









上一篇是让大家快速安装部署dgraph,这一篇就简单介绍一下dgraph的使用。
顺序观看,效果更佳。
dgraph官网链接,英语好的可以直接食用。 https://dgraph.io/docs/tutorial-2/#deleting-a-predicate
https://dgraph.io/docs/tutorial-2/#deleting-a-predicate
目录
一、简单使用之突变(mutate)与查询(query)
1.1 简单介绍
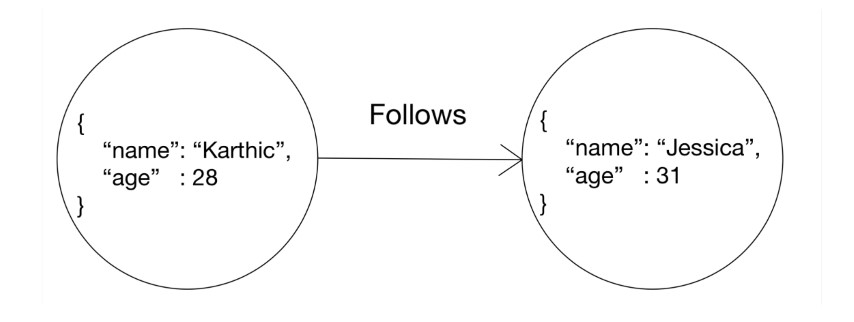
在图形数据库中,概念或实体表示为节点。可能是销售、交易、地点或个人,所有这些实体都表示为图形数据库中的节点。
边表示两个节点之间的关系。上图中的两个节点代表人:Karthic和Jessica。您还可以看到这些节点具有两个相关属性:名称和年龄。节点的这些属性在Dgraph中称为谓词。
Karthic跟着Jessica。它们之间的以下边缘表示它们的关系。连接两个节点的边在Dgraph中也被称为谓词,尽管这条边指向另一个节点,而不是字符串或整数。
1.2 突变(Mutate)
Dgraph中的创建、更新和删除操作称为突变。
Ratel使运行查询和突变变得更容易。我们将在教程系列中探索更多的功能。
让我们转到“突变”选项卡,将以下突变粘贴到文本区域。现在不要执行它!
{
"set": [
{
"name": "Karthic",
"age": 28
},
{
"name": "Jessica",
"age": 31
}
]
}
上面的查询创建了两个节点,一个对应于与“set”关联的每个JSON值。但是,它不会在这些节点之间创建边。
对突变进行一个小的修改就能修复它,因此在它们之间形成了一个边缘。
