






一、什么是Elastic Search
ElasticSearch(简称ES)是一个基于Apache Lucene构建的开源搜索引擎,它提供了一个分布式、可扩展的全文搜索和分析引擎。ElasticSearch被设计用来处理大量数据,并能够快速执行复杂的搜索查询。它广泛应用于日志分析、安全情报、全文搜索、业务分析等领域。
ElasticSearch使用倒排索引(Inverted Index)作为其核心数据结构,以实现快速的全文搜索功能。
二、什么是倒排索引
先来了解几个概念。
文档( Document ):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息。
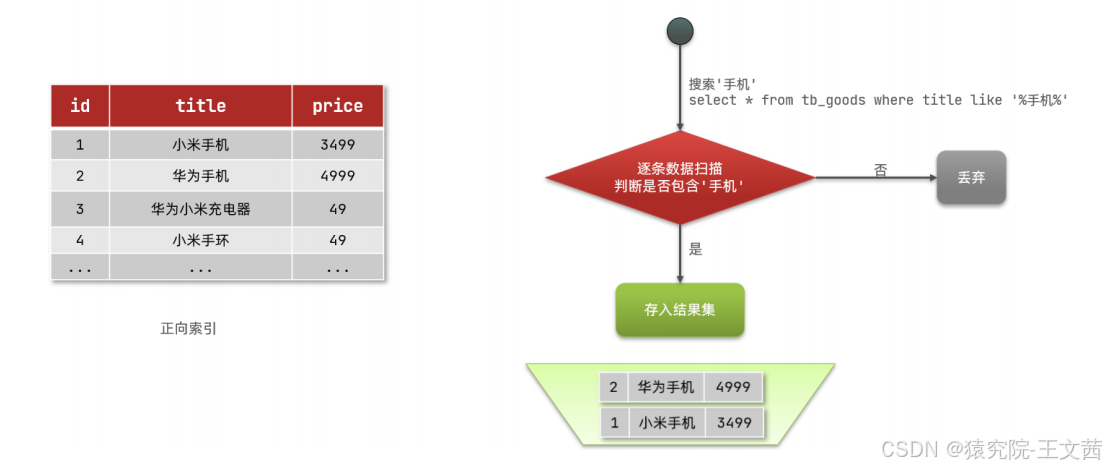
什么是正向索引?例如给下表(tb_goods)中的id创建索引:
- 用户搜索数据,条件是title符合 "%手机%"。
- 逐行获取数据,比如id为1的数据。
- 判断数据中的title是否符合用户搜索条件。
- 如果符合则放入结果集,不符合则丢弃。回到步骤1。
如下图所示:
- 将每一个文档的数据利用算法分词,得到一个个词条。
- 创建表,每行数据包括词条、词条所在文档id、位置等信息。
- 因为词条唯一性,可以给词条创建索引,例如hash表结构索引。
如下图所示:

- 用户输入条件 "华为手机" 进行搜索。
- 对用户输入内容分词,得到词条: 华为 、 手机 。
- 拿着词条在倒排索引中查找,可以得到包含词条的文档id:1、2、3。
- 拿着文档id到正向索引中查找具体文档。
如下图所示:
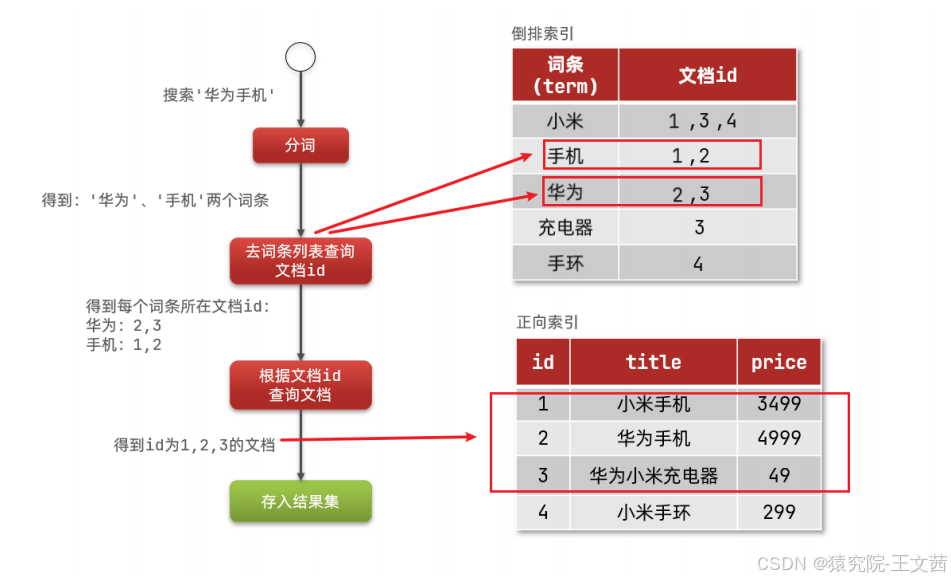
虽然要先查询倒排索引,再查询正向索引,但是无论是词条、还是文档id都建立了索引,查询速度非常快!无需全表扫描。
总结来说,倒排索引(Inverted Index)是一种特殊的索引结构,广泛应用于全文搜索引擎中。
它的核心思想是将文档集中的词汇与其出现的文档位置反向关联起来,即不是按照文档来索引词汇,而是按照词汇来索引包含它们的文档。
这样的设计使得搜索引擎能够快速地根据用户查询中的关键词找到包含这些关键词的文档集合。
三、为什么要创建倒排索引库
倒排索引之所以被创建,是因为它在全文检索中提供了极高的效率。
传统的正向索引(正排索引)是按照文档来组织词汇的,这意味着要查找一个词汇在哪些文档中出现,需要逐个检查每个文档。
而倒排索引则是按照词汇来组织文档的,它将每个词汇映射到包含该词汇的所有文档的列表,这样可以直接通过词汇快速找到相关文档,大大减少了搜索时间。
四、倒排索引库的操作
索引库就类似数据库,mapping映射就类似表的结构。 我们要向ES中存储数据,必须先创建“库”和“表”。
数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。
常见的mapping属性包括:
-
type:字段数据类型,常见的简单类型有:
-
字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)。
-
