







1、你知道线程池实现“线程复用”的原理吗?
线程池主要由线程池管理器、任务队列和工作线程组成。下面以 Java 的 ThreadPoolExecutor 为例,简要介绍其底层源码实现:
Java中的 ThreadPoolExecutor 是 ExecutorService 接口的一个具体实现,用于创建和管理线程池。其底层源码主要涉及以下几个关键组件:
-
Worker Thread(工作线程):
ThreadPoolExecutor内部有一组工作线程,用于执行任务。这些线程可以复用,执行多个任务,避免了频繁地创建和销毁线程。 -
Task Queue(任务队列):
ThreadPoolExecutor使用任务队列来存储等待执行的任务。当线程池中的线程不够用时,新提交的任务会被放入任务队列中等待执行。 -
Thread Pool Manager(线程池管理器):线程池管理器负责调度任务并分配给工作线程。它维护着线程池的状态,根据任务队列和线程池配置来决定如何调度任务。
线程池执行流程:
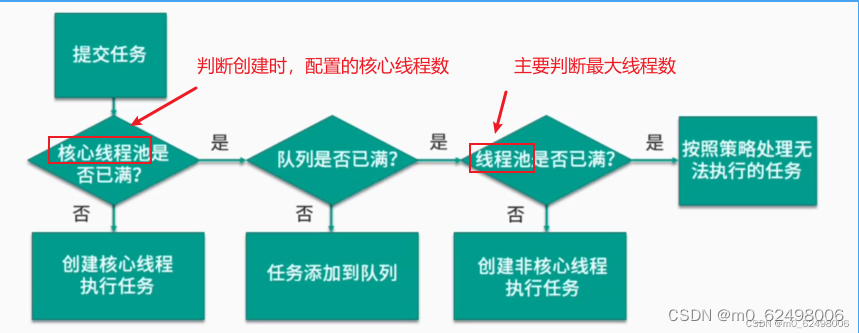
当我们使用线程池执行任务时,有三个方法在背后默默发挥作用,帮助线程池实现高效的任务执行:
-
execute(Runnable command)方法:- 当有新任务需要执行时,调用
execute()方法将任务提交给线程池。 execute()方法首先检查线程池的状态和配置,判断是否需要创建新的线程来执行任务,或者复用现有空闲线程。- 如果当前运行的线程数小于核心线程数,则尝试创建一个新线程,作为核心线程来执行任务。
- 如果核心线程数已满,将任务放入任务队列中等待执行。
- 如果任务队列也满了,而线程池的最大线程数还没有达到,将创建一个非核心线程来执行任务。
- 如果线程池已经达到最大线程数,且任务队列也满了,则执行设置的拒绝策略,拒绝接收新的任务。
- 当有新任务需要执行时,调用
-
addWorker(Runnable firstTask, boolean core)方法:- 在
execute()方法中确定需要创建新线程时,调用addWorker()方法来实际添加新的工作线程。 addWorker()方法根据线程池的状态和配置,判断是否满足添加新线程的条件。- 如果当前运行的线程数小于线程池的核心线程数,或者线程池的工作线程数还没有达到上限,则尝试添加新的工作线程。
- 在
-
runWorker(Worker w)方法:- 当有新的工作线程被创建或者需要执行任务时,调用
runWorker()方法来执行工作线程的主要任务。 runWorker()方法是工作线程的入口点,工作线程循环地从任务队列中获取任务并执行。- 在执行任务前,会检查线程池的状态,以及是否需要中断当前线程。
- 执行任务的
run()方法,并根据任务执行的结果处理异常情况。 - 执行任务后的
afterExecute()方法,用于执行任务后的清理和收尾工作。 - 循环执行任务直至任务队列为空,并对工作线程进行退出处理。
- 当有新的工作线程被创建或者需要执行任务时,调用
这三个方法在线程复用中相互协作,确保线程池中的线程得到合理地创建和复用,避免不必要的线程创建和销毁开销,从而提高多线程编程的性能和效率。通过线程复用,线程池能够高效地处理大量的任务,保持线程数在适当的范围内,同时避免资源的浪费和线程的频繁创建。
2、项目中使用过消息队列吗?用过哪些?当初选型基于什么考虑的呢?