{
"set": [
{
"name": "Karthic",
"age": 28,
"follows": {
"name": "Jessica",
"age": 31
}
}
]
}
让我们执行这个突变。单击Run(运行)并启动!
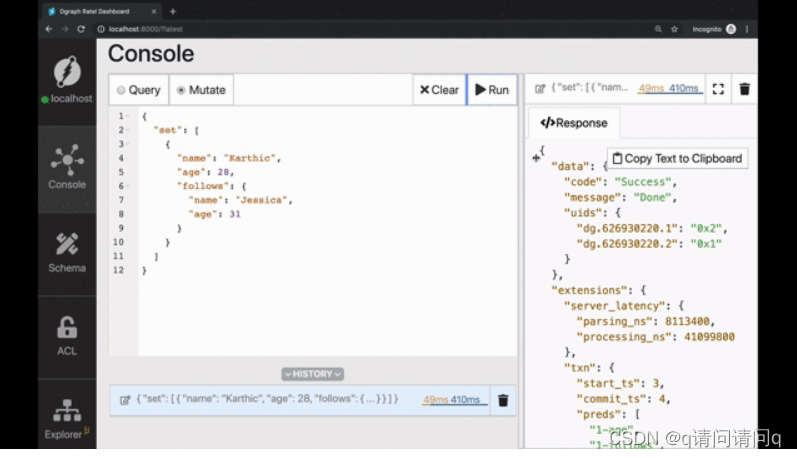
可以在响应中看到,已经创建了两个UID(通用标识符)。响应的“uids”字段中的两个值对应于为“Karthic”和“Jessica”创建的两个节点。
1.3、查询
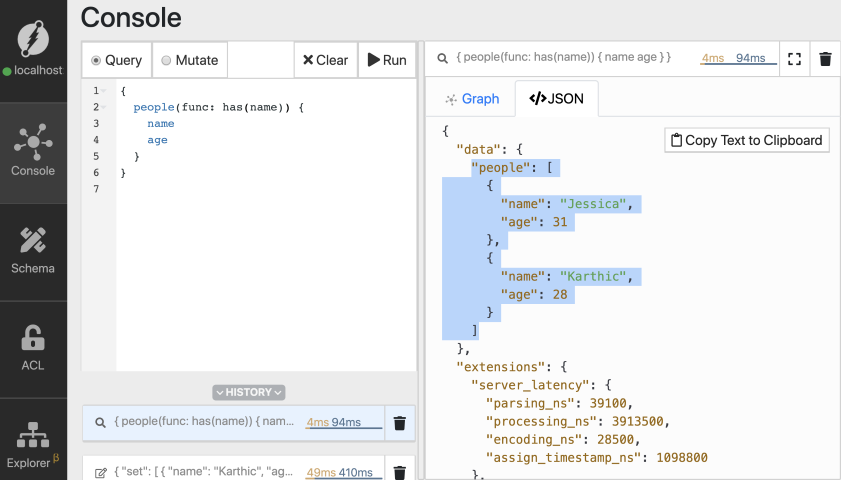
现在,让我们运行一个查询来可视化刚刚创建的节点。我们将使用Dgraph的has函数。表达式has(name)返回具有与其关联的谓词名称的所有节点。
{
people(func: has(name)) {
name
age
}
}这次转到“查询”选项卡,输入上面的查询。然后,单击屏幕右上方的Run(运行)。
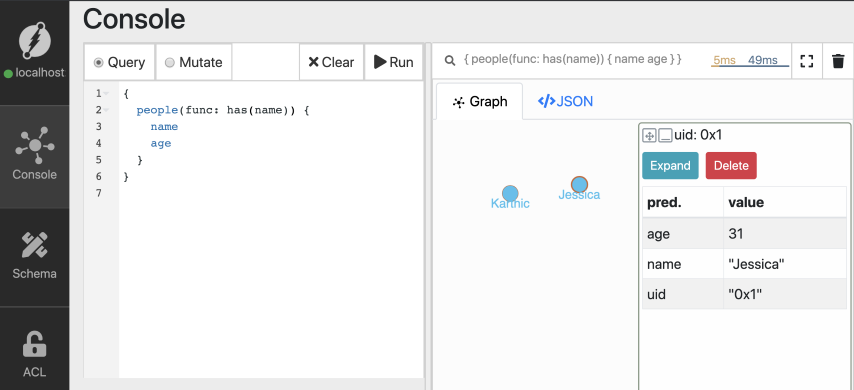
只需单击其中任何一个,注意节点被分配了UID,与我们在突变响应中看到的UID相匹配。
您还可以在右侧的JSON选项卡中查看JSON结果。
了解查询
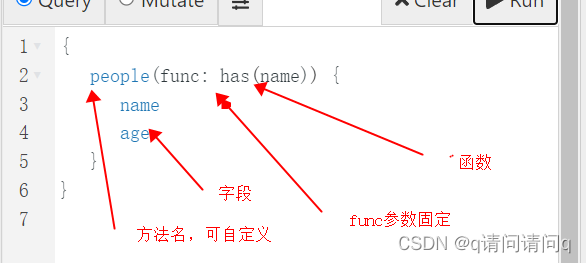
查询的第一部分是用户定义的函数名。在我们的查询中,我们将其命名为people。但是,您可以使用任何其他名称。
func参数必须与Dgraph的内置函数关联。Dgraph提供了各种内置功能。has函数就是其中之一。查看查询语言指南,了解Dgraph中其他内置函数的更多信息。
查询的内部字段name,age类似于SQL select语句或GraphQL查询中的列名!
