







目录
其实爬虫可以用js,c,Java等等,但是python比较简单一点而且第三方库比较完善相对适合于我这样的新手,然后运行环境就是pycharm。
robots.txt协议
约定了网站中哪些可以爬哪些不可以
爬虫
爬虫:通过程序获得互联网上的资源
关于Web请求
1.......
第一种以在百度网页搜索某些东西为例:
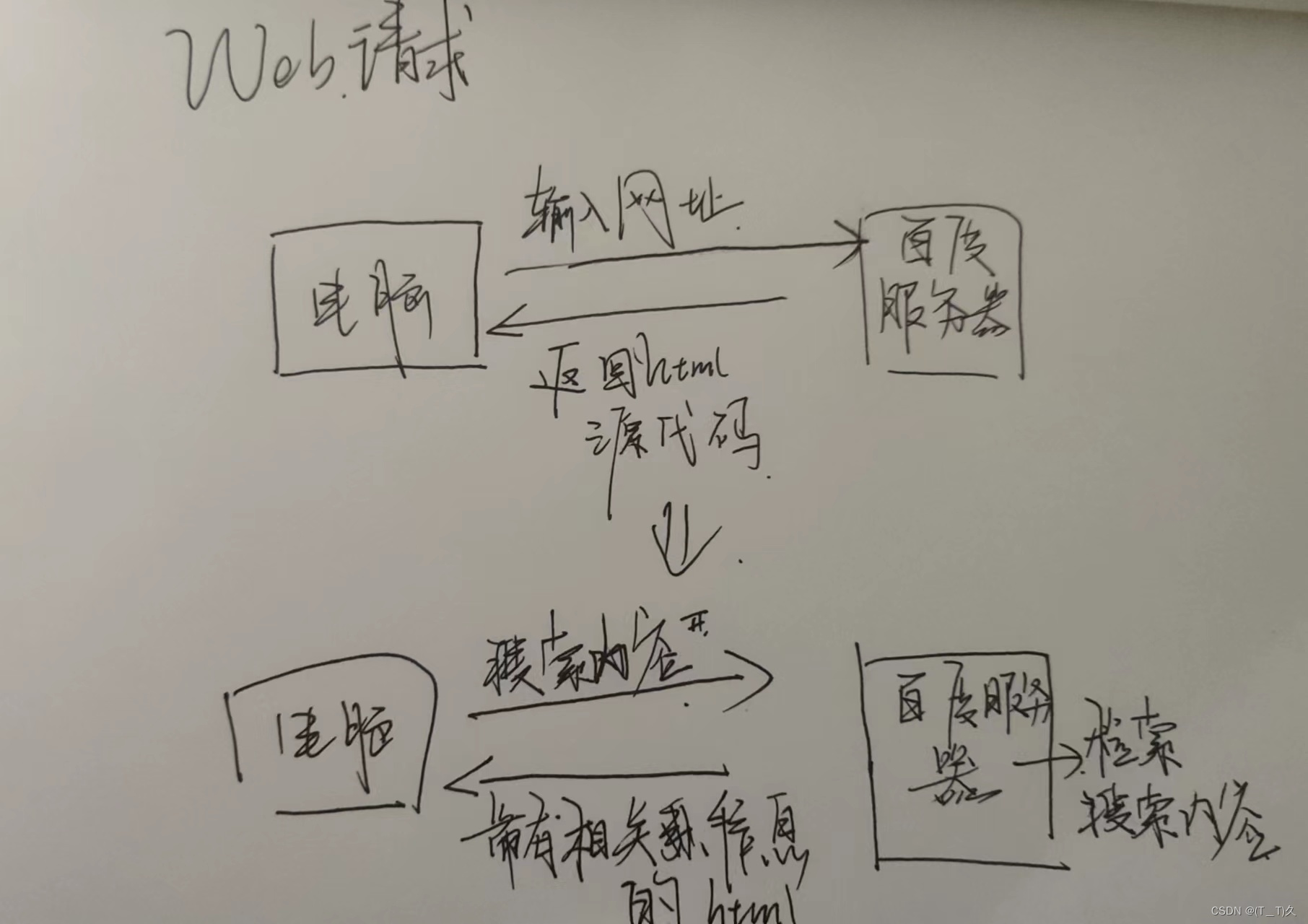
假设搜索新闻
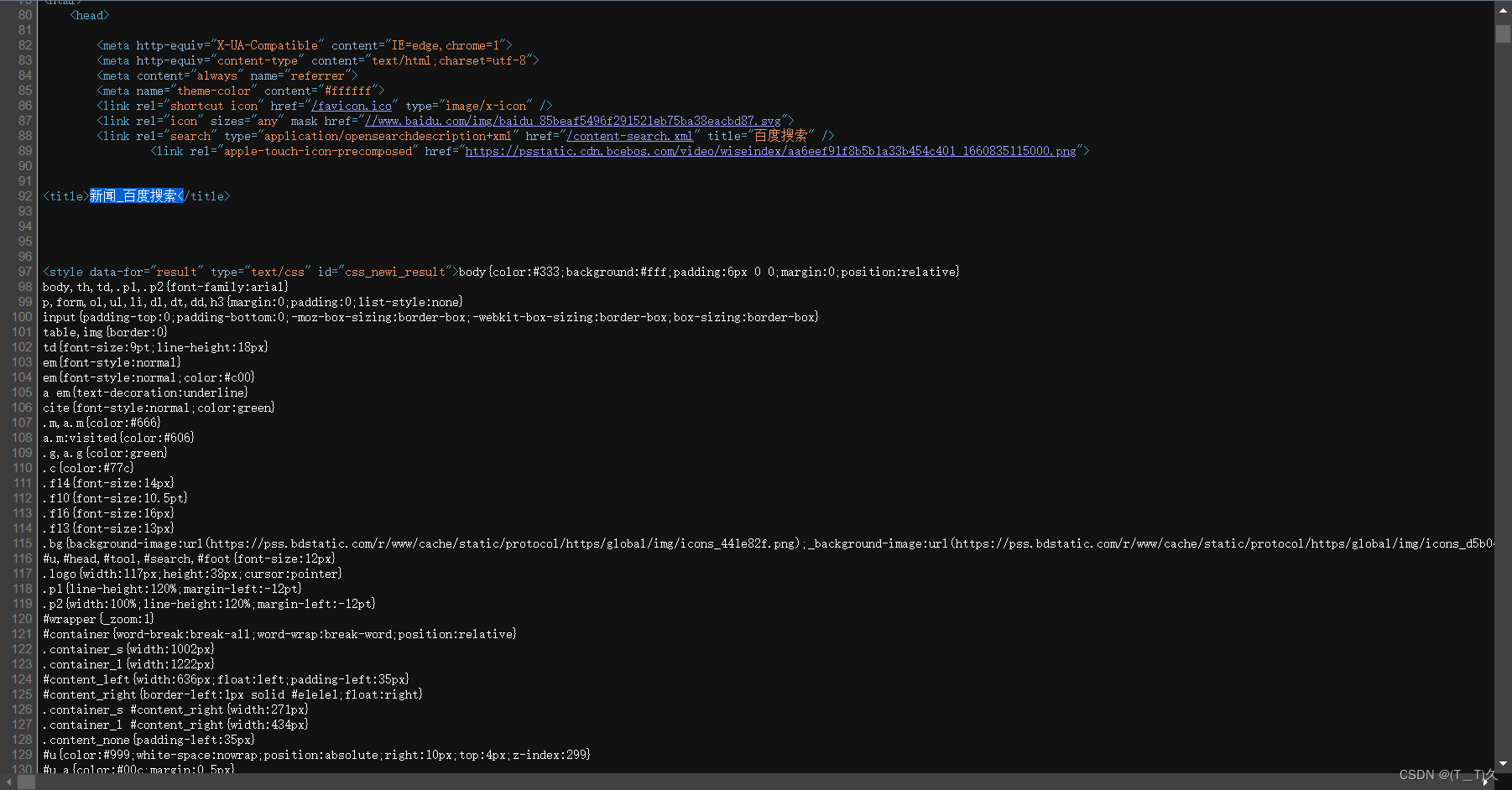
查看网页源代码时是可以看到搜索内容是嵌入在html里面的。
2..........第二种
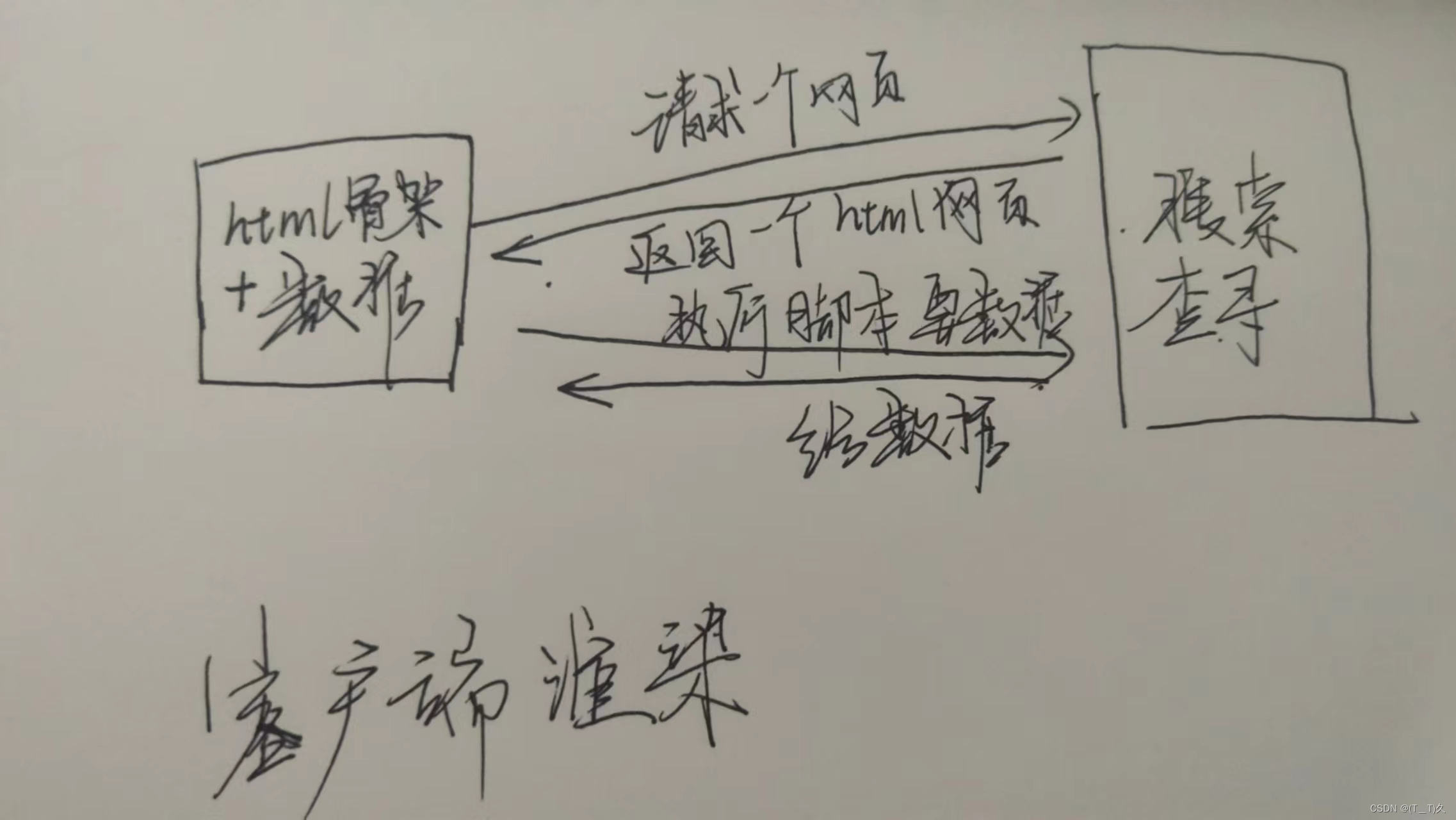
--1.服务器渲染,在服务器直接把数据和html整合在一起,一起返回给浏览器
--2.客户端(就是浏览器)渲染,第一次返回一个html骨架,第二次拿到数据,然后客户端整合结合html骨架和数据(打开页面源代码发现看不到数据)
关于抓包工具
抓包:利用特定的软件对网络数据包进行拦截,通过对抓获数据包的内容进行分析,可以得到有用的信息。
浏览器打开:f12或者右键一个检查
关于http协议
超文本传输协议在计算机网络里面重点学了,还是比较熟悉的。
超文本
html为超文本标记语言,HTTP协议就是传输页面源代码.
请求和响应
还有一些知识关于请求和响应
get和post
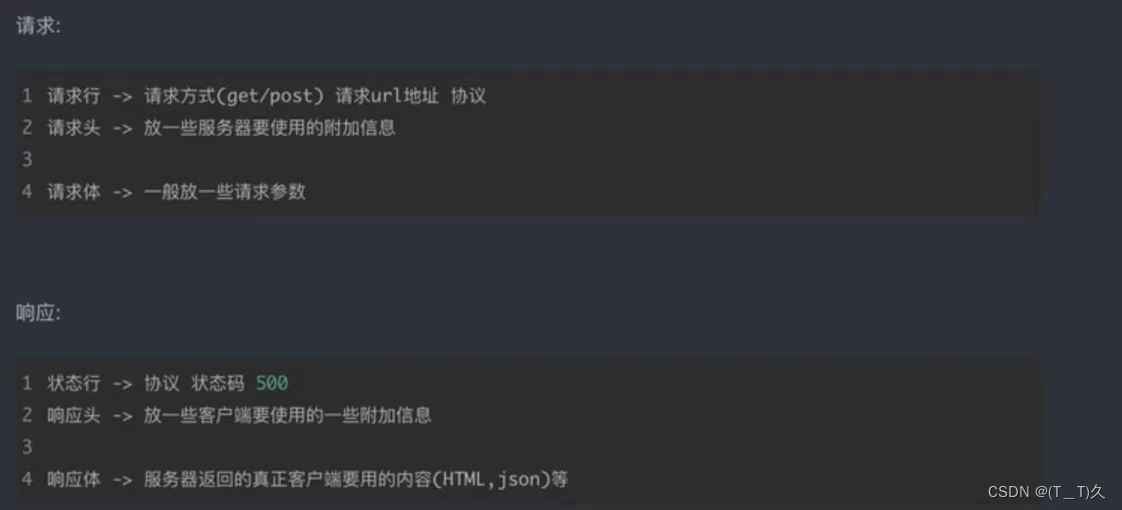

get:查询东西的时候(显式提交)
#在地址栏里面的统一都是使用的Get请求

post:修改,对服务器里面的东西修改或者提交(隐式提交)
网络爬虫
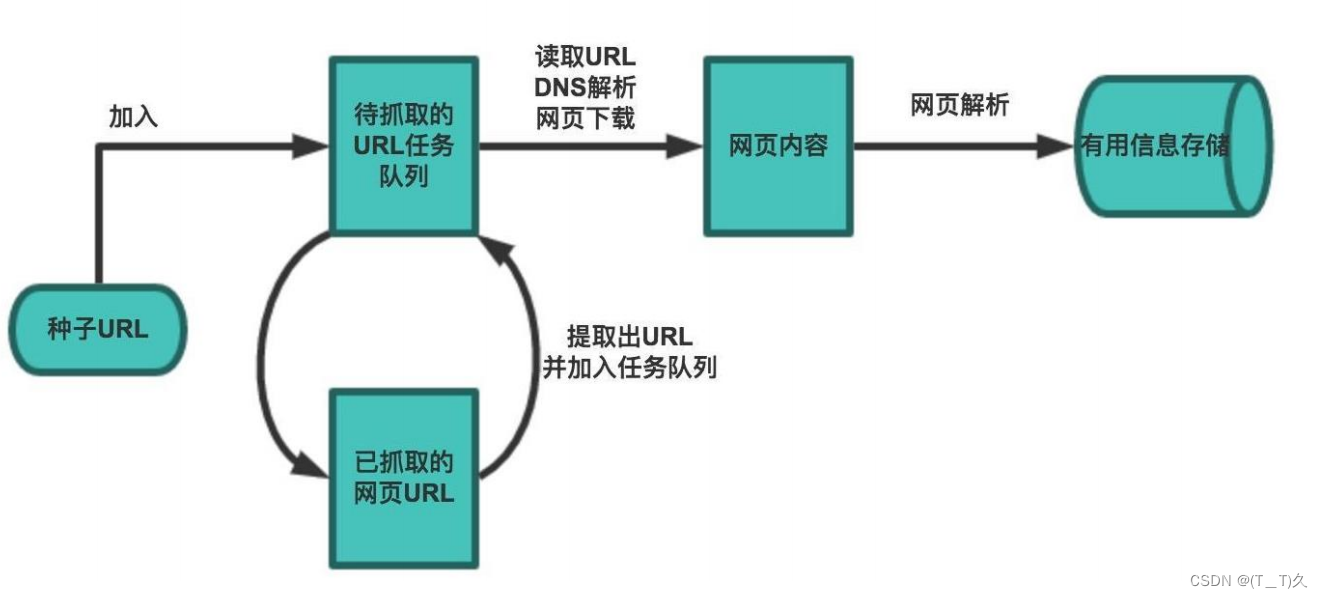
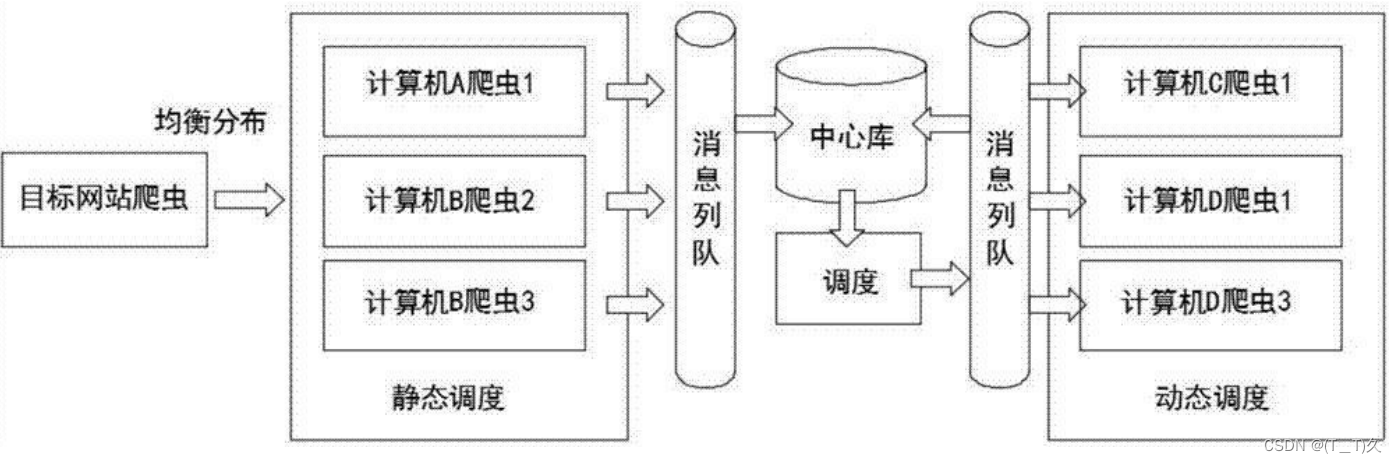
