







这是学习大数据这一整套各种组件MySQL,hive,spark,mapreduce等等的一些基础语法,日常更新,有不对的地方欢迎指正,资料也是自己收集来的,若有侵权,联系我立马删。
MySQL
(一)创建数据库及表
1.创建数据库database
create databases 数据库名
use 数据库名
创建表格
create table 表名 (
字段名1 数据类型 [约束条件],
字段名2 数据类型 [约束条件],
[其他约束条件]
) 其他条件(储存引擎,字符集条件等选项);
代码示例:
create database test;
use test;
set names utf8;
create table dome (
id int unsigned not null auto_increment,
title varchar(40) not null,
price decimal(11,2),
thumb varchar(225),
author varchar(20),
publisher varchar(50),
primary key(id)
) engine=myisam default charset=utf8;
查看正在使用的数据库:
select database();
2.删除数据表
丢掉:drop
表:table
删除数据表:drop table 数据表名称;
drop database 数据库名称
drop table 表名
drop database test;
drop table dome;
3.查看数据库表结构
describe 表名
简写desc 表名
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ITh35Xp2-1658977075600)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220701102836994.png)]
4.表的基础操作
I.向数据表中插入数据
基本语法:
插入:insert
向数据表中插入数据:
insert into 数据表名称([字段1,字段2…]) values (字段值1,字段值2…)
varchar类型的要输入双引号
代码示例:
insert into dome
values
(01,"apple",9.99,"yes","张三麻子","good");
II.修改字段数据类型
alter table 表名 modify column 字段名 类型 约束 [默认值, 注释];
alter table dome modify column id int(10) not null;
III.更新数据表中的记录
基本语法:
更新:update
update 数据表名称 set 字段(列) = 更新后的值,字段(列) = 更新后的值 where 条件;
IV.更新数据表中的记录
基本语法:
更新:update
update 数据表名称 set 字段(列) = 更新后的值,字段(列) = 更新后的值 where 条件;
update dome set author='替换值' where author='被替换的值';
V.数据表中删除数据(重点)
基本语法:
删除:delete
delete from 数据表名称 where 条件;
① delete from 数据表名称;
② truncate 数据表名称;
两者的功能都是删除所有数据,但是truncate删除的数据,其主键(primary key)会重新编号。而delete from删除后的数据,会继续上一次编号。
delete from dome where id=2;
(二)数据库常见操作
1.查看所有mysql的编码
show variables like 'character%';
#client connetion result 和客户端相关
database server system 和服务器端相关
将客户端编码修改为gbk.
set character_set_results=gbk; / set names gbk;
以上操作,只针对当前窗口有效果,如果关闭了服务器便失效。如果想要永久修改,通过以下方式:
在mysql安装目录下有my.ini文件
default-character-set=gbk 客户端编码设置
character-set-server=utf8 服务器端编码设置
注意:修改完成配置文件,重启服务
2.追加主键
Alter table 表名 add primary key(字段列表);
2.1更新主键 & 删除主键
没有办法更新主键: 主键必须先删除,才能增加.
Alter table 表名 drop primary key;
3.创建索引
建表的时候创建索引,也可以在已存在的表上添加索引。
CREATE TABLE 表名称(
......,
INDEX [索引名称] (字段),
......
);
3.1添加索引
CREATE INDEX 索引名称 ON 表名(字段); /*添加索引方式1*/
ALTER TABLE 表名 ADD INDEX 索引名称(字段); /*添加索引方式2*/
唯一索引:
CREATE UNIQUE INDEX 索引名称 ON 表名(字段)
联合索引:
CREATE INDEX 索引名称 ON 表名(字段1,字段2...)
