






一、理论基础
一)需求分析
单台数据服务器提供数据查询服务存在弊端:
1、单台数据库服务器不满足高负载用户访问需求。
2、单台服务器出现故障会影响用户访问。
3、无法单独对服务器读性能进行优化。
4、在同一台数据库上实现读写操作,存在S锁和X锁争用问题。为了保证写入数据成功,数据库会将要写入的表锁死,此时其他的写入或者读取都会受到严重影响。
共享锁【S锁】 又称读锁,若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。 排他锁【X锁】 又称写锁。若事务T对数据对象A加上X锁,事务T可以读A也可以修改A,其他事务不能再对A加任何锁,直到T释放A上的锁。这保证了其他事务在T释放A上的锁之前不能再读取和 修改A。
二)原理概述
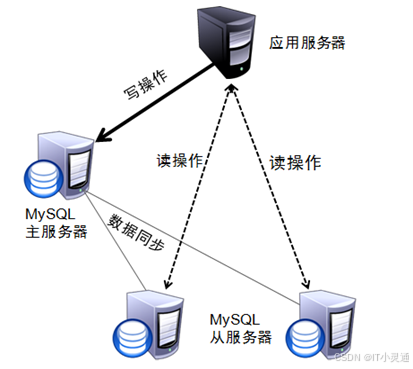
让主数据库服务器处理事务性查询,即对数库据修改的查询,而从数据库处理SELECT查询。数据库复制被用来把事务性查询导致的变更同步到集群中 的从数据库。
读写分离的目的:缓解主数据库服务器压力。
 三)MySQL主从复制实现
三)MySQL主从复制实现
1、原理及优点
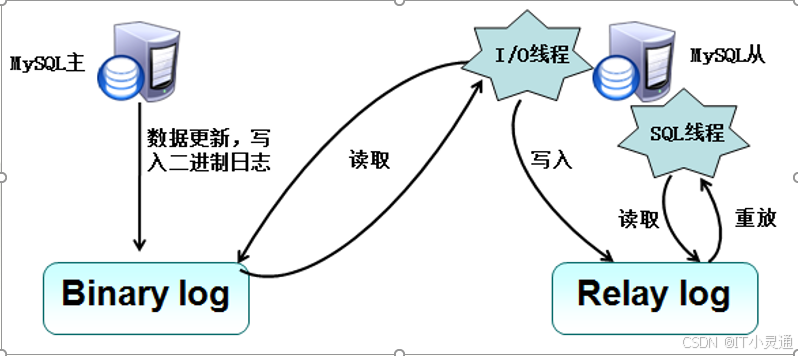
主MYSQL服务器在事务提交之前会将数据变更为事件记录在二进制的日志文件Binlog中。主库推送二进制日志文件Binlog中的事件到从库的中继日志Relay Log,之后从库根据中继日志Relay Log重做数据变更操作。使得双方内容实现一致。
MySQL通过 3个线程来完成主从库间的数据复制:其中Binlog Dump线程在主库上, I/O线程和SQL线程跑在从库上。当在从库上启动复制(START SLAVE)时,首先创建 I/O线程连接主库,主库随后创建Binlog Dump线程读取数据库事件并发送给 I/O线程,I/O线程获取到事件数据后更新到从库的中继日志Relay Log中去,之后从库上的SQL线程读取中继日志Relay Log中更新的数据库事件并应用,
MySQL支持一台主库同时向多台从库进行复制,从库同时也可以作为其他服务器的主库,实现链状的复制。
MySQL复制的优点主要包括以下3个方面:
-
如果主库出现问题,可以快速切换到从库提供服务;
-
可以在从库上执行查询操作,降低主库的访问压力;
-
可以在从库上执行备份,以避免备份期间影响主库的服务。
2、复制涉及的文件
1)二进制日志(Binlog)
二进制日志文件(Binlog)记录对数据库修改操作,包括:Create、Drop、Insert、Update、Delete等,但不包含select。
Binlog内容格式有三种:
-
Statement:基于SQL语句级别的Binlog,每条修改数据的SQL都会保存到Binlog里。
-
Row:基于行级别,记录每一行数据的变化,也就是将每行数据的变化都记录到Binlog里面,记录得非常详细,但是并不记录原始SQL;在复制的时候,并不会因为存储过程或触发器造成主从库数据不一致的问题,但是记录的日志量较Statement格式要大得多。
-
Mixed:混合Statement和Row模式,默认情况下采用Statement模式记录,某些情况下会切换到Row模式,例如SQL中包含与时间、用户相关的函数等。
2)中继日志(Relay Log)
中继日志文件Relay Log的文件格式、内容和二进制日志文件Binlog一样,从库上的SQL线程在执行完当前中继日志文件Relay Log中的事件之后,SQL线程会自动删除当前中继日志文件Relay Log。
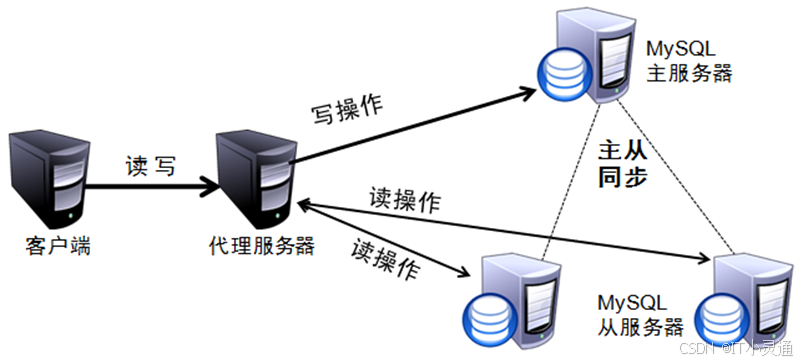
四)MySQL读写分离原理
客户端发送读写请求到代理服务器,代理服务器将写操作请求发送到MYSQL主服务器,将读操作发送到多个MYSQL从服务器。MYSQL主服务器完成写操作后,从服务器从主服务器处完成数据同步。各从服务器将响应用户请求的结果发给代理服务器,代理服务器再下发给客户机。