网络爬虫-分布式
关于requests模块
在终端(Terminal)里面输入
pip install requests#安装模块关于requests安装测试
import requests
url = requests.get("http://www.baidu.com")
print(url.status_code)结果200就是 成功了

使用requests模块写简单的爬虫
在百度这个网站搜索“周杰伦”
import requests
#复制过来之后出现一点变动
url = 'https://www.sogou.com/web?query=周杰伦'#转码直接换成搜索内容
resp = requests.get(url)#获得一个响应
print(resp)#响应结果
print(resp.text)#得到页面源代码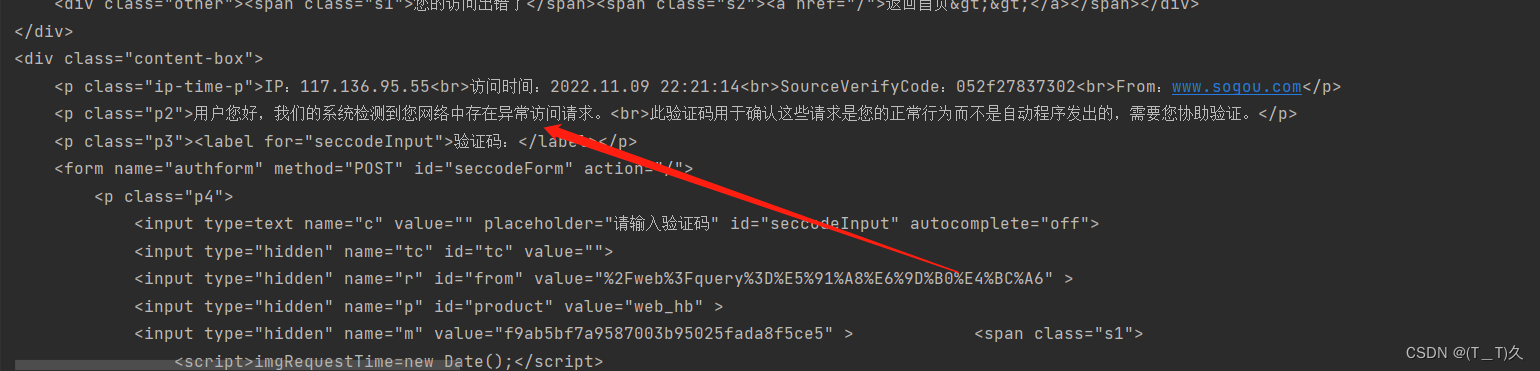
get请求和第一个反爬
1.在搜狗搜索了周杰伦结果不能爬取,要求给一个验证,然后使用抓包工具找到了浏览器请求,即告诉服务机是浏览器获得数据而不是爬虫程序
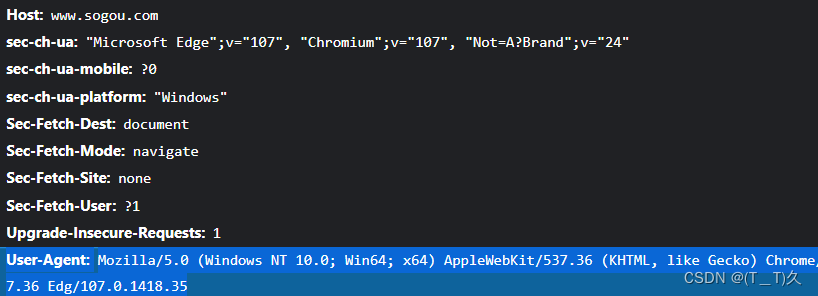
import requests
#url = 'https://www.baidu.com/s?ie=utf-8&f=3&rsv_bp=1&rsv_idx=1&tn=baidu&wd=%E5%91%A8%E6%9D%B0%E4%BC%A6'
#复制过来之后出现一点变动
url = 'https://www.sogou.com/web?query=周杰伦'
#转码直接换成搜索内容
dic = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.35"
}
#一个很小的反爬
resp = requests.get(url, headers=dic)#获得一个响应
