









目标:爬取百度搜索到的女生头像(百度图片通用)
1. 下载node
可以去官网下载最新版node.js安装程序。(地址:node官网)
2. 下载需要的依赖(模块)
这里需要用到superagent模块和node内置的fs模块,所以我们只需要下载superagent模块即可。
下载指令:npm install superagent (-g)加上-g是全局的意思,不加就是在你当前输入指令的目录下安装。
3. 查看目标网站
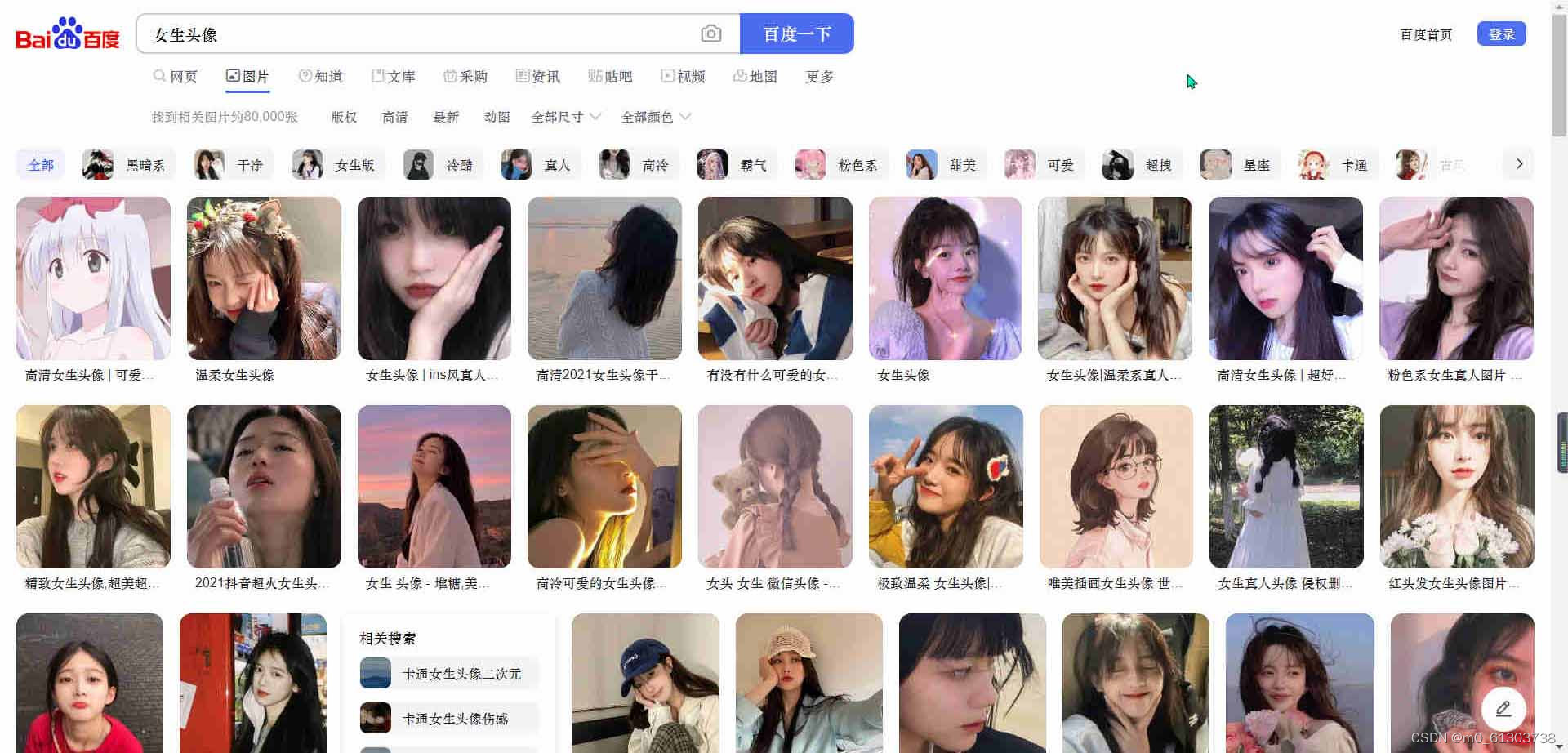
我们可以看到百度图片使用了懒加载,假如我们直接用代码来请求的话,那么就只能拿到很小一部分的图片,所以我们这里去手动拿到页面的信息,往下滑动滚动条,滑到你想要的位置之后,打开控制台(右键检查、F12、ctrl+shift+i),然后去复制html标签内容,创建一个文件(text.txt),将我们复制的页面内容放里面,接着我们就可以开始编写代码了。
我们先来分析一下页面,去检查页面上的图片:
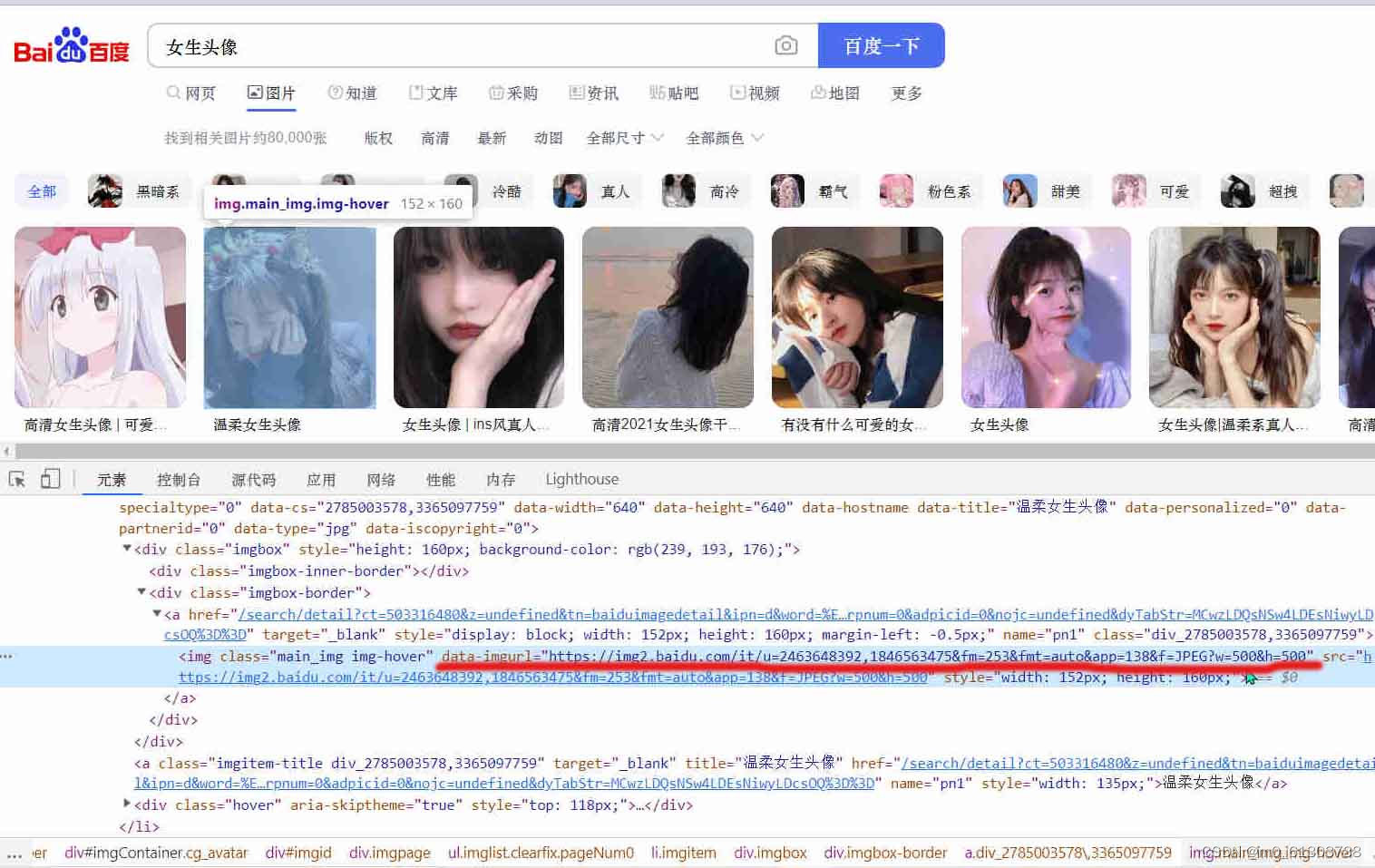
我们可以发现,图片的链接在data-imgurl="xxxxxxxxx"中,那么就可以通过正则来获取图片的链接。
话不多说,直接上代码
// 引入superagent模块,用于请求网址
const superagent = require('superagent');
// 引入fs模块,用于将获取到的图片数据保存到本地
const fs = require('fs');
// 读取页面内容
fs.readFile('./text.txt','utf-8',(err,data)=>{
if(err){
console.log('读取失败');
}else{
const txt = data.toString();
// 编写正则表达式
