






首先我们要知道为什么会有垃圾回收机制,因为垃圾回收机制可以防止程序员忘记释放内存导致资源泄露的情况,这样也提高了程序员的幸福感。我们举一个例子更好的理解一下,假如我每次回到家就把衣服仍在沙发上,而不是收进衣柜,久而久之,沙发上就堆满了我的衣服,要是没有我们的垃圾回收机制,我们就需要手动的沙发上的衣服放回衣柜,而如果我们有垃圾回收机制,那这时候我们不用关心这个沙发上会堆满衣服,因为有人会帮我们自动放回衣柜。垃圾回收机制看起来非常的好,但是也有缺点:
1.会消耗额外的系统资源。
2.内存的释放可能会延迟,不能够立马释放。
3.那就是会出现STW(stop the word)问题,这个问题我们举个例子,就像我们以前在家里的时候,肯定会坐在电脑前忙活一些事情,例如看视频玩游戏,这时候你妈妈进来打扫卫生,叫你让开,然后这时候你就要离开电脑,然后没法进行下一步操作。这就是stop the word问题,我们通过字面意思也能看出这个问题叫做世界静止。发生在我们的代码中的表现就是,代码停住了,没法执行下一步操作。
我们这里只介绍堆内存的垃圾回收,那我们要具体回收什么?
我们要回收的是完全不使用的对象,那我们要怎么去寻找这么一个完全不使用的对象呢?这就要通过我们的死亡对象判定算法来判断,我们一般有两种死亡判断算法:1.引用计数 2.可达性分析,因为我们的Java是使用我们的可达性分析,所以这里不讲解引用计数。
可达性分析:如同所示
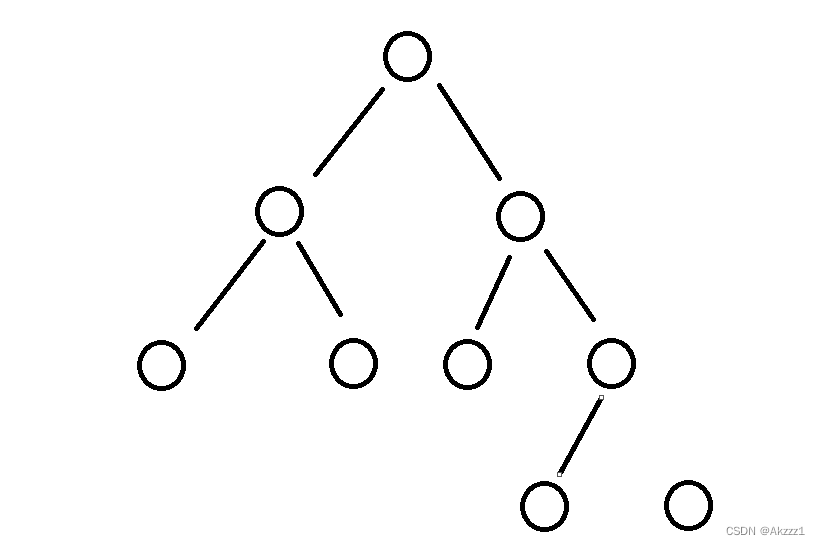
就像我们的树的遍历一样,不能到达的地方我们就视为是垃圾,需要进行回收,然后我们从开始遍历的节点称为GCRoot。我们从字面意思上也能理解:可达性分析,可以到达的分析,所以不能到达的地方就需要进行垃圾回收。
我们找到了垃圾之后要怎么进行回收呢?
这时候就有三种垃圾回收算法:1.标记-清除算法 2.复制算法 3.标记-整理算法
1.标记-清除算法:

假设黑色的是我们需要回收的垃圾,这时候我们会发现,需要回收的垃圾可能是分布在不同的地方,这时候会造成一个什么问题呢?那就是会造成我们的内存碎片这样的一个问题,什么是内存碎片?那就是我们回收垃圾的时候垃圾的位置可能是不连续的,这就导致如果我们想要在申请一块连续的内存空间会变难,当我们需要申请较大的一块内存空间的时候,可能会申请失败。为了解决内存碎片的问题,我们的解决方案就是复制算法。
2.复制算法:
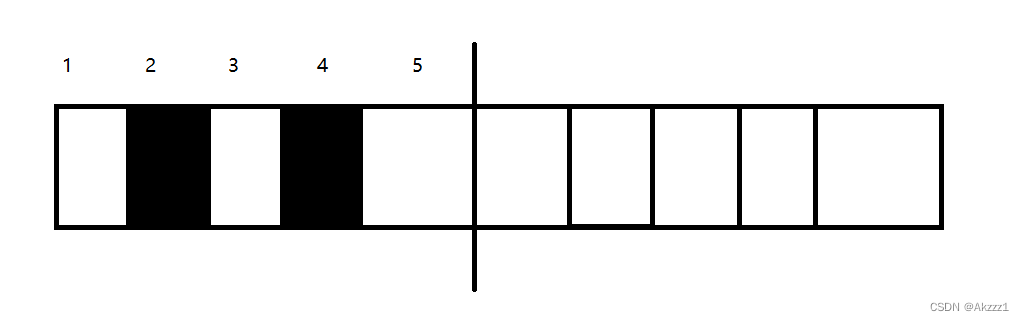
我们把我们的堆空间分为两个大块,假设我们左边要回收2,4这两块内存,我们的复制算法首先会把1,3,5复制一份到我们的另一半内存,然后把我们左边的内存全部进行回收,这样就解决了我们的内存碎片的问题 ,但是这边我们也能隐约看出复制算法得问题,那就是对我们得空间直接砍掉一半,堆我们得空间造成了很大的一个消耗。为了解决这个问题,就有了标记-整理算法
3.标记-整理算法:
这里的标记清理算法可以解决我们的内存碎片问题和我们的空间问题,就像我们的顺序表删除中间元素一样,把我们的不用的内存先回收然后把使用到的内存向前移动,知道把垃圾全部进行回收,这样子就解决了我们的内存碎片问题和空间利用的问题,但是这个算法的问题是,效率确实不高,因为我们需要移动内存。
每个垃圾回收算法都各有优缺点,而我们的Java是三种算法相互结合,我们也称这个算法为分代回收算法。
首先我们要知道一个对象在一个堆中是怎么分布的:
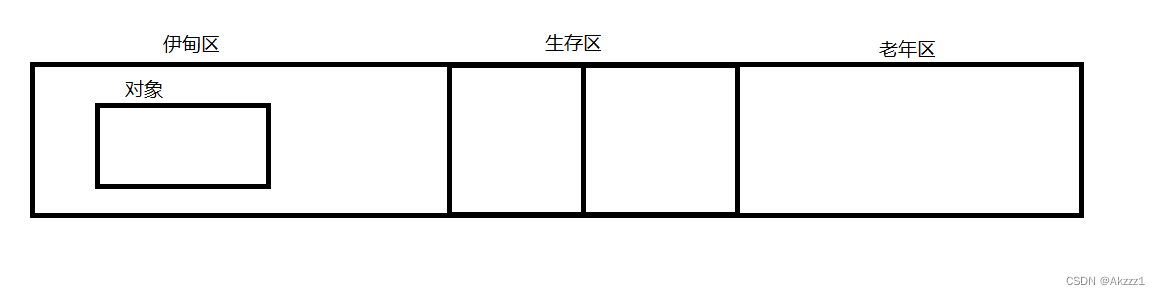
首先我们会把堆分为三个部分:1.伊甸区 2.生存区 3.老年区
伊甸区是用来存放我们新创建的对象的地方,这时候,我们的伊甸区会进行一轮GC,然后把存活下来的对象利用我们的复制算法拷贝到我们的生存区。那从图中我们就能发现说,我们的生存区这么小一块,能放得下我们的对象吗?这边我们从经验来看,一般大部分对象都活不过一轮GC就被回收了,所以存活下来的对象不会非常的多。我们还发现我们的生存区有两块,这是因为在我们的生存区中还需要进行GC,我们假设左边为存放我们的对象,JVM会对我们左边进行若干轮的GC,如果经过若干轮GC还活着,那就把我们左边的一个对象复制到我们右边的空间,这时候我们的JVM会继续GC,直到最后我们的JVM认为这个对象还会被使用很久,把生存区的对象放入我们的一个老年区。我们的老年区的这个也是需要进行我们的GC,但是整个GC的频率和周期相较于前面都比较长。我们一般情况下默认,我们一个对象从伊甸区到老年区是经过15轮的GC。
ps:我们老年代的对象存活率较高,没有额外的空间分配,所以老年代一般使用我们的标记-清除或者我们的标记-整理算法进行垃圾回收。

















 6278
6278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