print(resp)
print(resp.text)#得到页面源代码2.爬豆瓣搞笑电影榜单:
import requests
url = "https://movie.douban.com/j/chart/top_list"
#重新封装参数
pa = {
"type": "24",
"interval_id": "100:90",
"action": "",
"start": 0,
"limit": 20,
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.35"
}
resp = requests.get(url=url, params=pa, headers=headers)
# print(resp.request.url)
print(resp.json())# 遇到反爬首先考虑user-agent
#print(resp.request.headers)#查看py默认的user-agent
一开始我直接把get写成post请求,找了半天没找到,一直以为写的是get请求,找半天没有结果,我还以为又被反爬了呢
关于post请求
使用post请求爬取百度翻译
打开抓包工具找到sug这个包

可以看到用的是post请求
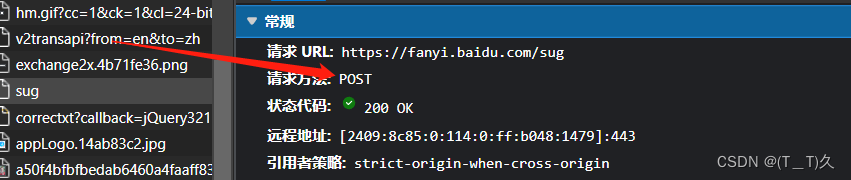
这个时候程序里的url就不是搜索框里的那个网址了而是请求URL
代码 :
import requests
url = "https://fanyi.baidu.com/sug"
s = input("请输入要翻译的内容:")
dat = {
"kw":s
}
resp = requests.post(url, data=dat)
print(resp.json())#将服务器返回的内容直接处理成json()=>dict
resp.close()

