







本篇文章在记录(6)的基础上,进一步对微调前的模型进行测评,观察微调后的模型是否有更好的表现性能。
执行下列指令对微调前的模型在相同的数据集上进行评估:
python run.py --datasets ceval_gen
--hf-path /hy-tmp/7B21/internlm2_chat_7b
--tokenizer-path /hy-tmp/7B21/internlm2_chat_7b
--tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True
--model-kwargs trust_remote_code=True device_map='auto'
--max-seq-len 1024
--max-out-len 16
--batch-size 2
--num-gpus 1
--debug 得到结果: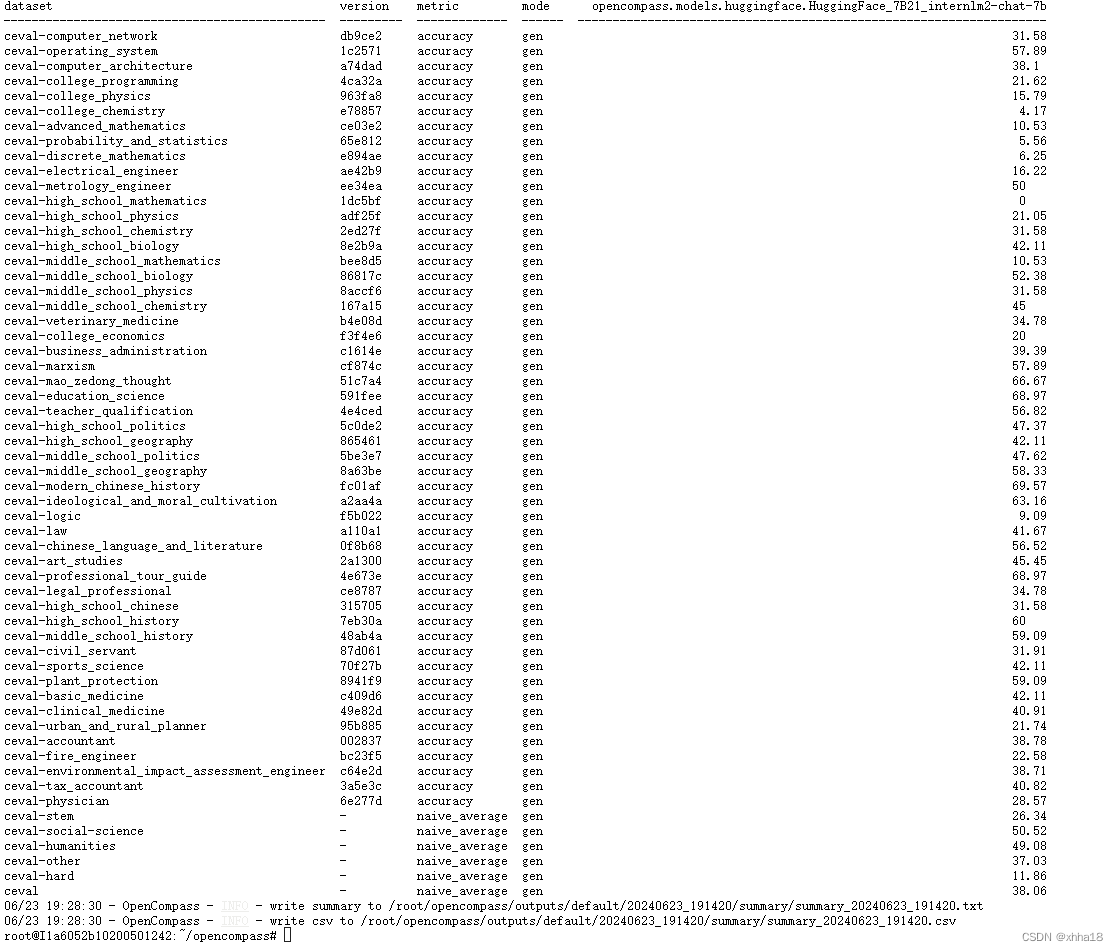
与上次评估的结果针对最后几行进行对比
量化前

量化后
 可以发现正确率有明显的提高,由此可以得出通过微调,我们得到了一个表现能力和性能更好的模型。
可以发现正确率有明显的提高,由此可以得出通过微调,我们得到了一个表现能力和性能更好的模型。
并且对微调后的模型在另一数据集ceval_clean_ppl上进一步评估:
python run.py --datasets ceval_clean_ppl
--hf-path /hy-tmp/7B21/merged
--tokenizer-path /hy-tmp/7B21/merged
--tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True
--model-kwargs trust_remote_code=True device_map='auto'
--max-seq-len 1024
--max-out-len 16
--batch-size 2
--num-gpus 1
--debug得出结果

C-Eval是目前权威的中文AI大模型评测数据集之一,C-Eval数据集主要用于评测大模型的知识和逻辑推理能力,即大模型是否能够认识和理解广泛的世界知识,并类似人类一样对事物进行推理规划。正确率较高,进步验证微调的结果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