数值:long、integer、short、byte、double、float。
-
布尔:boolean。
-
日期:date。
-
对象:object。
-
-
index:是否创建索引,默认为true。
-
analyzer:使用哪种分词器。
-
properties:该字段的子字段。
下面是关于索引库的一些操作:
1.创建索引库和mapping映射
PUT /索引库名称
{
"mappings": {
"properties": {
// 定义文本字段,使用ik_smart分析器
"title": {
"type": "text",
"analyzer": "ik_smart"
},
// 定义一个不被索引的keyword字段
"id": {
"type": "keyword",
"index": "false"
},
// 定义一个嵌套对象,其中包含一个keyword类型的子字段
"author": {
"properties": {
"name": {
"type": "keyword"
}
}
}
// 其他字段定义可以继续添加
}
}
}例如:
{
"age":18,
"weight":60.5,
"isMarried":false,
"email":"12321@qq.com",
"name":{
"firstName":"王"
}
}2.删除索引库
DELETE /my_index五、文档操作
1.新增文档
PUT /索引库名称/_doc/文档ID
{
"字段名": "值",
"字段名2": "值2",
// 其他字段...
}例如:
PUT /my_index/_doc/1
{
"title": "示例文档",
"content": "这是一个示例文档的内容。",
"author": "张三"
}2.删除文档
DELETE /索引库名称/_doc/文档ID例如:
DELETE /my_index/_doc/13.修改文档
此处为增量修改,只修改指定id匹配的文档中的部分字段。
POST /索引库名称/_update/文档ID
{
"doc": {
"字段名": "新值",
// 其他需要修改的字段...
}
}例如:
POST /my_index/_update/1
{
"doc": {
"title": "修改后的文档标题",
"content": "这是修改后的文档内容。"
}
}4.查询文档
GET /索引库名称/_search
{
"query": {
"match": {
"字段名": "查询值"
}
}
}例如:
GET /my_index/_search
{
"query": {
"match": {
"title": "示例文档"
}
}
}注意:
-
文档ID在新增文档时需要指定,可以自定义,如果省略则由系统自动生成。
-
修改文档时使用_update端点,并在请求体中使用“doc”字段来指定需要修改的部分。
-
查询文档时,
match查询是最基本的全文搜索,可以根据需要替换为更复杂的查询结构。
当然,关于ES还有很多内容,后续有时间我们再讨论。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









