站在舞台中央。 漂亮,可爱,可爱,卡哇伊|
二次元,日系,王昭君,粉色长发少女,穿着粉色吊带露肩连衣裙,坐在演唱会的观众席上,依旧带着憧憬的神情。她的心中愈发坚定,梦想着有一天能够登上舞台,实现自己的音乐梦想。 漂亮,可爱,可爱,卡哇伊|
二次元,日系,王昭君,粉色长发少女,穿着粉色吊带露肩连衣裙,对着流星许愿,闭着眼睛,十指交叉,侧面。她在心中默默祈祷,希望有一天自己的愿望能够实现,成为一名耀眼的歌手。 漂亮,可爱,可爱,卡哇伊|
二次元,日系,王昭君,粉色长发少女,穿着粉色吊带露肩连衣裙,在练习室里练习唱歌。她每天努力地训练,不断提升自己的歌唱技巧,希望有朝一日能在舞台上绽放光彩。 漂亮,可爱,可爱,卡哇伊|
二次元,日系,王昭君,粉色长发少女,穿着粉色吊带露肩连衣裙,在练习室里练习唱歌,手中紧握着话筒。她已逐渐成长,离梦想更进一步,每一个音符都充满了她的热情与希望。 漂亮,可爱,可爱,卡哇伊|
二次元,日系,王昭君,粉色长发少女,穿着黑色连衣裙,站在试衣间里,心情忐忑。她即将迎来人生中的首次演出,内心充满了期待与紧张。 漂亮,可爱,可爱,卡哇伊|
二次元,日系,王昭君,粉色长发少女,穿着黑色礼服连衣裙,在舞台上唱歌。她终于实现了自己的梦想,站在了万众瞩目的舞台中央,歌声清脆动人,仿佛要将她的心声传递给所有观众。 漂亮,可爱,可爱,卡哇伊
"""
sttr=sttr.split('|')
for i,stt in enumerate(sttr):
image = pipe(
prompt=stt,
negative_prompt="丑陋、变形、嘈杂、模糊、低对比度、猫耳",
cfg_scale=4,
num_inference_steps=50, height=1024, width=1024,
)
image.save(f"{i}.jpg")
import numpy as np
from PIL import Image
images = [np.array(Image.open(f"{i}.jpg")) for i in range(0, 8)]
# image = np.concatenate([# np.concatenate(images[0:2], axis=1),
# np.concatenate(images[2:4], axis=1),
# np.concatenate(images[4:6], axis=1),
# np.concatenate(images[6:8], axis=1),
# ], axis=0)
# image = Image.fromarray(image).resize((1024, 2048))
# image
image = np.concatenate([images[i] for i in range(8)], axis=1)
image = Image.fromarray(image).resize((1024, 128))
image.save("all.jpg")
image
修饰词不是越多越好!!!


最后用上面的图片提交


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









