







目录
一、图的定义和术语
术语:
无向完全图边数:n(n-1)/2;
有向完全图边数:n(n-1)
强连通图:对任何两个顶点v、u都有路径;
连通分量:无向图中的极大联通子图
强连通分量:有向图中的极大强连通子图
网络:带权图
二、图的存储结构
1.数组表示法(邻接矩阵)
(1)特点:
无向图:是对称矩阵;对角元素都是零
有向图:边的方向(行下标->列下标)
有权图:把1换成权值,没有边的替换为一个很大很大的数
(2)建立无向网络图算法详解
- 给顶点域赋值
- 给边域赋值:边域初始化(INFINITY);读入边及权重
(3)邻接矩阵的特点:
i.空间复杂度O(n^2)
ii.操作特点:边和弧的删除和插入操作容易;顶点的插入删除操作不容易
2.邻接表
顺序存储的顶点表+链接存储的边链表
顶点表:
typedef struct ArcNode{
vertextype data;//顶点信息
ArcNode *firstarc;//指向的第一条弧
}vnode,adjlist[MAX_VERTEX_NUM];
边表:
typedef struct ArcNode{
int adjvex;//该弧所指向的顶点的位置
struct ArcNode* nextarc;//指向下一条弧的指针
InfoType *info;//弧的相关信息的指针
}ArcNode;图:
typedef struct {
adjlist vertices;
int vexnum,arcnum;
int kind;
}ALGraph;
(1)建立无向图的邻接表的算法概要及详解
- 建立顶点表
for(i=1;i<G.vexnum;i++){
G.vertices[i].data=getchar();
G.vertices[i].firstarc=NULL;
}- 前插法建立边链表
for(i=0;i<mygraph->arcnum;i++){
int v1,v2;
scanf("%d %d",&v1,&v2);
//在v1后面加一个结点
ArcNode* fnode1;
fnode1=(ArcNode*)malloc(sizeof(ArcNode));
fnode1->adjvex=v2-1;
fnode1->info=NULL;
fnode1->nextarc=mygraph->vertices[v1-1].firstarc;
mygraph->vertices[v1-1].firstarc=fnode1;
//在v2后面加一个结点
ArcNode* fnode2;
fnode2=(ArcNode*)malloc(sizeof(ArcNode));
fnode2->adjvex=v1-1;
fnode2->info=NULL;
fnode2->nextarc=mygraph->vertices[v2-1].firstarc;
mygraph->vertices[v2-1].firstarc=fnode2;
}(2)邻接表的特点
i.对于顶点多边少的图采用邻接表存储节省空间;空间复杂度O(n+e)
ii.容易找到任一顶点的第一个邻接点
3.十字链表
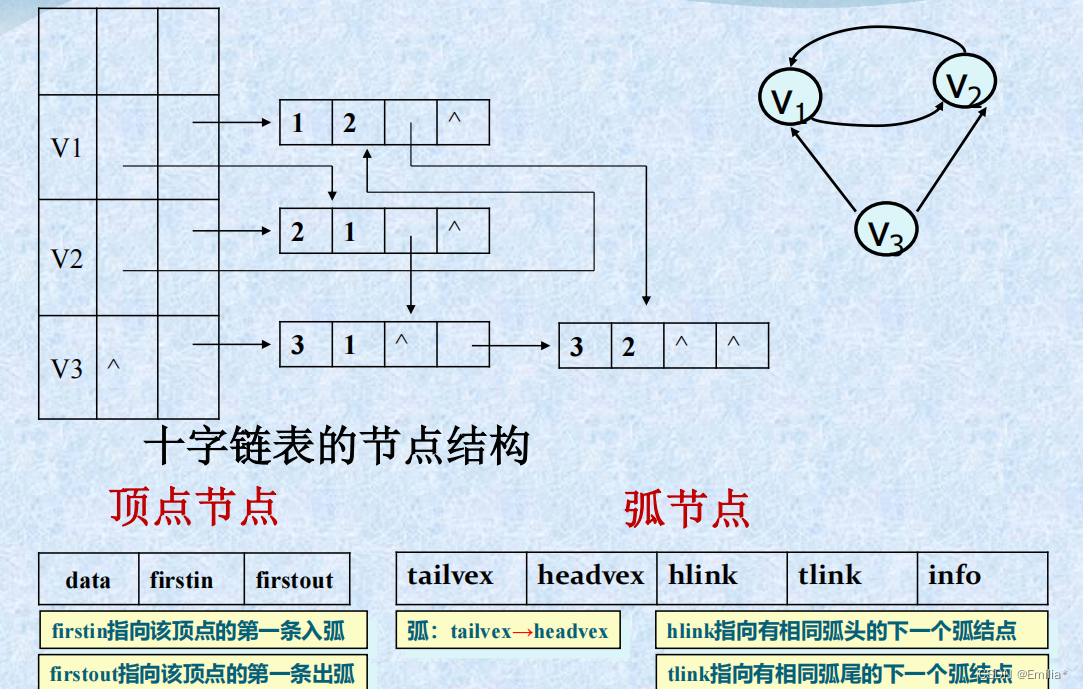
边表的存储结构:
typedef struct ArcBox{
int tailvex,headvex;
struct ArcBox *hlink,*tlink;
InfoType *info;
}ArcBox;顶点表的存储结构:
typedef struct{
VertexType data;
ArcBox *firstin,*firstout;
}Vexnode;十字链表的图的存储结构
typedef struct{
Vexnode xlist[MAX_VERTEX_NUM;
int vexnum,arcnum;
}OLGraph;
三、图的遍历
1.深度优先搜索
(1)连通图:
void DFS(Graph G,int v){
visited[v]=TRUE;
VisitFunc(v);
for(w=FirstAdjvex(G,v);w!0;w=NextAdjvex(G,v,w))
if(!visited[w]) DFS(G,w);
}(2)非连通图:
void DFSTraverse(Graph G){
int v;
int visited[VExnum];
for(v=0;v<G.vexnum;v++)
visited[v]=FALSE;
for(v=0;v<G.vexnum;v++)
if(!visited[v]) DFS(G,v);
}(3)算法分析:
邻接矩阵表示图:O(n)
邻接表表示图:O(n+e)//不是+2e,因为每访问一次,该结点visited数组就是TRUE了,第二次到 //该节点的时候是不会再次访问的
(4)功能
-
求深度优先生成树
-
判断图是否连通
-
求图的连通分量
2.广度优先搜索
(1)算法实现:
void BFSTraVErse(Graph G,Status(*Visit)(int v)){
for(v=0;v<G.Vexnum;++v) visited[v]=FALSE;
InitQueue(Q);
for(v=0;v<G.vexnum;++v){
if(!visited[v]){
visited[v]=TRUE;
Visit(v);
EnQueue(Q,v);
while(!EmptyQueue(Q)){
DeQueue(Q,u);
for(w=FirstAdjvex(G,u);w!0;w=NextAdjvex(G))//若为邻接表 则
//P=G.vertices[v].firstarc;p!=NULL;p=p->nextarc
if(!visited[w]){
visited[w]=TRUE;
Visit(w);
EnQueue(Q,w);
}
}
}
(2)算法分析:
邻接表:n+e
邻接矩阵:n^2
(3)功能:
- 求广度优先生成树
- 判断图是否连通
- 求图的连通分量
深度优先搜索->树的前序遍历;广度优先搜索->树的层次遍历
四、图的连通性问题
1.无向图的连通分量
在上面非连通图的DFS遍历里,每一个连通分量加一条输出语句即可