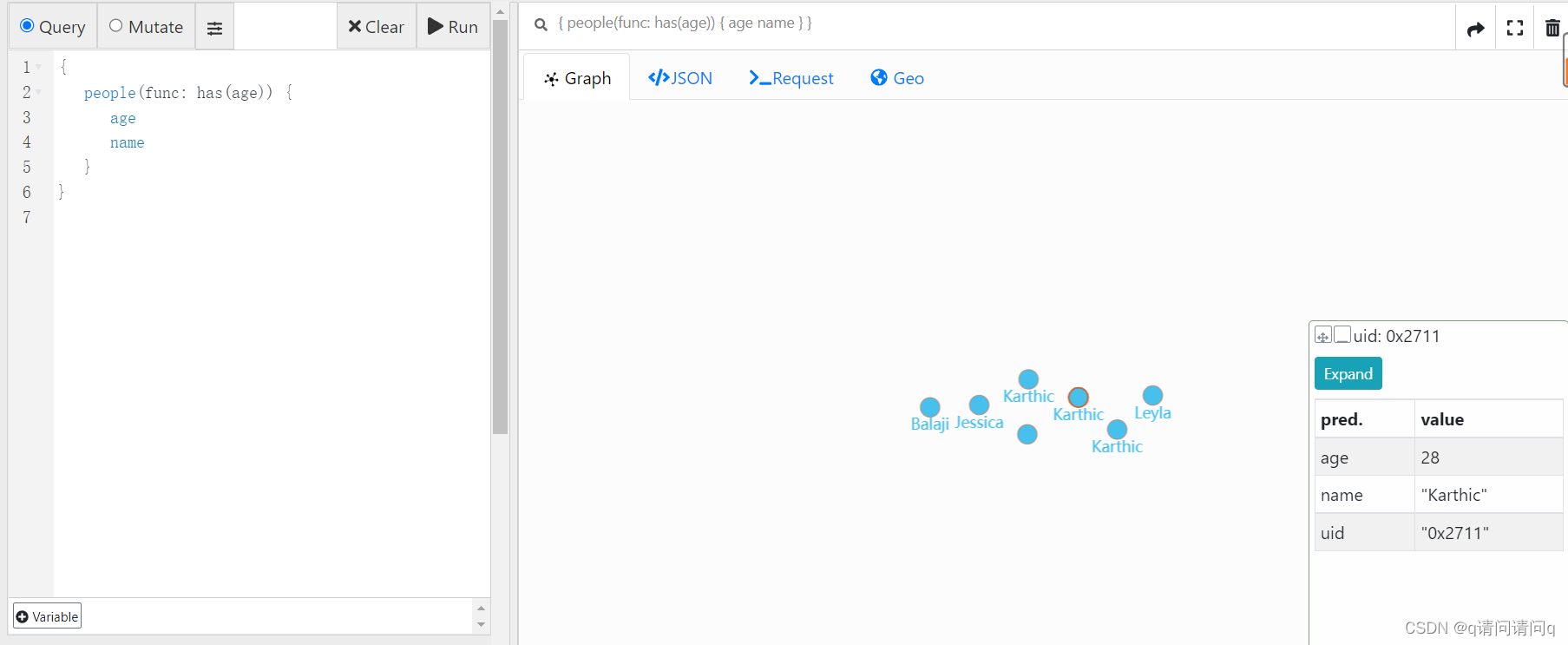
类似地,也可以使用has函数查找具有年龄谓词的所有节点。
{
people(func: has(age)) {
name
}
}
二、基本操作
在上一节的入门教程中,我们学习了Dgraph的一些基础知识。包括如何运行数据库、添加新节点和谓词以及如何查询它们。
在本教程中,我们将构建上述Graph,并了解有关使用节点的UID(通用标识符)进行操作的更多信息。具体来说,我们将了解:
- 查询和更新节点,使用其UID删除谓词。
- 在现有节点之间添加边。
- 向现有节点添加新谓词。
- 遍历图形。

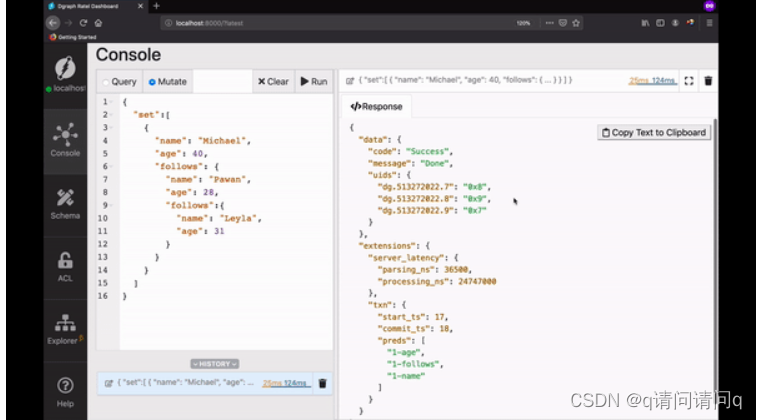
首先,让我们创建Graph。
转到Ratel的变异选项卡,将下面的变异粘贴到文本区域,然后单击运行。
{
"set":[
{
"name": "Michael",
"age": 40,
"follows": {
"name": "Pawan",
"age": 28,
"follows":{
"name": "Leyla",
"age": 31
}
}
}
]
}
1、使用UID查询
节点的UID可用于查询它们。内置函数uid将uid列表作为可变参数,因此您可以传递一个(例如uid(0x1))或根据需要传递多个(例如uid(0x1,0x2))。
