







1.分布式计算概述
-
学习目标
1.了解什么是计算
2.了解什么是分布式计算
什么是计算、分布式计算?
-
计算:对数据进行处理,使用统计分析等手段得到需要的结果
-
分布式计算:多台服务器协同工作,共同完成一个计算任务
分布式计算常见的2种工作模式
-
分散->汇总 (MapReduce就是这种模式)
-
中心调度->步骤执行 (大数据体系的Spark、Flink等是这种模式)
2.MapReduce概述
-
学习目标
1.掌握MapReduce和Hadoop的关系
2.了解MapReduce的作用
什么是MapReduce
-
MapReduce是Hadoop中的分布式计算组件
-
MapReduce可以以分散->汇总(聚合)模式执行分布式计算任务
MapReduce的主要编程接口
-
map接口,主要提供“分散”功能,由服务器分布式处理数据
-
reduce接口,主要提供“汇总”功能,进行数据汇总统计得到结果
-
MapReduce可供Java、Python等语言开发计算程序
注:MapReduce尽管可以通过Java、Python等语言进行程序开发,但当下年代基本没人会写它的代码了,因为太过时了。 尽管MapReduce很老了,但现在仍旧活跃在一线,主要是Apache Hive框架非常火,而Hive底层就是使用的MapReduce。 所以对于MapReduce的代码开发,课程会简单扩展一下,但不会深入讲解,对MapReduce的底层原理会放在Hive之后,基于Hive做深入分析。
MapReduce的运行机制
-
将要执行的需求,分解为多个Map Task和Reduce Task
-
将Map Task 和 Reduce Task分配到对应的服务器去执行
3.YARN概述
-
学习目标
1.了解MapReduce和YARN的关系
2.了解为什么需要资源调度
3.了解YARN的作用
YARN是做什么的?
-
YARN是Hadoop的一个组件
-
用以做集群的资源(内存、CPU等)调度
为什么需要资源调度
-
将资源统一管控进行分配可以提高资源利用率
程序如何在YARN内运行
-
程序向YARN申请所需资源
-
YARN为程序分配所需资源供程序使用
MapReduce和YARN的关系
-
YARN用来调度资源给MapReduce分配和管理运行资源
-
所以,MapReduce需要YARN才能执行(普遍情况)
4.YARN架构
-
学习目标
1.掌握YARN的运行角色和角色之间的关系
2.理解使用容器做资源分配和隔离
核心架构
-
主(Master):ResourceManager
-
从(Slave):NodeManager
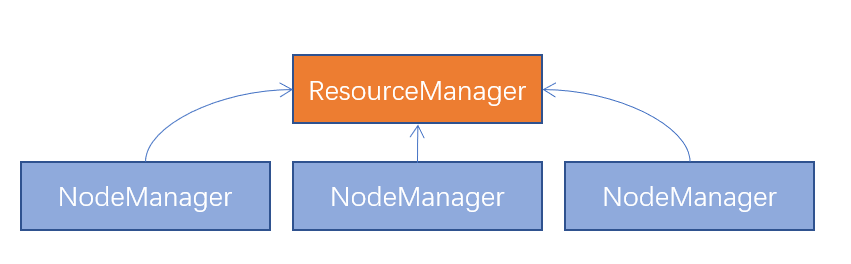
两个角色各自的功能是什么?
-
ResourceManager: 管理、统筹并分配整个集群的资源
-
NodeManager:管理、分配单个服务器的资源,即创建管理容器,由容器提供资源供程序使用
什么是YARN的容器?
-
容器(Container)是YARN的NodeManager在所属服务器上分配资源的手段
-
创建一个资源容器,即由NodeManager占用这部分资源
-
然后应用程序运行在NodeManager创建的这个容器内
-
应用程序无法突破容器的资源限制
ps:容器是虚拟化的相关机制
辅助架构
-
代理服务器(ProxyServer):Web Application Proxy Web应用程序代理
代理服务器,即Web应用代理是 YARN 的一部分。默认情况下,它将作为资源管理器(RM)的一部分运行,但是可以配置为在独立模式下运行。使用代理的原因是为了减少通过 YARN 进行基于网络的攻击的可能性。这是因为, YARN在运行时会提供一个WEB UI站点(同HDFS的WEB UI站点一样)可供用户在浏览器内查看YARN的运行信息,对外提供WEB 站点会有安全性问题, 而代理服务器的功能就是最大限度保障对WEB UI的访问是安全的。
代理服务器默认集成在了ResourceManager中,也可以将其分离出来单独启动。
-
历史服务器(JobHistoryServer): 应用程序历史信息记录服务
运行日志,产生在容器中,太零散了难以查看,统一收集到HDFS,由历史服务器托管为WEB UI供用户在浏览器统一查看。
5.MapReduce & YARN 的部署
-
学习目标
1.完成MapReduce框架的运行
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









