






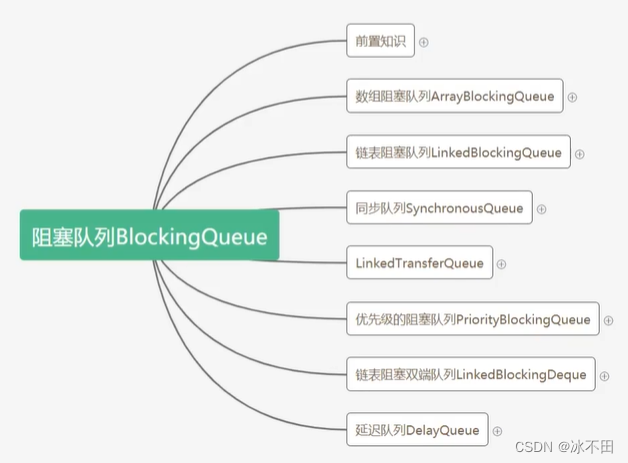
目录
数据结构

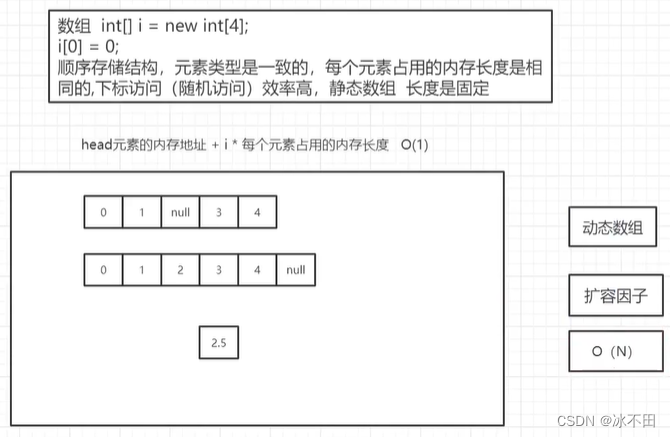
数组
内存地址:head元素的内存地址+i*每个元素占用的内存长度
时间复杂度(查询):O(1)
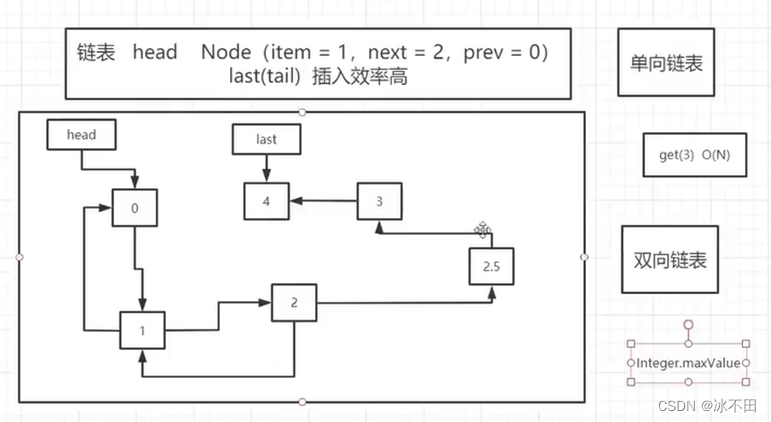
链表
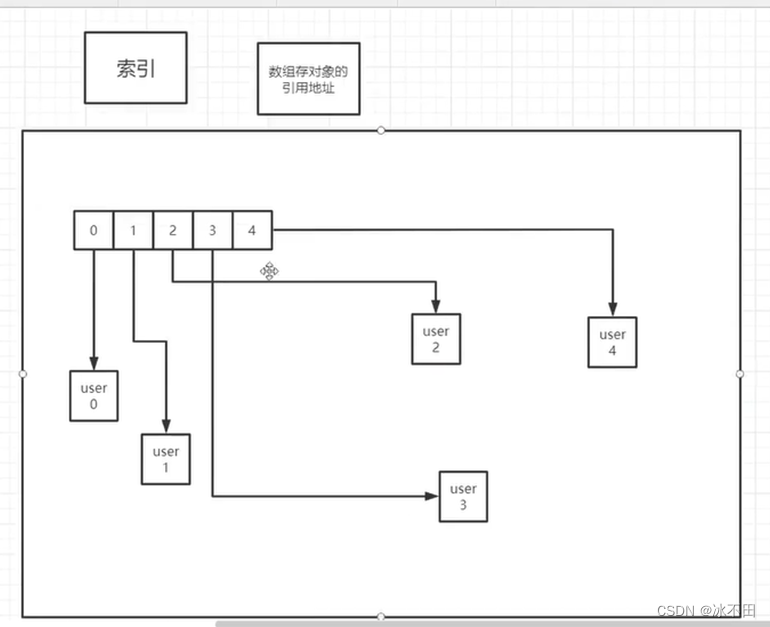
索引
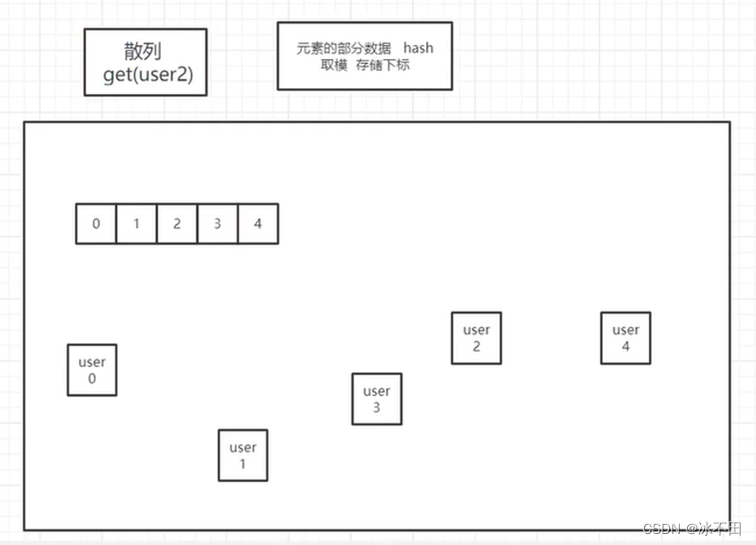
散列
锁和阻塞
悲观锁
synchronized 串行 内部维护一个队列
自动 加锁、释放锁
Object wait( ) notify( )(随机唤醒)
ReentrantLock ReentrantLock lock = new ReentrantLock( );
Condation condation = lock.newCondation( );
lock.lock( );
condation.await( ) (或者)condation.signal( )(唤醒的一定是当前对象的)
lock.unlock( );
乐观锁(无锁机制)
CAS+自旋 Compare and Set :比较,然后设置 原子性
Unsafe 操作系统提供的指令
只有一个线程CAS能执行成功
LockSupport.park();//阻塞线程
LockSupport.unpark(指定线程);//唤醒线程