它返回作为输入传递的相同UID,无论它们是否存在于数据库中。但是,只有当UID及其谓词都存在时,才会返回所请求的谓词。
让我们看看uid函数的作用。
首先,让我们复制为Michael创建的节点的UID。
转到查询选项卡,键入下面的查询,然后单击运行。
{
find_using_uid(func: uid(MICHAELS_UID)){
uid
name
age
}
}
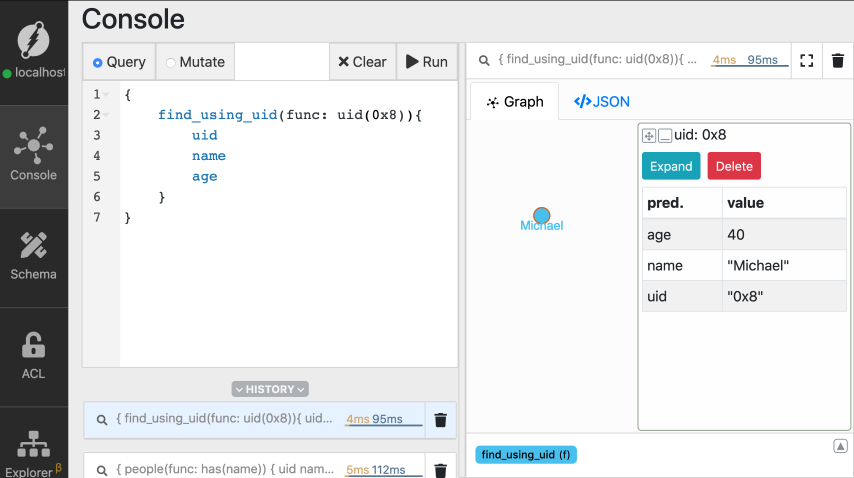
注意:MICHAELS_UID在图像中显示为0x8。您在计算机上获得的UID可能具有不同的值。
2、使用节点的UID更新谓词
您还可以使用节点的UID更新节点的一个或多个谓词。
Michael最近庆祝了他的41岁生日。让我们把他的年龄更新到41岁。
转到突变选项卡并执行突变。同样,不要忘记用Michael节点的实际UID替换占位符MICHAELS_UID。
{
"set":[
{
"uid": "MICHAELS_UID",
"age": 41
}
]
}
我们之前使用set创建了新节点。但在使用现有节点的UID时,它会更新其谓词,而不是创建新节点。
你可以看到迈克尔的年龄更新到41岁。
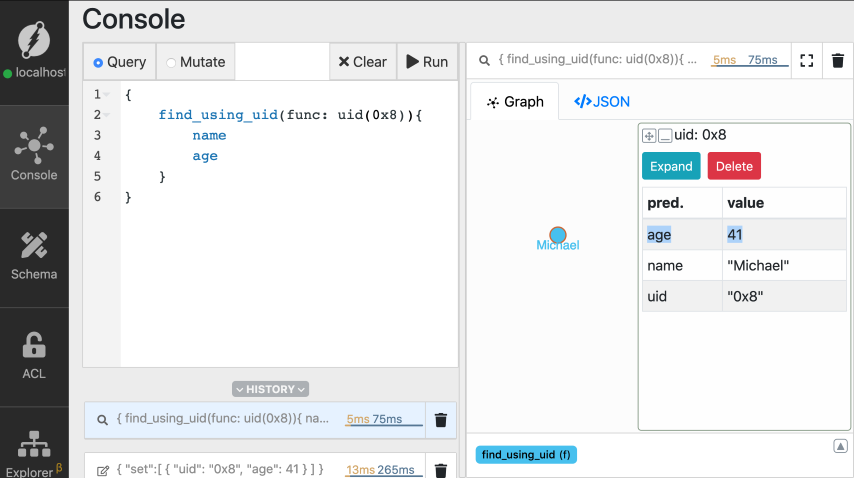