2.最小生成树
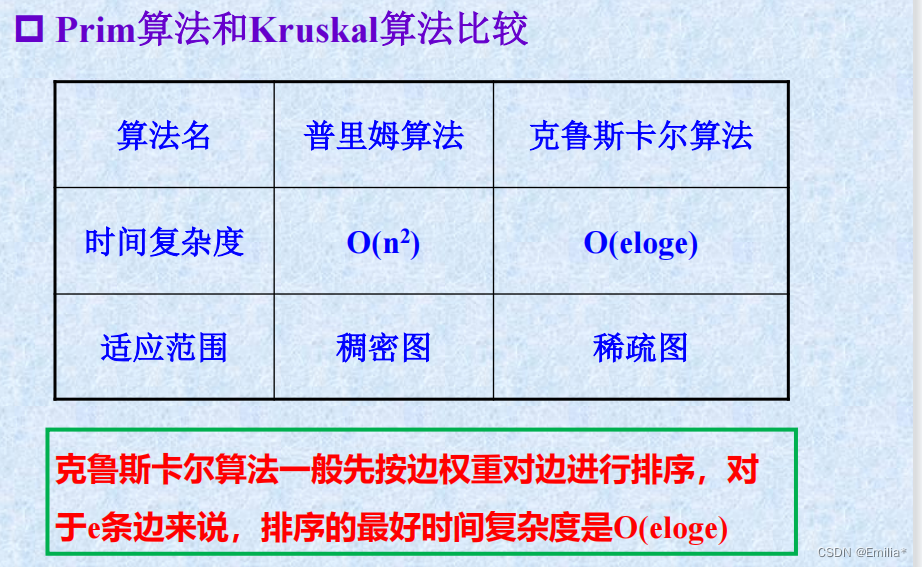
(1)普里姆(Prim)算法
void MiniSpanTree_P(MYGraph G,vertexType u){
k=Locatevex(u);//存储u的下角标
for(j=0;j<G.vexnum;++j)
if(j!=k)
closedge[j]={u,G.arcs[k][j].adj};//更新相应权值
closedge[k].lowcost=0;
for(i=1;i<G.vexnum;i++){//由于需要加入vexnum个结点,closedge表也就需要更新vexnum次
k=minimum(closedge);//求出生成树的下一个结点
printf(closedge[k].adjvex,G.vexs[k]);//输出生成树上的一条边
for(j=0;j<G.vexnum;j++)
if(j!=k)
closedge[j]={G.vex[k],G.arcs[k][j].adj};
closedge[k].lowcost=0;
}
}
算法分析:时间复杂度O(n^2)空间复杂度O(n)(有辅助数组)
(2)Kruskal算法



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