ArrayList
(常量的存在主要是为了节省内存空间)
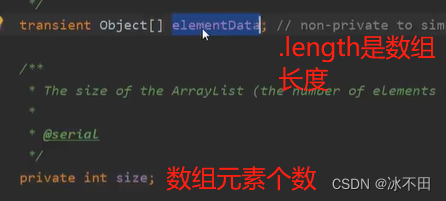
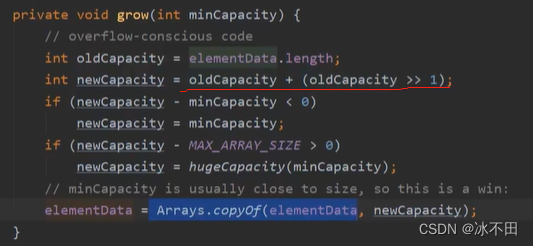
使用无参构造器,初次添加元素时容量默认初始化为10,不够时按1.5倍扩容
有参构造器指定了初始信息,不够时按1.5倍扩容
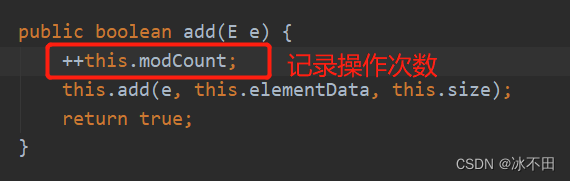
fail-fast:快速失败
modCount:使用迭代器遍历当前集合时,如果有其他线程对该集合做了修改,就不做遍历操作了
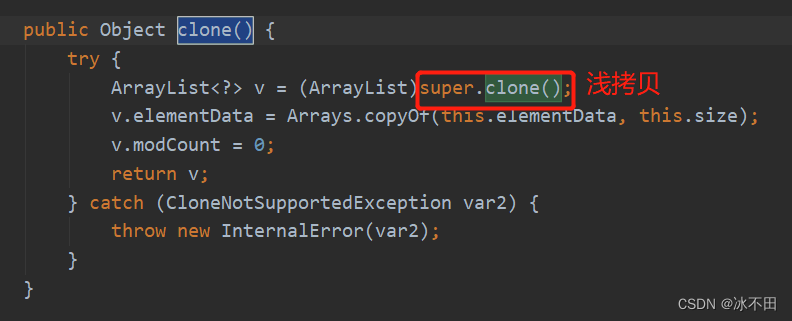
拷贝
不管深拷贝还是浅拷贝,拷贝的都是栈中的内容
基本数据类型互相独立,引用数据类型互相不独立
重写了序列化方法:(因为elementData里面有null,占空间也不需要,transient)
根据size序列化,size个数才是真正需要序列化的数据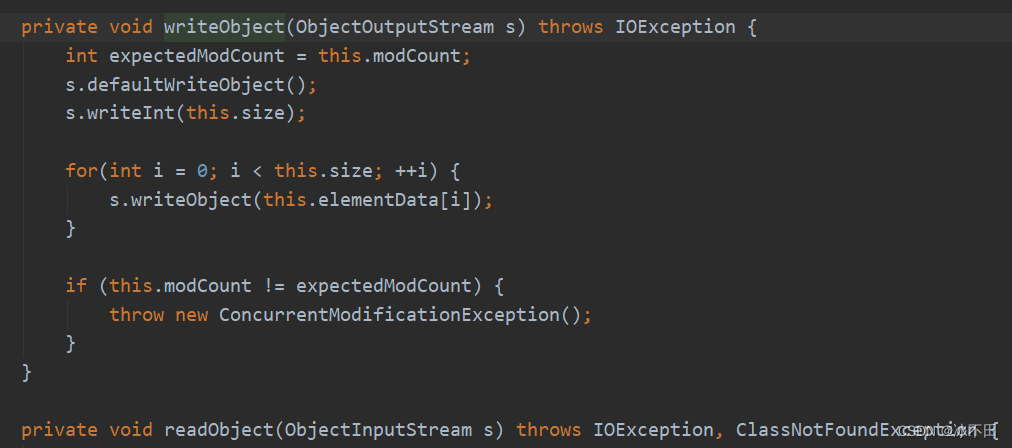
Arrays工具类中的asList方法:有坑
基本数据类型不支持泛型!