例如一个外卖系统,用户在网站上提交订单并进行支付。在传统的系统中,订单和支付的处理可能是紧密耦合的,即用户提交订单后,系统立即处理支付,并等待支付完成后再继续处理后续步骤。
后来,我们引入消息队列来实现解耦、异步和削峰:
-
解耦:
- 当用户提交订单后,不再直接处理支付,而是将订单信息放入消息队列中。
- 订单处理模块和支付处理模块之间不再直接通信,而是通过消息队列来传递订单信息。
- 这样,订单处理和支付处理模块之间解耦了,它们不需要直接依赖对方的实现细节,可以独立开发和维护。
-
异步通信:
- 用户提交订单后,订单信息被放入消息队列,系统立即返回给用户订单提交成功的提示,而不需要等待支付处理完成。
- 订单处理模块可以继续处理其他订单,而支付处理模块可以在后台异步地从队列中获取订单信息并进行支付处理。
- 这样,用户体验更加流畅,系统的响应速度和吞吐量都得到了提升。
-
削峰填谷:
- 在某个时间点,系统可能会遇到突发的大量订单提交和支付请求,导致系统压力骤增。
- 使用消息队列,可以将大量订单请求缓冲在队列中,然后按照系统处理能力逐渐从队列中取出订单进行处理。
- 这样,系统可以平稳地处理高峰时段的流量,避免了系统过载和崩溃,保证了系统的稳定性。
通过引入消息队列,我们实现了订单处理和支付处理之间的解耦,将支付处理异步化,同时通过消息队列的削峰能力,确保了系统的高可用性和性能。这样的架构使得系统更加健壮和灵活,适应了不同场景下的需求。
但是在使用时,我们也得考虑一下问题,如:
系统可用性降低:例如mq突然就宕机了,这时系统就崩溃了,这是我们就得考虑如何保证消息队列的高可用性了。
系统复杂度提高:在加入mq后,我们应该要考虑怎么保证消息没有重复消费、怎么处理消息丢失、怎么保证消息传递的顺序性等问题了。
kafka、rabbitmq、rocketmq优缺点(技术选型):
单机吞吐量:
RabbitMQ:万级,比kafka、rocketmq低一个数量级。
RocketMQ:10万级,支撑高吞吐。
Kafka:万级,高吞吐,一般配合大数据类的系统来使用。
topic数量对吞吐量的影响:
- RabbitMQ:Topic数量对吞吐量是没有影响的。
- RocketMQ:topic达到几百/几千的级别,吞吐量会有较小幅度的下降,这是RocketMQ的一点优势,在同等集群下,可以支持大量的topic。
- Kafka:从几十到几百个时候,吞吐量会大幅度下降,在同等机器下,kafka经量保证topic数量不要过多,如果要大规模的topic,需要增加更多的机器资源。
时效性:
- rabbitMQ:微秒级别的,是这三个字时效性最好的。
- rocketMQ和kafka都是毫秒级别的。
可用性:
- rabbitMQ:实用性高,是基于主从架构实现高可用。
- rocketMQ:实用性非常高,可以使用分布式架构。
- kafka:实用性非常高,可以使用分布式,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用。
消息可靠性:
- rabbitMQ:数据基本不丢失(也会有少数的丢失情况)
- rocketMQ和kafka都是经过参数优化配置,可以做到0丢失。
功能支持:
- rabbitMQ:是基于erlang开发,并非能力很强,性能极好,延时极低。
- rocketMQ:功能较为完善,还是分布式的,扩展性好。
- kafka:功能较为简单,在大数据领域的实时计算以及日志采集被大规模使用。
各种对比后:
- rabbitMQ:是使用erlang语言开发的,所以需要java工程师去深入研究和掌握它,但是他是开源的,比较稳定的支持,社区活跃度也高。
- rocketMQ:是阿里巴巴开发的,目前已经捐给Apache,但是github上的活跃度其实不算高,对于公司技术实力绝对自信的,就比较推荐实用rocketMQ了。
- kafka:如果是大数据领域的实时计算、日志采集等场景,使用它觉对没有问题,社区活跃度很高。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