关于一些补充:
**1 服务器渲染:在服务器那边直接把数据和html整合在一起,统一返回给浏览器
**在页面源代码中能看到数据
**2.客户端渲染:第一次请求只要一个html骨架,第二次请求拿到数据,进行数据展示
**在页面源代码中看不到数据
数据解析
re解析 --正则表达式
元字符:


量词:
控制元字符出现的次数

之前写过贪婪匹配和懒惰匹配

关于re的函数
1.findall
import re
lst = re.findall(r"\d+", "he 的手机号是:0987654,my 手机号是:123456789")
print(lst)匹配字符串中所有符合正则的内容,返回一个列表,效率不高
2.finditer
import re
it = re.finditer(r"\d+", "he 的手机号是:0987654,my 手机号是:123456789")
print(it)
for i in it:
print(i.group())匹配字符串中所有符合正则的内容,返回一个迭代器,效率高
3.search
import re
s = re.search(r"\d+", "he 的手机号是:0987654,my 手机号是:123456789")
print(s.group())找到第一个结果就返回,返回的结果是match对象,那数据要用group()
4.
import re
s = re.match(r"\d+", "h0987654,my 手机号是:123456789")
print(s.group())
这个报错,就是没有匹配到内容
import re
s = re.match(r"\d+", "0987654,my 手机号是:123456789")
print(s.group()) ![]()
此时输出正常,返回匹配到的第一个内容,并返回
预加载正则表达式
即编译一段正则
import re