LinkedList
链表,next和prev指针
实现了Deque(双端队列)接口,操作头部、尾部
CopyOnWriteArrayList
线程安全的ArrayList
读操作时无锁,读的是旧数组,写不会阻塞读,读写分离
写操作时加锁复制,ReentrantLock保证线程安全,修改数组之前先将数组拷贝一份,操作新数组,赋值给array后丢弃旧数组
弱一致性:写操作会生成新的数组,读的数据可能已经被修改
Set

volatile不会从缓存中获取数据,从主存中获取。用来修饰成员变量和静态变量,不能修饰局部变量,因为局部变量是线程私有。volatile只能保证可见性,不能保证原子性。而sy可以同时保证,但sy是重量级,volatile是轻量级。
HashMap


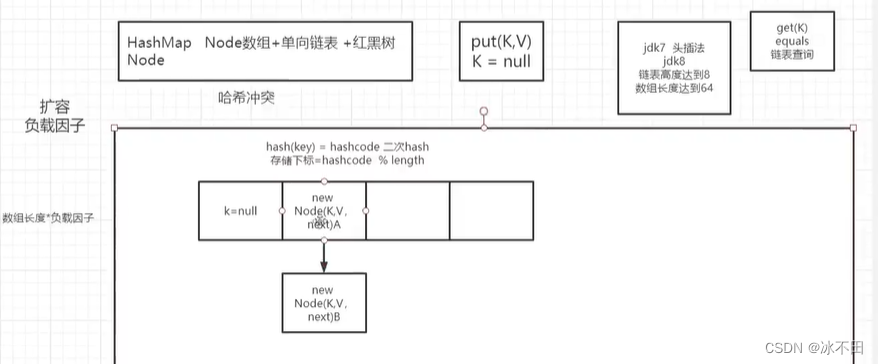
JDK1.7 数组+链表 扩容( 数组长度*负载因子)时链表采用头插法,容易死锁,多个线程在进行操作的时候,会导致闭链,然后死锁。
JDK1.8 数组+链表+红黑树 扩容采用尾插法 链表长度为8时转换为红黑树,为6时转换为链表。
初始容量可以入参指定,要求输入2的N次方
ConcurrentHashMap
JDK1.7

