







 博客详细探讨了ArcGIS工具箱中Python2.7脚本处理中文字符串时出现的编码问题。ArcGIS似乎在编码过程中额外进行了UTF-8编码,导致与IDLE中运行结果不同。解决方案是将编码声明设为GBK,并在中文字符串前加u,确保在ArcGIS和IDLE中都能正常运行。同时,博客提到了外部输入和路径处理的注意事项。
博客详细探讨了ArcGIS工具箱中Python2.7脚本处理中文字符串时出现的编码问题。ArcGIS似乎在编码过程中额外进行了UTF-8编码,导致与IDLE中运行结果不同。解决方案是将编码声明设为GBK,并在中文字符串前加u,确保在ArcGIS和IDLE中都能正常运行。同时,博客提到了外部输入和路径处理的注意事项。
python2.7的脚本在python自带的idle中运行良好,但融合到arcgis工具箱中就是会乱码,就是会报错。
假如说python2.7处理中文需要考虑代码转换,有难度。那么,python2.7在制作arcgis工具箱脚本时,处理中文不仅仅要考虑代码转换,还要考虑arcgis处理代码的特殊性。
今天做个测试,看看同样的脚本在“python的idle中”和“在arcgis工具箱中调用”到底有什么区别。
arcgis10.7 , 自带python2.7
测试1:编码声明为utf-8
idle运行,2个汉字6个字节,是utf-8,没毛病。
# -*- coding: utf-8 -*-
msg = '中文'
print repr(msg)
print msg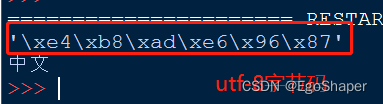
工具箱中调用,变成了3个汉字9个字节,也是utf-8,可是怎么变身了呢?
# -*- coding: utf-8 -*-
import arcpy
msg = '中文'
arcpy.AddMessage(repr(msg))
arcpy.AddMessage(msg)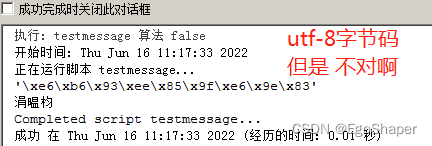
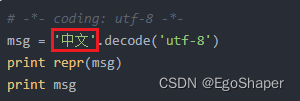
测试2,编码声明为utf-8,字符串转码成unicode
idle中,2个汉字对应2个字节,是Unicode没毛病
# -*- coding: utf-8 -*-
msg = '中文'.decode('utf-8')
print repr(msg)
print msg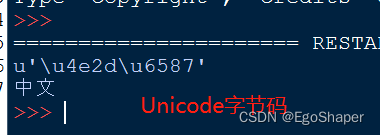
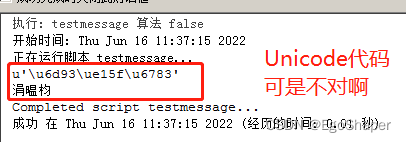
arcgis工具箱中调用,又变身了!!
# -*- coding: utf-8 -*-
import arcpy
msg = '中文'.decode('utf-8')
arcpy.AddMessage(repr(msg))
arcpy.AddMessage(msg)
测试3,编码声明为gbk
idle,一个中文对应2个字节,是gbk编码,正常
# -*- coding: gbk -*-
msg = '中文'
print repr(msg)
print msg
arcgis工具箱调用脚本,没有乱码,但编码居然是utf-8,这??
# -*- coding: gbk -*-
import arcpy
msg = '中文'
arcpy.AddMessage(repr(msg))
arcpy.AddMessage(msg)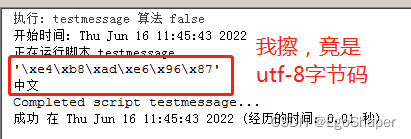
测试4,编码声明为gbk, 字符串转码成Unicode
idle,一切正常
# -*- coding: gbk -*-
msg = '中文'.decode('gbk')
print repr(msg)
print msg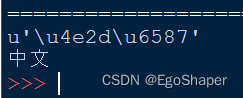
arcgis工具箱调用脚本,我擦,居然报错!!