obj = re.compile(r"\d+")
r = obj.finditer("0987654,my 手机号是:123456789")
print(r)注:
re.S就是让.能匹配换行符
利用正则筛选数据
import re
s = '''
<li class=""><a href="https://www.douban.com/group" </li>
<li class=""><a href="https://read.douban.com/?dcs=top-nav&dcm=douban" </li>
<li class=""><a href="https://douban.fm/?from_=shire_top_nav" </li>
<li class=""><a href="https://time.douban.com/?dt_time_source=douban-web_top_nav" </li>
<li class=""><a href="https://market.douban.com/?utm_campaign=douban_top_nav&utm_source=douban&utm_medium=pc_web" </li>
'''
obj = re.compile(r'<li class=""><a href="(?P<url>.*?)" </li>', re.S)
r = obj.finditer(s)
for it in r:
print(it.group("url"))
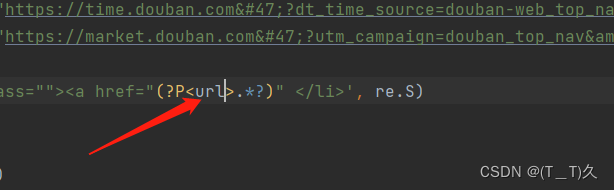 (
(
(?P<分组名字>正则表达式):可以单独从匹配到的内容中进一步提前括号中的内容
实例
豆瓣爬取:
利用.*?惰性匹配到空格和换行符

import re,requests
#拿到页面内源代码
url = "https://movie.douban.com/top250"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.42"
}
resp = requests.get(url, headers=headers)
page_content = resp.text
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)'
r'</span>.*?<p class="">.*?<br>(?P<year>.*?) .*?'
r'<span class="rating_num" property="v:average">(?P<count>.*?)</span>', re.S)
result = obj.finditer(page_content)
for it in result:
print(it.group("name"))
print(it.group("count"))#输出评分
print(it.group("year").strip())#对年份处理,使匹配到的内容中前面的空白消除
resp.close()
将数据存到csv里面
import re,requests
import csv
#为了数据分析将数据存成csv
#拿到页面内源代码
url = "https://movie.douban.com/top250"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.42"
}
resp = requests.get(url, headers=headers)
page_content = resp.text
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)'
r'</span>.*?<p class="">.*?<br>(?P<year>.*?) .*?'