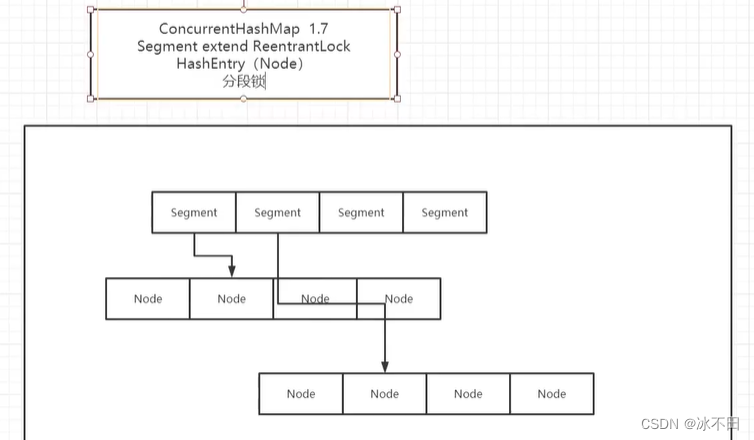
JDK 1.8

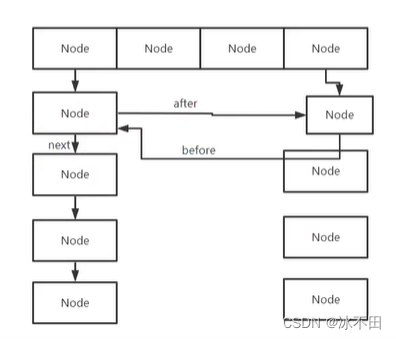
LinkedHashMap

阻塞队列
生产者:存,生产,入队
消费者:取,消费,出队
悲观锁 synchronized ReentrantLock
乐观锁 CAS+自旋
数组阻塞队列

- 入队时,对头入队,队列元素count为数组length ,放不进去,阻塞在notFull对象上;当队列出队一个元素时,唤醒一个notFull对象(数组空了一个,就可以继续入队)、
- 出队时,队尾出队,队列元素count为0,还要取的话,阻塞在notEmpty对象上;当队列里放入元素的时候,唤醒一个notEmpty对象(不管notEmpty上有没有阻塞)
先进先出(FIFO)。入队时记录putIndex(记录当前元素该放哪个位置,走到队尾时置为0);出队时记录takeIndex(记录当前取出元素的位置,走到队尾时置为0)
链表阻塞队列
(线程池中FixedThreadPoolExecutor使用,两把锁,读写不排斥)

- 入队时,从队尾开始入队(last),每次入队一个Node,都是last指针指向它,
- 出队时,对头开始出队(head),从head指向的Node开始取,取出后head后移
head指向首节点,last指向尾结节点。
删除时,两个锁一起加,保证删除准确。
同步队列
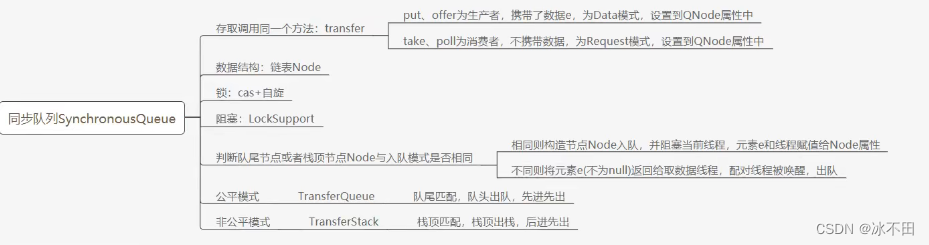
队头出队,队尾入队。 put() 、take() 调用的都是transfer(),SynchronousQueue(boolean fair),如果传入的是true(公平模式),采用的就是TransferQueue(队列:先进先出),否则(非公平模式),采用的是TransferStack(栈:后进先出)。