# -*- coding: gbk -*-
import arcpy
msg = '中文'.decode('gbk')
arcpy.AddMessage(repr(msg))
arcpy.AddMessage(msg)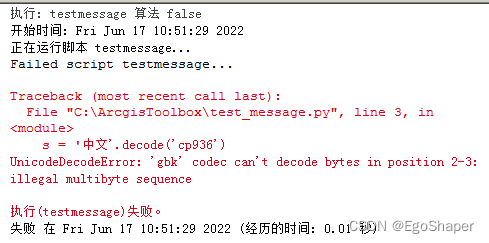
测试5,编码声明为gbk, 字符串转码成Unicode,但解码用utf-8
idle,意料之中的报错了
# -*- coding: gbk -*-
msg = '中文'.decode('utf-8')
print repr(msg)
print msg 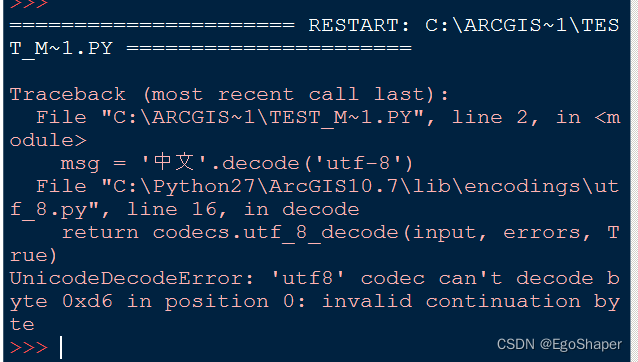
arcgis工具箱调用脚本,我擦,居然不报错!!
# -*- coding: gbk -*-
import arcpy
msg = '中文'.decode('utf-8')
arcpy.AddMessage(repr(msg))
arcpy.AddMessage(msg)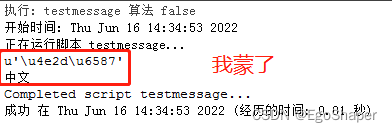
测试6:修改系统编码后
我尝试修改了系统编码为utf-8,且设置系统默认编码也为utf-8,重复以上测试,结果不变。
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import arcpy
msg = '中文'
arcpy.AddMessage(repr(msg))
arcpy.AddMessage(msg) 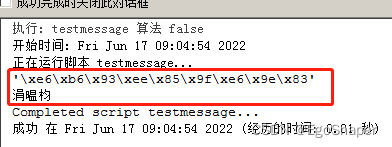
分析:
arcgis在处理脚本的中文字符串时,应该是多加了一步编码encode('utf-8')。以测试1的代码为例。
# -*- coding: utf-8 -*-
msg = '中文'在idle中,会按utf-8(编码声明)对‘中文’这个字符串进行编码。就是'\xe4\xb8\xad\xe6\x96\x87'。
而在arcgis调用时,会先按utf-8(编码声明)对‘中文’这个字符串进行编码。就是'\xe4\xb8\xad\xe6\x96\x87'。然后在按encode('utf-8')进行编码(这是arcgis独有的)。但对非Unicode字符串进行编码时,会先解码成Unicode,然后再进行编码,通常情况下会默认按系统编码进行解码,但arcgis并不参考系统编码,一律按gbk强行解码,因gbk两个字节对应一个汉字,就解码成了3个字节的Unicode(u'\u6d93\ue15f\u6783'
),然后编码成utf-8时,就成了9个字节'\xe6\xb6\x93\xee\x85\x9f\xe6\x9e\x83'。
再以测试3代码为例,即编码声明为gbk
# -*- coding: gbk -*-
msg = '中文'在idle中,会按gbk(编码声明)对‘中文’这个字符串进行编码。就是'\xd6\xd0\xce\xc4'。
而在arcgis调用时,会先按gbk(编码声明)对‘中文’这个字符串进行编码。就是'\xd6\xd0\xce\xc4'。然后再按encode('utf-8')进行编码(这是arcgis独有的)。但对非Unicode字符串进行编码时,会先解码成Unicode,然后再进行编码,通常情况下会默认按系统编码进行解码,但arcgis并不参考系统编码,一律按gbk强行解码,因gbk两个字节对应一个汉字,就解码成了2个字节的Unicode(u'\u4e2d\u6587'