r'<span class="rating_num" property="v:average">(?P<count>.*?)</span>', re.S)
result = obj.finditer(page_content)
f = open("date.csv", mode="w")
csvwriter = csv.writer(f)
for it in result:
dic = it.groupdict()
dic['year'] = dic['year'].strip()
csvwriter.writerow(dic.values())
f.close()
print("over")
resp.close()
# print(resp.text)
生成了一个csv文件,我的默认双击打开是一个表格

网站爬取
要求:获得这一部分的链接信息,即请求子页面的链接地址,获得下载地址
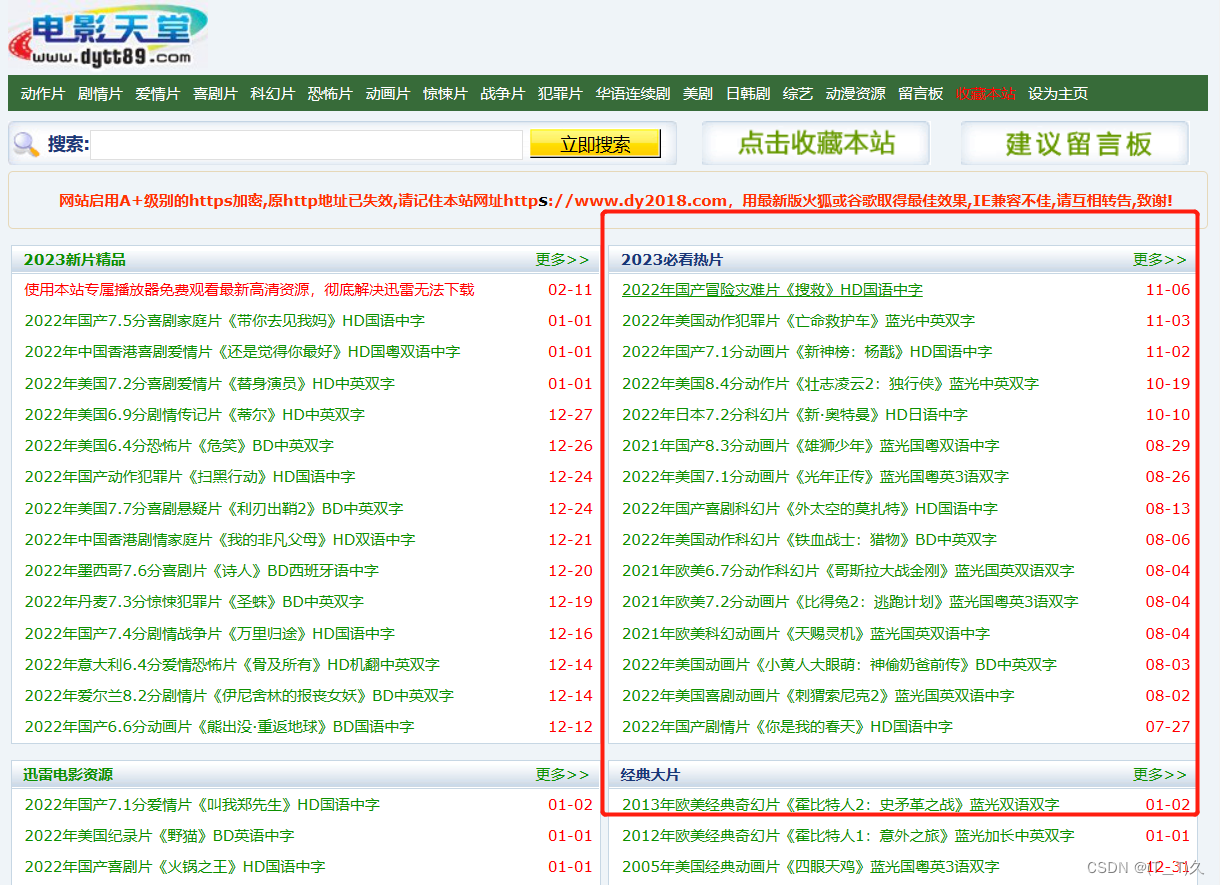
关于编码格式的问题:有时候pycharm默认utf-8,但是网站的编码格式不一样,通俗就是说这些字节本来是英文把他硬翻译成中文,结果肯定是错的。
找到对应要求的区域
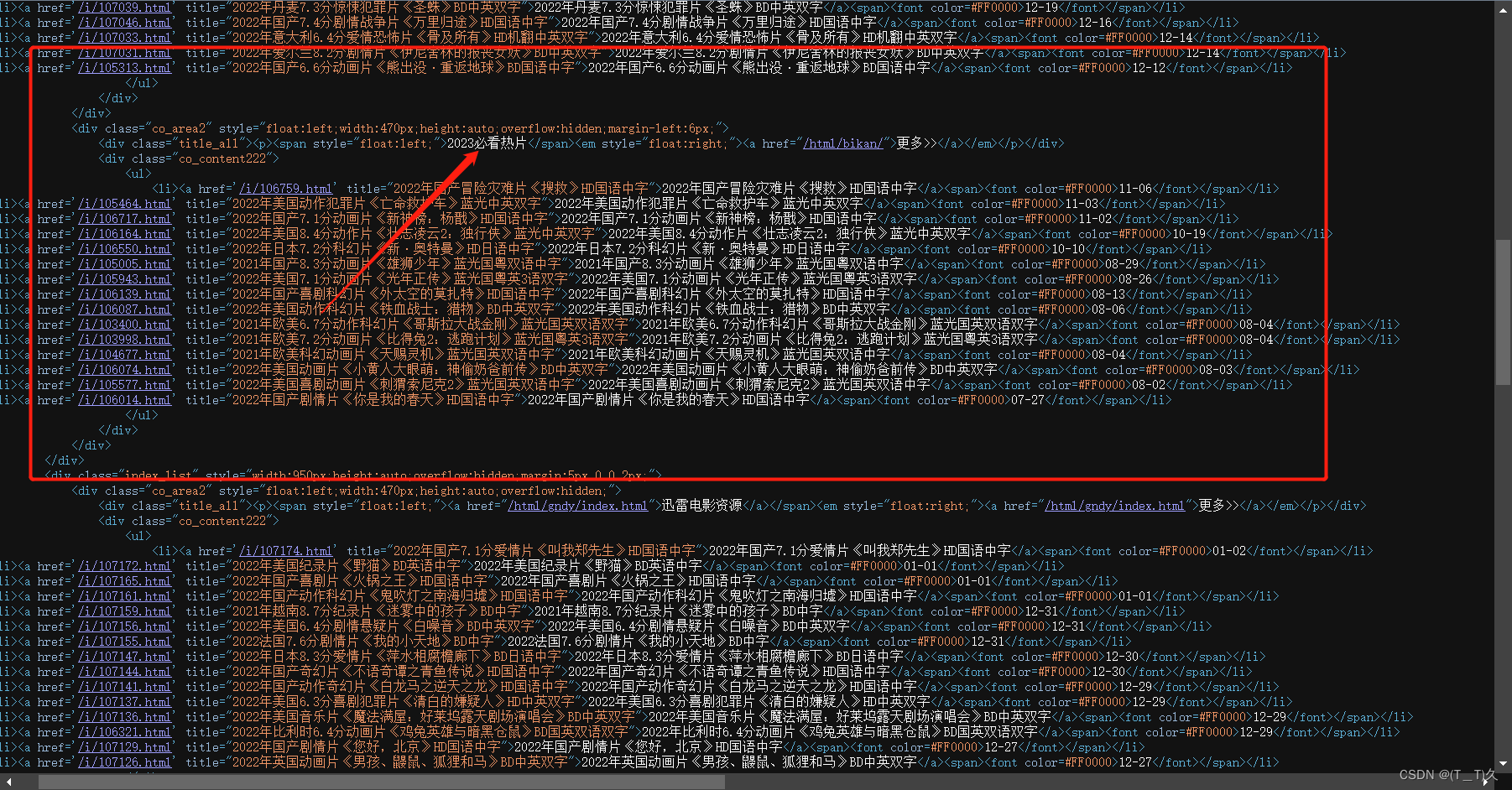
import requests
import re
domain = "https://www.dytt89.com/"
resp = requests.get(domain, verify=False)
#verify=False去掉安全验证
resp.encoding = 'gb2312'
#指定字符集
#print(resp.text)
#获得相应的网页源代码
obj1 = re.compile(r"2023必看热片.*?<ul>(?P<ul>.*?)</ul>", re.S)
obj2 = re.compile(r"<a href='(?P<href>.*?)'", re.S)
obj3 = re.compile(r'◎片 名(?P<movie>.*?)<br />.*?<td style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<down_load>.*?)"', re.S)
result = obj1.finditer(resp.text)
child_href_list = []
for it in result:
ul = it.group('ul')
#提取子页面链接
result2 = obj2.finditer(ul)
for itt in result2:
#拼接子页面url地址:域名加子页面地址
child_href = domain + itt.group('href').strip("/")
child_href_list.append(child_href)
#把子页面链接保存起来
print(child_href_list)
for href in child_href_list:
child_resp = requests.get(href, verify=False)
child_resp.encoding = 'gbk'
# print(child_resp.text)
result3 = obj3.search(child_resp.text)
print(result3.group("movie"))
print(result3.group("down_load"))
break#测试


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