同样,您也可以向现有节点添加新谓词。由于Michael的节点不存在谓词国家,因此它创建了一个新的节点。
3、使用节点的UID向现有节点添加新谓词。
{
"set":[
{
"uid": "MICHAELS_UID",
"country": "Australia"
}
]
}
4、使用节点的UID在现有节点之间添加边。
还可以使用现有节点的UID在现有节点之间添加边。
比方说,莱拉开始跟着迈克尔。
我们知道,它们之间的这种关系必须通过在它们之间创建以下边来表示。
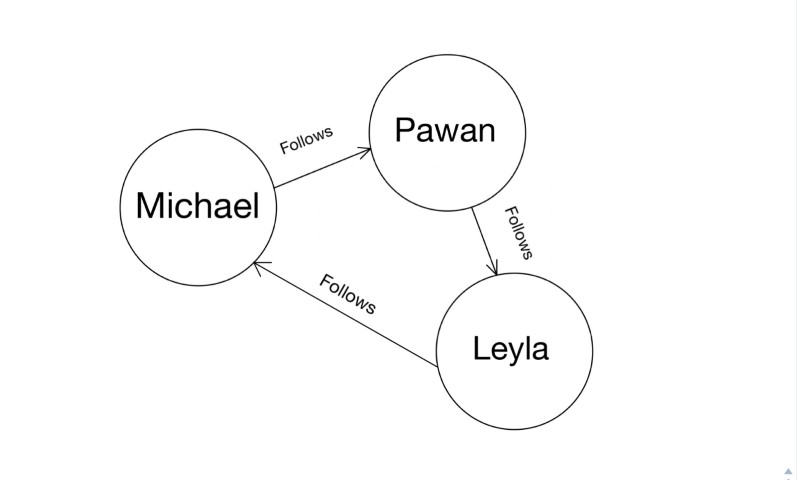
首先,让我们从Ratel复制Leyla和Michael节点的UID。
现在,用复制的占位符替换占位符LEYLAS_UID和MICHAELS_UID,并执行突变。
{
"set":[
{
"uid": "LEYLAS_UID",
"follows": {
"uid": "MICHAELS_UID"
}
}
]
}5、遍历
图形数据库提供了许多不同的功能。遍历就是其中之一。
遍历节点与节点之间的关系相关的问题或查询。因此,像这样的问题,迈克尔追随谁?通过遍历以下关系来回答。
让我们运行遍历查询,然后详细了解它。
{
find_follower(func: uid(MICHAELS_UID)){
name
age
follows {
name
age
}
}
}
