




 本文详细介绍了SparkSQL的运行流程,包括SparkRDD执行流程、自动优化(如Catalyst优化器的谓词下推和列值裁剪)、SparkOnHive原理及配置,以及分布式SQL执行引擎(如ThriftServer和JDBC连接)。
本文详细介绍了SparkSQL的运行流程,包括SparkRDD执行流程、自动优化(如Catalyst优化器的谓词下推和列值裁剪)、SparkOnHive原理及配置,以及分布式SQL执行引擎(如ThriftServer和JDBC连接)。
【大家好,我是爱干饭的猿,本文重点介绍、SparkSQL的运行流程、 SparkSQL的自动优化、Catalyst优化器、SparkSQL的执行流程、Spark On Hive原理配置、分布式SQL执行引擎概念、代码JDBC连接。
后续会继续分享其他重要知识点总结,如果喜欢这篇文章,点个赞👍,关注一下吧】
上一篇文章:《【SparkSQL】SparkSQL函数定义(重点:定义UDF函数、使用窗口函数)》
5. SparkSQL的运行流程
5.1 SparkRDD的执行流程回顾
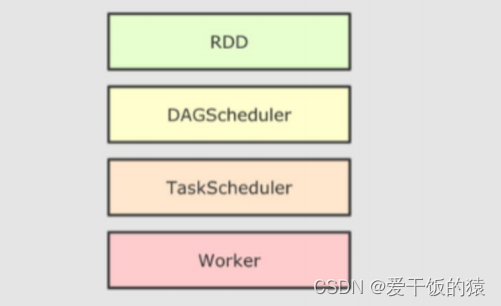
代码->DAG调度器逻辑任务->Task调度器任务分配和管理监控-> Worker干活
5.2 SparkSQL的自动优化
RDD的运行会完全按照开发者的代码执行, 如果开发者水平有限,RDD的执行效率也会受到影响。
而SparkSQL会对写完的代码,执行“自动优化”, 以提升代码运行效率,避免开发者水平影响到代码执行效率。
问:为什么SparkSQL可以自动优化而RDD不可以?
RDD:内含数据类型不限格式和结构
DataFrame:100% 是二维表结构,可以被针对SparkSQL的自动优化,依赖于:Catalyst优化器
5.3 Catalyst优化器
为了解决过多依赖Hive 的问题, SparkSQL使用了一个新的SQL优化器替代 Hive 中的优化器,这个优化器就是Catalyst,整个SparkSQL的架构大致如下:

- API层简单的说就是Spark会通过一些API接受SQL语句
- 收到SQL语句以后,将其交给Catalyst, Catalyst负责解析SQL,生成执行计划等
- Catalyst的输出应该是RDD的执行计划
- 最终交由集群运行
具体流程:

step1:解析SQL,并且生成AST(抽象语法树)
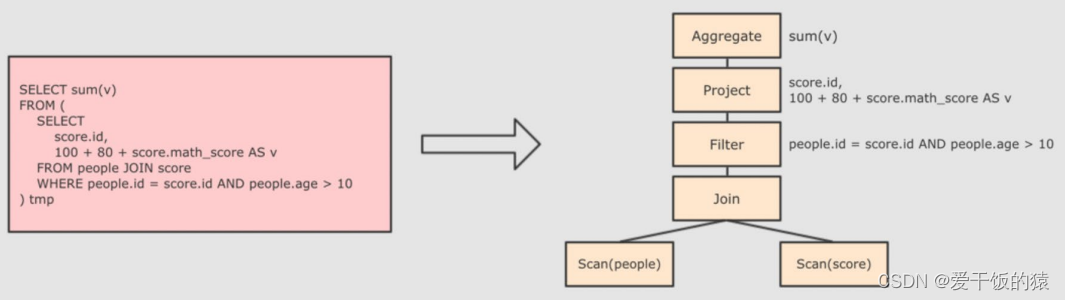
Step 2:在AST中加入元数据信息做这一步主要是为了一些优化。例如 col = col这样的条件,下图是一个简略图,便于理解
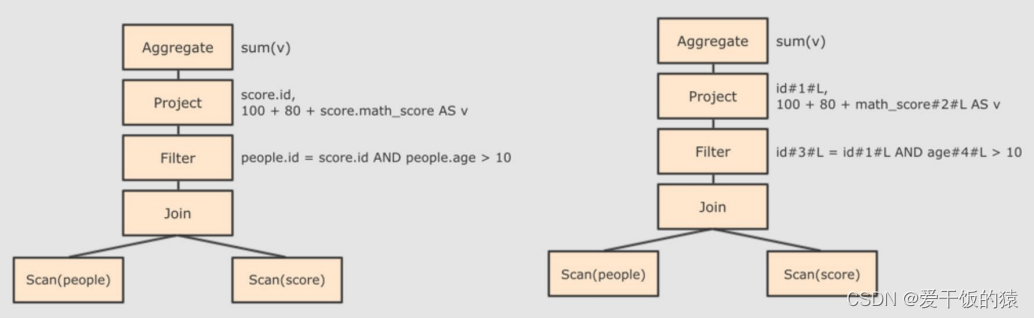
- score.id →id#1#L为score.id生成id为1,类型是Long
- score.math_score → math_score#2#L为score.math_score 生成id为2,类型为Long
- people.id → id#3#L为people.id生成 id为3,类型为Long
- people.age →age#4#L为people.age 生成 id为4,类型为Long
Step 3:对已经加入元数据的AST,输入优化器,进行优化,从两种常见的优化开始,简单介绍:
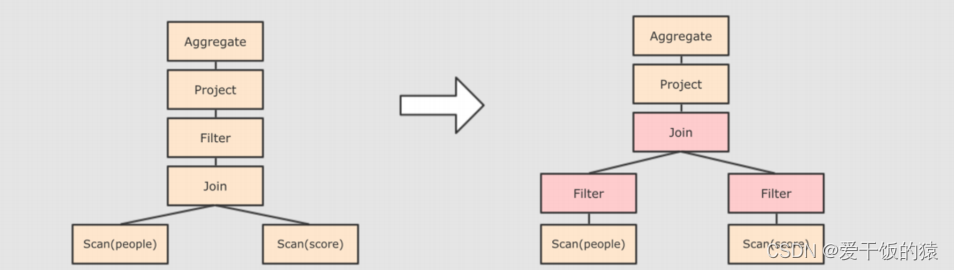
- 断言下推 Predicate Pushdown,将Filter这种可以减小数据集的操作下推,放在Scan 的位置,这样可以减少操作时候的数据量。断言下推后,会先过滤age,然后在JOIN,减少JOIN的数据量提高性能.
- 列值裁剪Column Pruning,在断言下推后执行裁剪,由于people表之上的操作只用到了 id 列,所以可以把其它列裁剪掉,这样可以减少处理的数据量,从而优化处理速度
Step
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3598
3598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