3.2查询索引
SHOW INDEX FROM t_message;
3.3删除索引
/* 在t_message表中删除idx_type索引 */
DROP INDEX idx_type ON t_message;
3.4索引的使用原则
-
数据量很大,且经常被查询的数据表可以设置索引 (即读多写少的表可以设置索引)
-
索引只添加在经常被用作检索条件的字段上 (比如电子商城需要在物品名称关键字加索引)
3.不要在大字段上创建索引 (比如长度很长的字符串不适合做索引,因为查找排序时间变的很长)
(三)条件查询
语法:select 字段 from 数据库 where 条件;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IBTwn77B-1658977075601)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704151010931.png)]
1.like模糊查询
% 匹配任意个字符
下划线,只匹配一个字符
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-chfu1epS-1658977075601)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704151257699.png)]
2.排序——order by
语法:select 字段名 from 表名 order by 字段名(根据该来排序);
语法:select 字段名 from 表名 order by 字段名(根据该来排序) desc; (降序)
2.1.根据多行字段进行排序
eg:查询员工的工资和名字,并按照升序进行,但是工资相同需要通过姓名来排序
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZI6YYQhg-1658977075602)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704151644373.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YgeSWXli-1658977075602)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704151806872.png)]
2.2根据字段位置来进行排序
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UMHFpXDt-1658977075602)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704151921444.png)]
(四)函数及查询
1.大小写转换函数
select 函数名(字段名) from 表名;
lower将大写转化为小写
upper将小写转换为大写
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TX2i4rJr-1658977075603)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704152442520.png)]
2.substr 取子串
substr(需要截取的字段,起始下标,截取长度) 起始下标是以1开始的
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cX2xjPHW-1658977075603)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704152804635.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SfgeYYyL-1658977075604)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704153046260.png)]
3.concat函数进行字符串的拼接
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Va5RT6CE-1658977075604)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704153409619.png)]
4.length 获取长度
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7VyWycdE-1658977075604)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704153844134.png)]
select LENGTH(ename) as mylength from emp;
5.trim 去空格
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rarjRP5j-1658977075605)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704154102307.png)]
6.round 四舍五入
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IfvZWBf4-1658977075605)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704154138091.png)]
select ROUND(123.889,2) from emp;
7.ifnull (空处理函数)
可以将null转换为具体值注意:在数据库中只要有null参与数学运算,最终结果为null,不管加减乘除。
使用方法:ifnull(数据,指定成相应的数据)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mIgaQhE4-1658977075606)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704155211788.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9r98BH9u-1658977075607)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704155222876.png)]
8.case when then when then else end
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LZ4MYIPa-1658977075607)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704155906643.png)]
SELECT
ename,
sal AS oldsal,
LOWER(job),
(
CASE job
WHEN 'manager' THEN
sal * 1.1
WHEN 'salesman' THEN
sal * 1.5
ELSE
sal
END
) AS newsal
FROM
emp;
9.分组函数(多行处理函数)
count 计数 max 最大值 min 最小值
avg 平均值 sum 总值 自动忽略null
select min(sal) from emp;
第一点:分组函数可以自动忽略null
第二点:count()和count(具体的字段)count():统计表当中的总行数count(具体的字段):表示统计该字段下所有不为null的字段
第三点:分组函数不能直接使用在where子句中
select job,sum(sal) from emp group by job;
10.分组查询(非常重要)
select ……
from ……
where ……
group by ……
order by ……
10.1 执行顺序步骤:
第一步:from
第二步:where
第三步:group by
第四步:select
第五步:order by
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9QgvSXkt-1658977075608)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704163532943.png)]
10.2 分组的条件查询 having
having 可以对分完组的数据进行再次筛选
注意:having不能单独使用,having也不能代替where,having必须和group by联合使用
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-um3thFLf-1658977075608)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220704172525199.png)]
SELECT job,avg(sal) from emp GROUP BY job HAVING avg(SAL)>2500;
SELECT
job,
avg(sal)
FROM
emp
GROUP BY
job
HAVING
avg(SAL) > 2500
ORDER BY
avg(SAL) DESC;
10.3对查询结果进行去除重复数据
distinct 要放在需要查重的字段前面
select distinct job from emp;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UfUDu6Yw-1658977075609)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220705090558287.png)]
10.4统计工作岗位的数据
select count(distinct job) from emp;
11.连接查询
11.1连接查询概论
连接查询:是将多张表联合查询
11.2根据表的连接方式分类
内连接:
等值连接 非等值连接 自连接
外连接:
左外连接(左连接)右外连接(右连接)全连接(一般不用)
11.3笛卡尔积现象及解决办法
当两张表进行连接查询的时候,最后查询的结果是两张表行数的乘积,这种现象被称为笛卡尔积现象。
注意:表与表的联合查询,查询的次数表的行数乘以表的行数。
eg:查询员工名字和部门名字
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hCHM4URP-1658977075609)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220705092635891.png)]
select ename,dname from emp,dept;
#这样联合查询会出现笛卡尔积现象,会导致数据爆炸
解决:笛卡尔积现象
只需在查询的时候加上筛选条件即可
eg:查询员工名字和部门名字
select ename,dname from emp,dept where emp.deptno=dept.deptno;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hJ0zIxtt-1658977075610)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220705093439889.png)]
优化版:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A5wkzuDy-1658977075610)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220705093654852.png)]
select e.ename,d.dname from emp as e,dept as d where e.deptno=d.deptno;
注意:通过笛卡尔积现象,说明了表连接越多,效率越低
11.4内连接
11.4.1内连接之等值连接
eg:查询每一个员工所在部门名称,显示员工名和部门名?
