







 本文深入探讨了K近邻(KNN)分类算法,包括分类问题的一般描述,KNN算法的描述,KNN的三个基本要素:距离向量、超参数K值选择和决策规则,以及KNN算法的kd树实现。通过kd树的构建和搜索方法,阐述了如何高效地应用KNN进行分类。
本文深入探讨了K近邻(KNN)分类算法,包括分类问题的一般描述,KNN算法的描述,KNN的三个基本要素:距离向量、超参数K值选择和决策规则,以及KNN算法的kd树实现。通过kd树的构建和搜索方法,阐述了如何高效地应用KNN进行分类。
目录
3.2.2 基于m-fold cross validation的K值选择
前言
有很多新手刚刚接触大数据与人工智能方向学习,如果不知道怎么着手的,跟我一起慢慢进步叭~
提示:以下是本篇文章正文内容,下面案例可供参考
关键词:分类问题的定义,KNN分类模型,距离度量,超参数,交叉验证,性能评价
一、分类问题的一般描述

基于上述样本集,设计分类模型 ---- 分类模型的监督式学习,对特征空间的任意观测x进行类别决策 ----- 模型的使用。
二、K近邻分类算法的描述
K近邻算法没有训练过程,懒惰算法。
输入:①训练样本集D,
②观测样本x
输出:观测样本x所属的类别y
STEP0.训练集D的输入部分预处理,并记录预处理的使用参数
STEP1.指定距离向量,并选择K值
STEP2.训练集D内找到预处理的样本x的前k个近邻,记为![]()
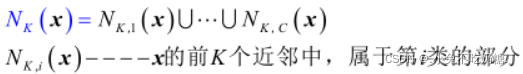
STEP3.结合指定的分类规则,对x的类别y进行预测: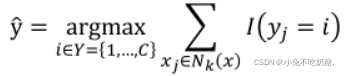
其中,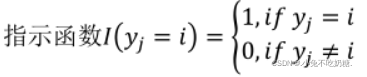
在给定训练集的前提下,样本是否预处理、不同距离向量方式、不同K值、不同的决策规则,均会导致不同的分类结果。
三、K近邻分类的三个基本要素
K近邻分类的三个基本要素:距离向量,超参数K值,决策规则
3.1 距离向量
3.1.1 典型的距离向量方式

3.1.2 用于距离向量的样本的标准化预处理
方式一:0均值、1方差的标准化预处理(推荐使用)
首先,利用训练集估计
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 893
893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