二、应用案例
一)时间同步服务配置 (跳过)
1、安装服务
由于在真实环境中数据库同步时,要求服务器时间必须一致,所以MYSQL主服务器上安装 NTP服务:
yum -y install ntp #服务器端
yum -y install ntpdate #客户端
安装后守护程序为:ntpd
2、编辑NTP配置文件:/etc/ntp.conf 配置文件内容解析
将本地服务器作为时钟源,并且不与外部服务器同步的配置如下:
restrict 192.168.3.0 mask 255.255.255.0 nomodify notrap #假设服务器都在192.168.3.0网段 #server 0.centos.pool.ntp.org iburst #原文中被注释掉内容 #server 1.centos.pool.ntp.org iburst #原文中被注释掉内容 #server 2.centos.pool.ntp.org iburst #原文中被注释掉内容 #server 3.centos.pool.ntp.org iburst #原文中被注释掉内容 server 127.127.1.0 fudge 127.127.1.0 stratum 8 #在时间同步中,当前服务器们于第8层。
3)重启服务
systemctl restart ntpd
netstat -anpu |grep 123 #NTP服务使用端口号UPD:123
3、另外两台服务器时间同步配置:
mysql1从服务器:
date -s "2020-07-09" #将本地系统
ntpdate 192.168.3.55(时钟服务器的IP地址。) #查看时间是否更新成与服务NTP服务器一致的时间。
mysql2从服务器:
date -s "2020-07-09" #将本地系统
ntpdate 192.168.1.101(时钟服务器的IP地址。)
配置文件内容解析
1)restrict default nomodify notrap noquery 。
ignore : 拒绝所有类型的ntp连接 nomodify : 客户端不能使用ntpc与ntpq两支程式来修改服务器的时间参数 noquery : 客户端不能使用ntpq、ntpc等指令来查询服务器时间,等于不提供ntp的网络校时 notrap : 不提供trap这个远程时间登录的功能 notrust : 拒绝没有认证的客户端 nopeer : 不与其他同一层的ntp服务器进行时间同步 restrict 192.168.3.0 mask 255.255.255.0 nomodify notrap #授权192.168.3.0网段所有机器可以从这台机器上查询和同步时间。
文件尾部:
2)#server 0.centos.pool.ntp.org iburst
#作为当前服务端同步的基准NTP服务器。 server 127.127.1.0 #把本机的时间做为时钟同步的时钟源。其它系统的时间都与本主机保持 一致。 fudge 127.127.1.0 stratum 8 #时间服务器的层次。设为0则为顶级,如果要向别的NTP服务器更新时间,请不要把它设为0
ntpdate错误解析:
1、no server suitable for synchronization found,时钟服务器刚启动不久,正在与其它服务器完成时间同步,这个时间大约5-8分钟。
2、the NTP socket is in use,exiting,本地开启了NTPD服务,可以使用netstat -anpu|grep 123来查看进程PID,然后使用kill 命令杀死进程(也可以用systemctl stop ntpd关闭)。再执行ntpdate。
二)MYSQL主从复制案例
环境准备:在主服务器上安装MYSQL,然后从主服务器克隆两台从服务器。由于克隆出来的服务器MYSQL的UUID值相同,为了避免Slave_IO_Running因UUID值相同而无法复制,在启动克隆的服务器后,进行如下操作:
1)生成新的UUID值: mysql>select uuid(); 2) 复制UUID值,编辑存储数据库文件目录中的auto.cnf文件 vim /data/mysql/auto.cnf 将原UUID替换成复制过来的UUID。 3)重启MYSQL服务 service mysql restart
1、master服务器配置
rpm安装前,删除其他旧的包
yum -y remove boost-* mysql mariadb-* rm -rf /var/lib/mysql/*
yum install mysql-community-common-5.7.33-1.el7.x86_64.rpm
yum install -y mysql-community-libs-5.7.33-1.el7.x86_64.rpm
yum install -y mysql-community-client-5.7.33-1.el7.x86_64.rpm
yum install -y mysql-community-server-5.7.33-1.el7.x86_64.rpm
1)编辑配置文件
vim /etc/my.cnf
log-bin=mysql-bin-master #指定使用二进制文件,并指定文件名,等号后的名称可以随意定义,该名称会出现在show master status命令结果中。
server-id=1 #本机数据库 ID 标示,三台服务器的server-id不能相同
log-slave-updates=true #允许从服务器更新
其它参考设置: binlog-ignore-db=mysql #不复制的数据库 binlog-ignore-db=information_schema #不复制的数据库 bin-log-do-db=ceshi #需要复制的数据库名称 binlog_format=STATEMENT #日志格式
bin-log日志格式: STATEMENT:默认格式,采用此种格式复制内容,如果语句中有now()时间,会造成主从主机上时间字段值不一致。 ROW:行格式,即按主服务器数据库内容变化的行逐行复制,没有SQL语句执行起来效率高,特别是主服务器进行全表内容更新时,从服务器更新的数据量很大。 MIXED:混合模式,不影响一致内容一致的时候,用STATEMENT模式,影响的时候用ROW模式。缺点无法识别@@host name
2)重启MySQL服务:
systemctl restart mysqld
获取mysql的root密码
cat /var/log/mysqld.log | grep password
3)创建授权复制账户:
-
登录mysql:
mysql -uroot -p
-
创建同步数据库
create database ceshi;
-
新建myslave用户(密码:1qaz!QAZ),它可以登录192.168.0.0网段的主机,对当前服务器任何数据库的任何表进行复制操作。
grant replication slave on * . * to 'myslave'@'192.168.%' identified by '1qaz!QAZ';
-
刷新权限表,使创建的用户myslave 权限生效。
flush privileges;
4)查看主服务器二进制日志文件的状态信息。
show master status; #执行此句后不要在 master上做任何操作,特别是写操作。下表是执行结果示例。
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
|---|---|---|---|---|
| mysql-bin-master.000001 | 337 |
#主机将从master-bin.000001这个二进制文件的337行这个位置开始同步。
2、从MySQL服务器配置
1)修改配置文件:
vim /etc/my.cnf