select e.ename,d.dname from emp as e,dept as d where e.deptno=d.deptno;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YktVP0C7-1658977075610)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220705094613712.png)]
改进:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jfQkLISU-1658977075611)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220705094628763.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ACXG55SV-1658977075611)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220705094643366.png)]
select e.ename,d.dname from emp as e join dept as d on e.deptno=d.deptno;
内连接的基础语法:
select 字段名1,字段名2 from 表名1 join 表名2 on 具体条件
11.4.2 、内连接之非等值连接
eg:找到每一个员工的薪酬等级,要求显示员工名、薪资、薪资等级
select * from salgrade;
select e.name,e.sal,s.grade from emp as e join salgrade as s on sal between
SAPRK
1.spark的基本认知:
spark是一种快速通用可扩展性 的大数据分析引擎,hive是一个大数据存储框架。
什么叫做算子!!!就是对RDD进行操作的行为或者函数就叫算子。、
RDD的操作分为两类,一类是transformation(转化操作),另一类是Action(执行操作)
转换操作(Transformation) (如:map,filter,groupBy,sortBy,join等),转换操作也叫懒操作,也就是说从一个RDD转换生成另一个RDD的操作不是马上执行,Spark在遇到转换操作时只会记录需要这样的操作,并不会去执行,需要等到有执行操作的时候才会真正启动计算过程进行计算。 Transformation算子根据输入参数,又可细分为处理Value型和处理Key-Value型的。
Value数据类型的Transformation算子,这种变换并不触发提交作业,针对处理的数据项是Value型的数据。
Key-Value数据类型的Transfromation算子,这种变换并不触发提交 作业,针对处理的数据项是Key-Value型的数据对。
那么什么又是懒操作呢?
懒操作就是你在使用transformation算子操作RDD的时候,是为了把RDD转化成为另外一种RDD,这种操作并不是立刻执行,只是spark会记录这样之中操作(相当于在此处写下了对RDD操作变换的脚本),并不去执行,只有触发ACtion算子操作的时候,才会去执行启动进程进行一个计算。
不管是Transformation里面的操作还是Action里面的操作,我们一般会把它们称之为算子,例如:map 算子、reduce算子
执行操作(Action) (如:count,collect,save,reduce等),执行操作会返回结果或把RDD数据写到存储系统中。Actions是触发Spark启动计算的动因。