),然后编码成utf-8时,就成了6个字节'\xe4\xb8\xad\xe6\x96\x87'。
测试2解释
代码中的‘中文’字符串后面的.decode('utf-8')执行顺序在encode('utf-8')之后才进行(这是arcgis独有的)。即
1.‘中文’-'\xe4\xb8\xad\xe6\x96\x87'-u'\u6d93\ue15f\u6783'-'\xe6\xb6\x93\xee\x85\x9f\xe6\x9e\x83'
2.至此才开始执行‘中文’字符串后面的.decode('utf-8')。所以结果是u'\u6d93\ue15f\u6783'
应对方案:
代码中的编码声明头文件一定要是gbk,而且所有中文前面添加u,即采用unicode万国字节码。
如此,无论在arcgis中运行,还是在pycharm中调试都可以顺利不报错。
重复一遍,编码声明一定要是gbk,而且所有中文前面添加u,二者缺一不可。
例如:以下代码无论在哪都能顺利运行,而且编码一致不会乱码和报错:
# -*- coding: gbk -*-
import arcpy
s = u'中文'
print repr(s)
print s
arcpy.AddMessage(repr(s))
arcpy.AddMessage(s)
g = s.encode('gbk')
print repr(g)
print g
arcpy.AddMessage(repr(g))
arcpy.AddMessage(g)
u8 = s.encode('utf-8')
print repr(u8)
print u8
arcpy.AddMessage(repr(u8))
arcpy.AddMessage(u8)
u = g.decode('gbk')
print repr(u)
print u
arcpy.AddMessage(repr(u))
arcpy.AddMessage(u)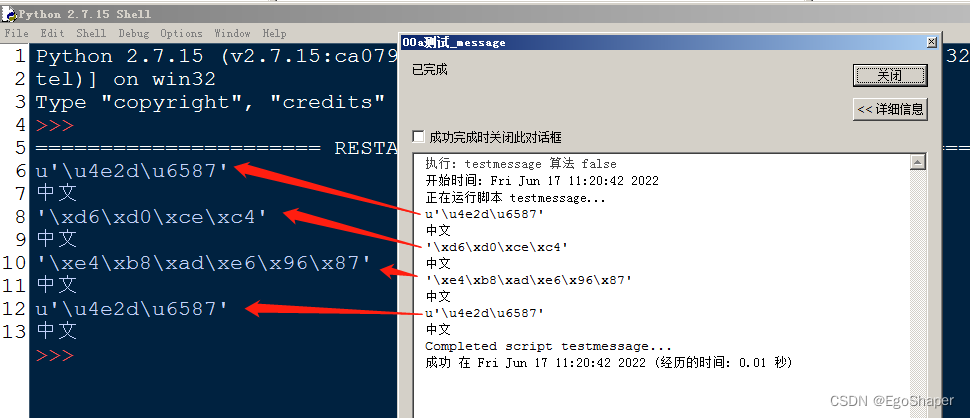
另外,
1.从外部调入中文字符串也要注意立即解码成万国码。
2.带中文的路径不要用r,用u,例如:
错误做法:path = r'C:\ArcgisToolbox\中国.xls'
正确做法:path = u'C:\\ArcgisToolbox\\中国.xls'
如果,小伙伴有强迫症,非要用utf-8。那么也行,别用中文。因为这样的话加u没有用。arcgis是优先于u进行解码,不信请看
# -*- coding: utf-8 -*-
import arcpy
s = u'中文'
arcpy.AddMessage(repr(s))
arcpy.AddMessage(s)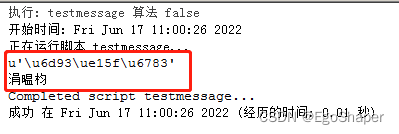
具体转码过程是这样
1.‘中文’-'\xe4\xb8\xad\xe6\x96\x87'-u'\u6d93\ue15f\u6783'-'\xe6\xb6\x93\xee\x85\x9f\xe6\x9e\x83'(加粗部分是arcgis独有的即'\xe4\xb8\xad\xe6\x96\x87'.encode(‘utf-8’))
2.至此才开始执行‘中文’字符串前面的u。所以结果是u'\u6d93\ue15f\u6783'

















 510
510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