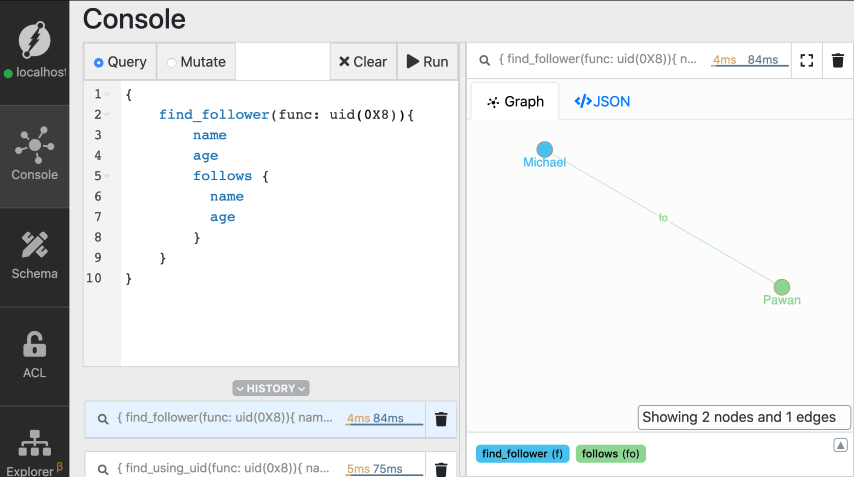
查询由三部分组成:
选择根节点。
1、首先,需要选择一个或多个节点作为遍历的起点。这些称为根节点。在上面的查询中,我们使用uid()函数选择为Michael创建的节点作为根节点。
2、选择要遍历的边
您需要指定要遍历的边,从选定的根节点开始。然后,遍历沿着这些边从一端移动到另一端的节点。
在我们的查询中,我们选择从Michael的节点开始遍历以下边。遍历将通过下面的边为Michael返回连接到该节点的所有节点。
3、指定要返回的谓词
由于Michael只跟踪一个人,遍历只返回一个节点。这些是2级节点。根节点构成了一级节点。同样,我们需要指定要从二级节点返回的谓词。
6、多级遍历
第一级遍历返回Michael后面的人。下一级遍历进一步返回他们依次跟随的人。
该模式可以重复多次以实现多级遍历。当我们遍历Graph的每个级别时,查询的深度增加一
{
find_follower(func: uid(MICHAELS_UID)) {
name
age
follows {
name
age
follows {
name
age
}
}
}
}
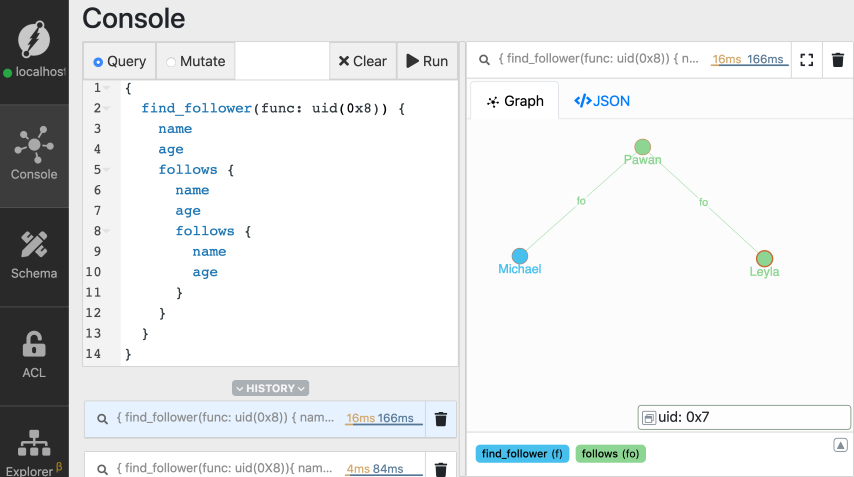
这个查询真的很长!如果你问,难道没有一个内置函数可以让多级深度查询或遍历变得容易吗?