像Action算子这样的执行操作,其实就是会返回结果的那种,会有数据写入存储系统的那种,同时也只有Action操作能够触发spark启动
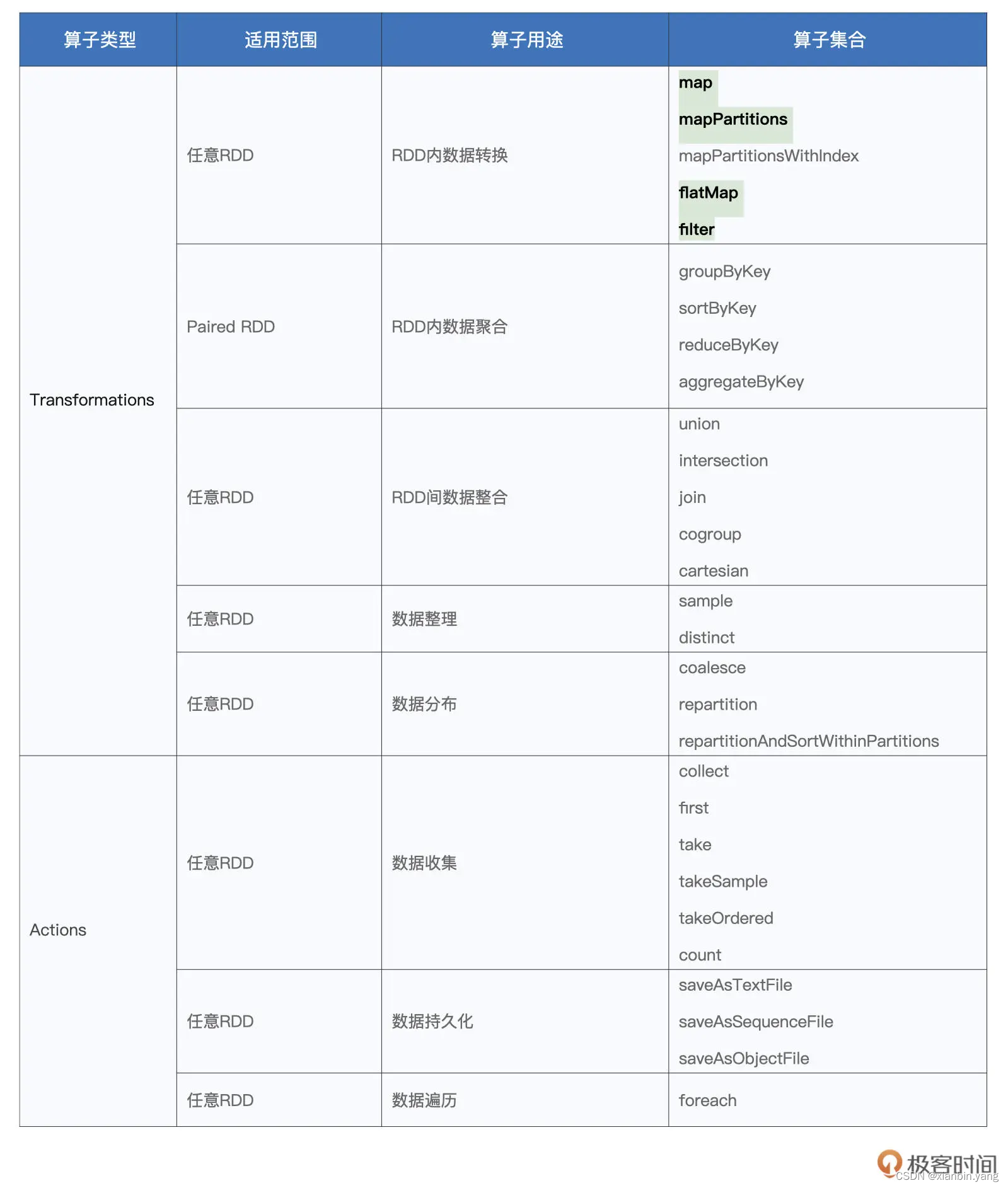
transformation算子[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CtNVge2J-1658977075612)(C:\Users\HP\Desktop\Typora笔记文档\image-20220711092335291.png)]
Action算子:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tDyScgJt-1658977075613)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220711092411416.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LZEoQP6b-1658977075613)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220711095202268.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8rHJtZCe-1658977075613)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220711095216321.png)]
文件数据处理的生命周期
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5m6bakWc-1658977075614)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220711095405860.png)]
在 RDD 之上调用 toDebugString,Spark 可以帮我们打印出当前 RDD 的 DAG
RDD4大属性:
partitions:数据分片
partitioner:分片切割规则
dependencies:RDD
依赖compute:转换函数
RDD血缘
RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。将创建 RDD 的一系列 Lineage(血统)记录下来,以便恢复丢失的分区。RDD 的 Lineage 会记录 RDD 的元数据信息和转换行为,当该 RDD 的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
宽窄依赖
RDD 依赖关系
这里所谓的依赖关系,其实就是两个相邻 RDD 之间的关系:
RDD 窄依赖
窄依赖表示每一个父(上游)RDD 的 Partition 最多被子(下游)RDD 的一个 Partition 使用,
窄依赖我们形象的比喻为独生子女。
RDD 宽依赖
宽依赖表示同一个父(上游)RDD 的 Partition 被多个子(下游)RDD 的 Partition 依赖,会
引起 Shuffle,总结:宽依赖我们形象的比喻为多生。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2119
2119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









