






 本文介绍了在使用Python Selenium进行Web自动化时,如何通过Xpath进行元素定位。作者建议避免使用绝对和相对路径,转而采用模糊定位和按序定位方法,特别是结合文本内容和元素顺序来定位。在遇到元素无法直接点击的情况,如文本位于<span>标签中,建议定位相邻元素。同时,分享了检查Xpath是否正确的方法,以及在多标签页环境下如何切换标签页寻找特定元素。
本文介绍了在使用Python Selenium进行Web自动化时,如何通过Xpath进行元素定位。作者建议避免使用绝对和相对路径,转而采用模糊定位和按序定位方法,特别是结合文本内容和元素顺序来定位。在遇到元素无法直接点击的情况,如文本位于<span>标签中,建议定位相邻元素。同时,分享了检查Xpath是否正确的方法,以及在多标签页环境下如何切换标签页寻找特定元素。
这两天尝试写selenium爬虫时遇到的问题,Xpath的定位我会优先考虑属性定位:

绝对路径定位我完全不推荐,相对路径定位能不写就不写,这两个的稳定性都很差,网页稍有改动,就有可能导致路径失效。后来我尝试使用Xpath的模糊定位:

我尝试定位所有含有”自动控制'这四个字的文本并点击它,我成功了,但在之后的应用中我发现一个问题,有一些网站的文本是这样的:
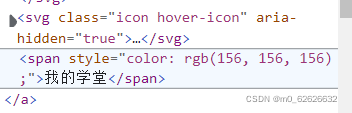
文本位于<span></span>中,而span这个标签是不能执行click()这个指令的,想要点击就必须定位上一行或下一行的元素,但在网站中这样元素相同的有7个,所以我尝试让脚本定位7个相同元素中的第一位元素:

成功运行,所以我们可以用文本定位和按序定位解决大部分的元素定位问题,关于Xpath定位,有个大佬讲得很好,附上链接: https://www.cnblogs.com/liuhui0308/p/11937139.html
说一下如何在网站中查看Xpath是否有问题:
1.打开开发者工具(按F12)
2.选择元素(elenment)
3.ctrl+F打开输入框,打开后是这样:
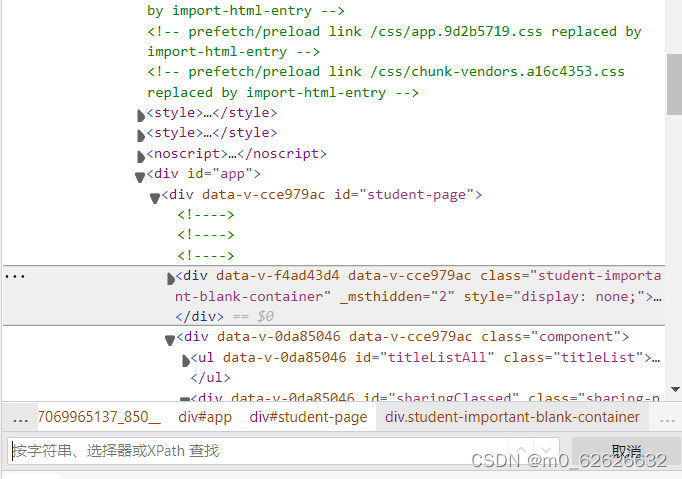
4.输入Xpath后:
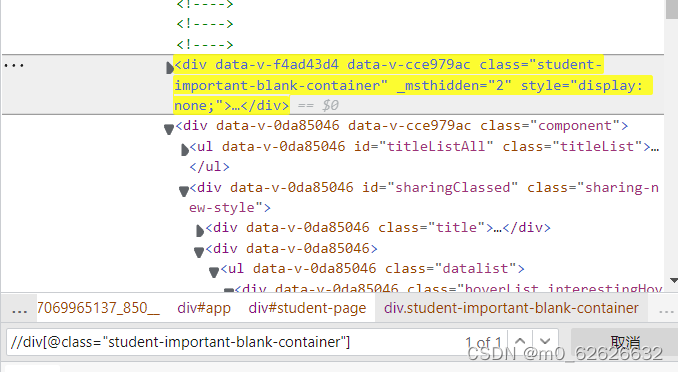
与Xpath匹配的元素被标成黄色,右边的数字第一个表示这是第几个匹配的元素,第二个表示共有多少个元素与你的Xpath匹配,1 of 1时脚本就可以找到你要的元素,就说明你的Xpath没有问题,找不到元素是别的原因,有可能是你的脚本已经打开了两个以上的标签页,你要找第二个标签页的元素,而脚本在默认的情况下执行第一个标签页,在第一页找第二页的元素,当然找不到了,
这时我们需要脚本跳转到第二页去再寻找元素:

第一行储存打开的所有标签页,第二行储存当前的标签页,for循环中如果是第一页则跳转到第二页;这样再寻找元素就没有问题了,这是我参照的文章:https://blog.youkuaiyun.com/weixin_44110998/article/details/103687022?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_title~default-0.pc_relevant_aa&spm=1001.2101.3001.4242.1&utm_relevant_index=3


















 4950
4950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