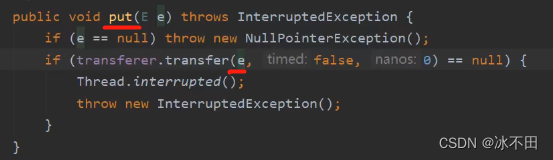
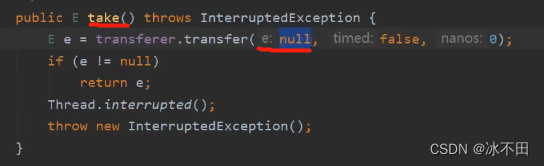
- 公平模式 :先进先出 FIFO
- 非公平模式 :后进先出 LIFO
对于同步队列来说:
生产者:生产数据(DATA标记,标记为生产者),并不一定入队
消费者:消费数据(REQUEST标记),并不一定出队
公平模式:先进先出
队头出队,队尾入队。take操作每次都和尾指针tail匹配,take是REQUEST模式,tail指向的node是DATA模式,这时就要出队,为了保证先进先出,虽然和take匹配的是tail指向的节点,但是tail指向的节点并不是先进的,所以返回的并不是tail指向的节点,而是比tail先进来的节点。
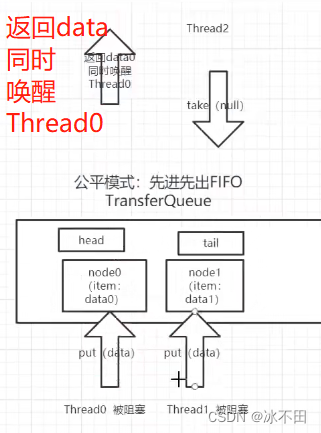
入队的不一定是put,也就时不一定是生产者,也可以是take消费者(如下图,与上图类似)。
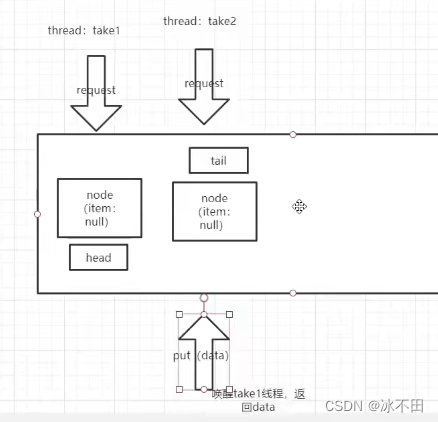
非公平模式:后进先出(类似于非公平模式,只不过换成后进的先出了,因为是栈)
同步队列中没有使用锁,使用CAS(Unsafe)+自旋,但是也不能无限次自旋,达到一定的自旋次数之后会阻塞。
LockSupport
concurrent包是基于AQS (AbstractQueuedSynchronizer)框架的,AQS框架借助于两个类:
- Unsafe(提供CAS操作)
- LockSupport(提供park/unpark操作)
park函数是将当前调用Thread阻塞,而unpark函数则是将指定线程Thread唤醒。
//LockSupport中 public static void unpark(Thread thread) { if (thread != null) UNSAFE.unpark(thread); } //LockSupport中 public static void unpark(Thread thread) { if (thread != null) UNSAFE.unpark(thread); }
与Object类的wait/notify机制相比,park/unpark有两个优点:
- 以thread为操作对象更符合阻塞线程的直观定义
- 操作更精准,可以准确地唤醒某一个线程(notify随机唤醒一个线程,notifyAll唤醒所有等待的线程),增加了灵活性。
其实park/unpark的设计原理核心是“许可”:park是等待一个许可,unpark是为某线程提供一个许可。如果某线程A调用park,那么除非另外一个线程调用unpark(A)给A一个许可,否则线程A将阻塞在park操作上。
unpark操作可以再park操作之前。也就是说,先提供许可。当某线程调用park时,已经有许可了,它就消费这个许可,然后可以继续运行。但是这个“许可”是不能叠加的,“许可”是一次性的。比如线程B连续调用了三次unpark函数,当线程A调用park函数就使用掉这个“许可”,如果线程A再次调用park,则进入等待状态。
LinkedTransferQueue

优先级阻塞队列
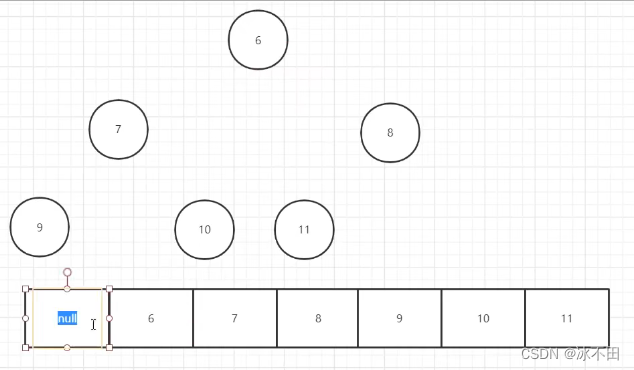
数组不是一个单纯的数组,是为了维护二叉堆(完全二叉树,小顶堆:每一个元素大于父节点;大顶堆:每一个元素小于父节点。优先级队列中采用的是小顶堆)
()第一个元素null,为了更方便找到每一个节点的父节点

延迟队列


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