server-id=2 #修改server-id,网络中各服务器server-id必须唯一。
2)重启服务
systemctl restart mysqld
获取mysql的root密码
cat /var/log/mysqld.log | grep password
3)登录服务,设置主服务器复制参数项
mysql -uroot -p
stop slave; #停止 slave change master to master_host='192.168.30.12',master_user='myslave',master_password='1qaz!QAZ'; start slave; #启动 slave #启用主从同步功能(启动I/O 线程和SQL线程),同时启动I/O 线程和SQL线程( I/O线程从主库读取bin log,并存储到relay log中继日志文件中。SQL线程读取中继日志,解析后,在从库重放。)
4)查看线程状态
mysql>show slave status \G;
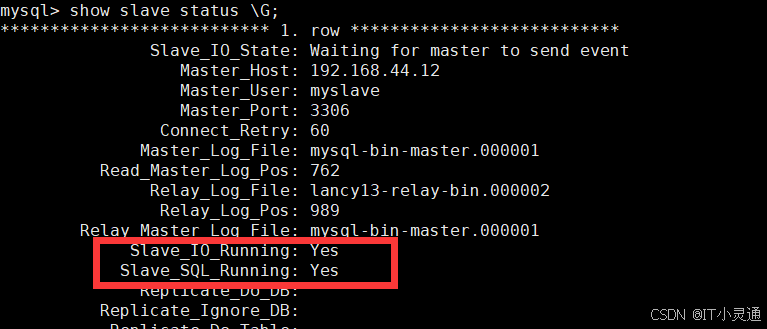
Slave_IO_Running :一个负责与主机的 IO 通信 Slave_SQL_Running:负责自己的 slave mysql 进程 两个为 YES 就成功了!
5)再到主服务器上查看状态:
show processlist \G;

3、主从复制验证
在master服务器上做如下操作:
use ceshi;
CREATE TABLE ceshi (ceshi int);
在slave服务器上查看ceshi数据库中是否有ceshi表。
use ceshi;
show tables;
注意:如果以前从机配置过主从复制,再配置的时候可能会报错,解决办法: 1、stop slave; #停止主从复制 2、reset master; #重置master信息。 3、change master to master_host...#配置主从复制信息
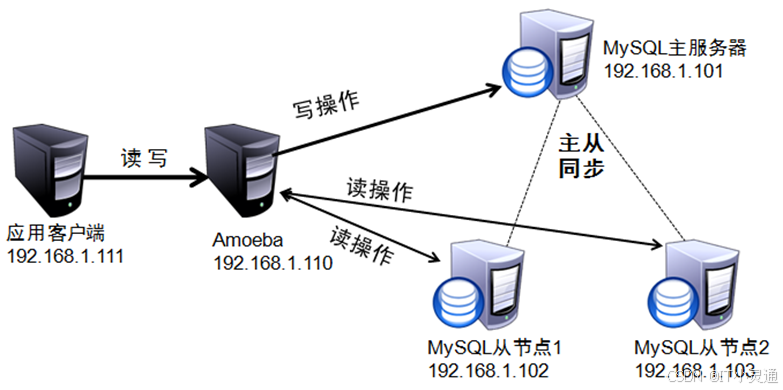
三)读写分离案例
环境说明
此实验在实验二基础上完成,环境依旧参照实验二的网络环境。实验需要准备一个名为abc的数据库,数据库中有一个ceshi的表,该表有一个字段:ceshi。
配置步骤
1、mycat服务器配置(192.168.1.110)
1)安装jdk8。
tar xf jdk-8u191-linux-x64.tar.gz -C /usr/local/
vim /etc/profile.d/java.sh export JAVA_HOME=/usr/local/jdk1.8.0_191 export PATH=$PATH:$JAVA_HOME/bin
2)解压mycat。
tar xf Mycat-server-1.6.7.4-release-20200105164103-linux.tar.gz -C /usr/local/
| 目录 | 说明 |
|---|---|
| bin | bin 程序目录,除了提供封装成服务的版本之外,也提供了 nowrap 的shell 脚本命令 |
| conf | conf 目录下存放配置文件 server.xml 是 Mycat 服务器参数调整和用户授权的配置文件 schema.xml 是逻辑库定义和表以及分片定义的配置文件 rule.xml 是分片规则的配置文件 |
| lib | 存放 mycat 依赖的一些 jar 文件 |
| logs | 日志存放在 logs/mycat.log 中,每天一个文件,日志的配置是在 conf/log4j.xml 中 |
| version.txt | 版本文件 |
注意:Linux 下部署安装 MySQL,默认不忽略表名大小写,需要手动到/etc/my.cnf 下配置 lower_case_table_names=1 使 Linux 环境下 MySQL 忽略表名大小写,否则使用 MyCAT 的时候会提示找不到 表的错误!