答案是肯定的!这就是recurse()函数的作用。
7、递归遍历
递归查询使执行多级深度遍历更加容易。它们允许您轻松遍历Graph的子集。
通过以下递归查询,我们可以获得与上次查询相同的结果。但是,具有更好的查询体验。
{
find_follower(func: uid(MICHAELS_UID)) @recurse(depth: 4) {
name
age
follows
}
}
在上面的查询中,递归函数从Michael的节点开始遍历图。可以选择任何其他节点作为起点。depth参数指定遍历查询应考虑的最大深度。
让我们在用Michael的节点UID替换占位符之后运行递归遍历查询。
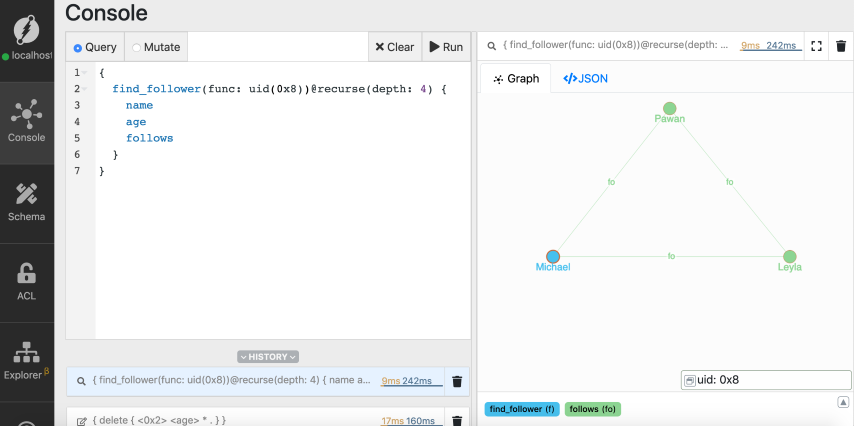
8、删除谓词
可以使用删除突变删除节点的谓词。下面是删除突变的语法,用于删除节点的任何谓词,
{
delete {
<UID> <predicate_name> * .
}
}
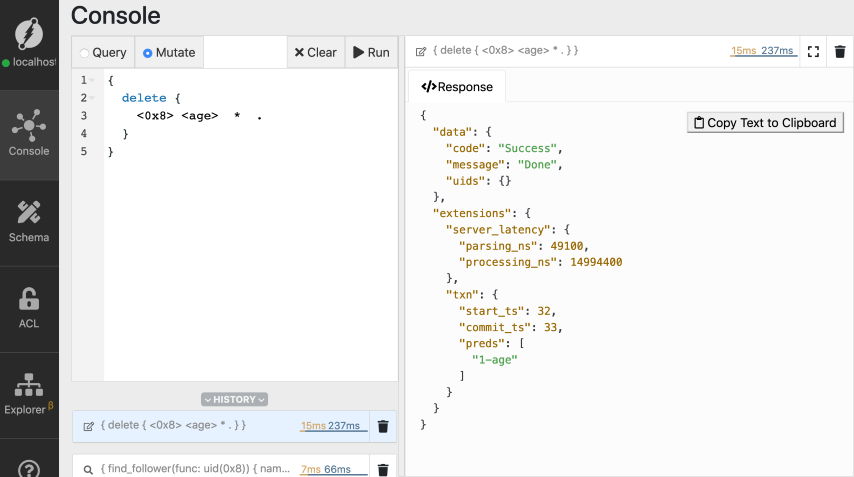
使用上面的突变语法,让我们组成一个删除突变。让我们删除Michael节点的年龄谓词。
{
delete {
<MICHAELS_UID> <age> * .
}
}

















 5000
5000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