3)服务启动与启动设置
MyCAT 在 Linux 中部署启动时,首先需要在 Linux 系统的环境变量中配置 MYCAT_HOME,操作方式如下: 1) 在系统环境变量文件中增加
vim /etc/profile.d/mycat.sh export MYCAT_HOME=/usr/local/mycat export PATH=$PATH:$MYCAT_HOME/bin
2) 执行 source /etc/profile 命令,使环境变量生效。
3) 设置登录逻辑库的默认用户账户:
cd /usr/local/mycat/conf/
vim server.xml 最后部分有两个<user> <!--以下设置为应用访问帐号权限 --> <user name="root" defaultAccount="true"> #设置访问逻辑库的默认账户 <property name="password">123456</property> #设置访问逻辑库的默认账户的密码 <property name="schemas">TESTDB</property> #访问的架构 <property name="defaultSchema">TESTDB</property> #访问的默认架构 </user> <!--以下设置为应用只读帐号权限 --> <user name="admin"> <property name="password">123456</property> <property name="schemas">TESTDB</property> <property name="readOnly">true</property> # <property name="defaultSchema">TESTDB</property> </user>
4)修改schema.xml文件内容:
mv schema.xml schema.xml.bak
所有服务器mysql创建连接用户mycat执行:
GRANT ALL PRIVILEGES ON . TO 'mycat'@"%" IDENTIFIED BY "1qaz!QAZ";
flush privileges;
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
</schema>
<dataNode name="dn1" dataHost="localhost1" database="ceshi" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="2"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="master" url="192.168.3.55:3306" user="mycat" password="1qaz!QAZ">
<readHost host="slave" url="192.168.3.57:3306" user="mycat" password="1qaz!QAZ" />
</writeHost>
</dataHost>
</mycat:schema>
-----------------------------------------------------------------------------------------
标签属性说明:
1.<schema>属性:
1)checkSQLschema="false"
当该值设置为 true 时,如果我们执行语句**select * from TESTDB.travelrecord;**则 MyCat 会把语句修改为**select * from travelrecord;**。即把表示 schema 的字符去掉,避免发送到后端数据库执行时报**(ERROR1146 (42S02): Table ‘testdb.travelrecord’ doesn’t exist)。**
不过,即使设置该值为 true ,如果语句所带的是并非是 schema 指定的名字,例如:**select * from
db1.travelrecord;** 那么 MyCat 并不会删除 db1 这个字段,如果没有定义该库的话则会报错,所以在提供 SQL语句的最好是不带这个字段。
2)dataNode="dn1" ,设置schema默认的数据节点。
2.<dataHost>标签属性:
1)balance 属性:
负载均衡类型,目前的取值有 3 种:
balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上。
balance="1",全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载均衡。
balance="2",所有读操作都随机的在 writeHost、readhost 上分发。
balance="3",所有读请求随机的分发到 writerHost 对应的 readhost 执行,writerHost 不负担读压力,注意 balance=3 只在 1.4 及其以后版本有,1.3 没有。
2)writeType 属性:
负载均衡类型,目前的取值有 3 种:
writeType="0", 所有写操作发送到配置的第一个 writeHost,第一个挂了切到还生存的第二个 writeHost,重新启动后已切换后的为准,切换记录在配置文件中:dnindex.properties .
writeType="1",所有写操作都随机的发送到配置的 writeHost,1.5 以后废弃不推荐。
3)switchType 属性。
-1 表示不自动切换。
1 默认值,自动切换。
2 基于 MySQL 主从同步的状态决定是否切换。
4)dbType 属性
指定后端连接的数据库类型,目前支持二进制的 mysql 协议,还有其他使用 JDBC 连接的数据库。
5)dbDriver 属性
指定连接后端数据库使用的 Driver,目前可选的值有 native 和 JDBC。
5)配置并启用mycat
vim wrapper.conf
最后添加以下行
wrapper.startup.timeout=300
启动
mycat start
cat /usr/local/mycat/logs/wrapper.log
MyCAT Server startup successfully. see logs in logs/mycat.log
6)测试
a. 客户端连接mycat数据库测试:
mysql -h192.168.1.110 -uadmin -p123456 -P8066
mysql>show databases;
mysql>use TESTDB;
mysql>show tables; #查看数据库中的表,检查是否有stu表。
mysql>insert into stu values(1,'zhangsan');
mysql>select * from stu;
登录查主从MYSQL查询stu表的内容。
b.负责均衡测试:
-
schema.xml文件,将balance值修改为2。
insert into stu values(2,‘admin'); #只在从服务器上执行此命令。
select * from stu; #在客户端执行此命令,多刷新几次,看表中内容的变化。
-
schema.xml文件,将balance值修改为1,在客户机上连接mycat,查询stu表,多查询几次,内容不变,并且显示的是从SQL服务器上的内容。
use TESTDB;
select * from ceshi;
Mycat理论基础
Mycat 是数据库中间件,就是介于数据库与应用之间,进行数据处理与交互的中间服务。它使用 JAVA 语言进行编写开发,使用前需要先安装 JAVA 运行环境(JRE),由于 MyCAT 中使用了JDK7 中的一些特性,所以要求必须在 JDK7 以上的版本上运行。
一、基本概念:
逻辑库(schema):数据库中间件可以被看做是一个或多个数据库集群构成的逻辑库。在云计算时代,数据库中间件可以以多租户的形式给一个或多个应用提供服务,每个应用访问的可能是一个 独立或者是共享的物理库,常见的如阿里云数据库服务器 RDS。
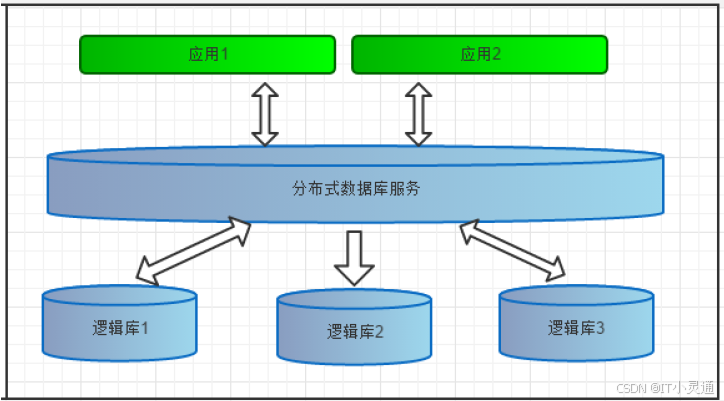
逻辑表(table):
分布式数据库中,对应用来说,读写数据的表就是逻辑表。逻辑表,可以是数据切分后,分布在一个或多个分片库中,也可以不做数据切分,不分片,只有一个表构成。
分片表:
是指那些原有的很大数据的表,需要切分到多个数据库的表,这样,每个分片都有一部分数据,所有分片构成了完整的数据。
分片节点(dataNode):
数据切分后,一个大表被分到不同的分片数据库上面,每个表分片所在的数据库就是分片节点(dataNode)。
节点主机(dataHost):
一个或多个分片节点(dataNode)所在的机器就是节点主机(dataHost)。
分片规则(rule):
一个大表被分成若干个分片表,就需要一定的规则,这样按照某种业务规则把数据分到 某个分片的规则就是分片规则。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