const reg = /(data-imgurl="https:\/\/).+?(fm=253&)/g;
// 使用正则获取页面内容中所有符合规则的字符串(这里获取出来的字符串就是所有图片的链接)(txt.match()方法返回值是个数组)
const URLS = txt.match(reg);
// 声明一个变量用于文件命名
let num = 0;
// 利用定时器+循环请求(每3000毫秒请求10张图片)
let timer = setInterval(() => {
for(let i = 0; i < 10; i++){
// 获取到图片的链接
const URL = (URLS[num*10+i].split('="'))[1];
// 请求图片地址 利用pipe管道传输给文件模块写入到本地的img文件夹下
superagent.get(URL).pipe(fs.createWriteStream('./img/'+(num*10+i)+'.png'));
console.log('第'+(num*10+i)+'张图片抓取成功');
// 判断请求完毕所有的图片后停止定时器
if ((num*10+i)==a.length){
// 延时3000毫秒之后停止(因为nodejs是一个异步程序,循环执行完毕之后可能 请求/写入 还在执行,所以我们不能直接停止程序,需要等 请求/写入 执行完毕之后再行停止)
setTimeout(() => {
clearInterval(timer);
console.log('抓取完毕');
},3000);
break;
}
}
num++;
},3000);
}
});这里有一个关键点,node是一个单线程异步程序,我们循环执行完毕时,图片的访问和文件的写入可能还没有执行完毕,这时候停止程序的话最后的几张图片可能获取不到或者写入一半被终止,导致图片损坏,所以我们要写上延时器等待几秒之后再停止程序。
我们来看一下效果图
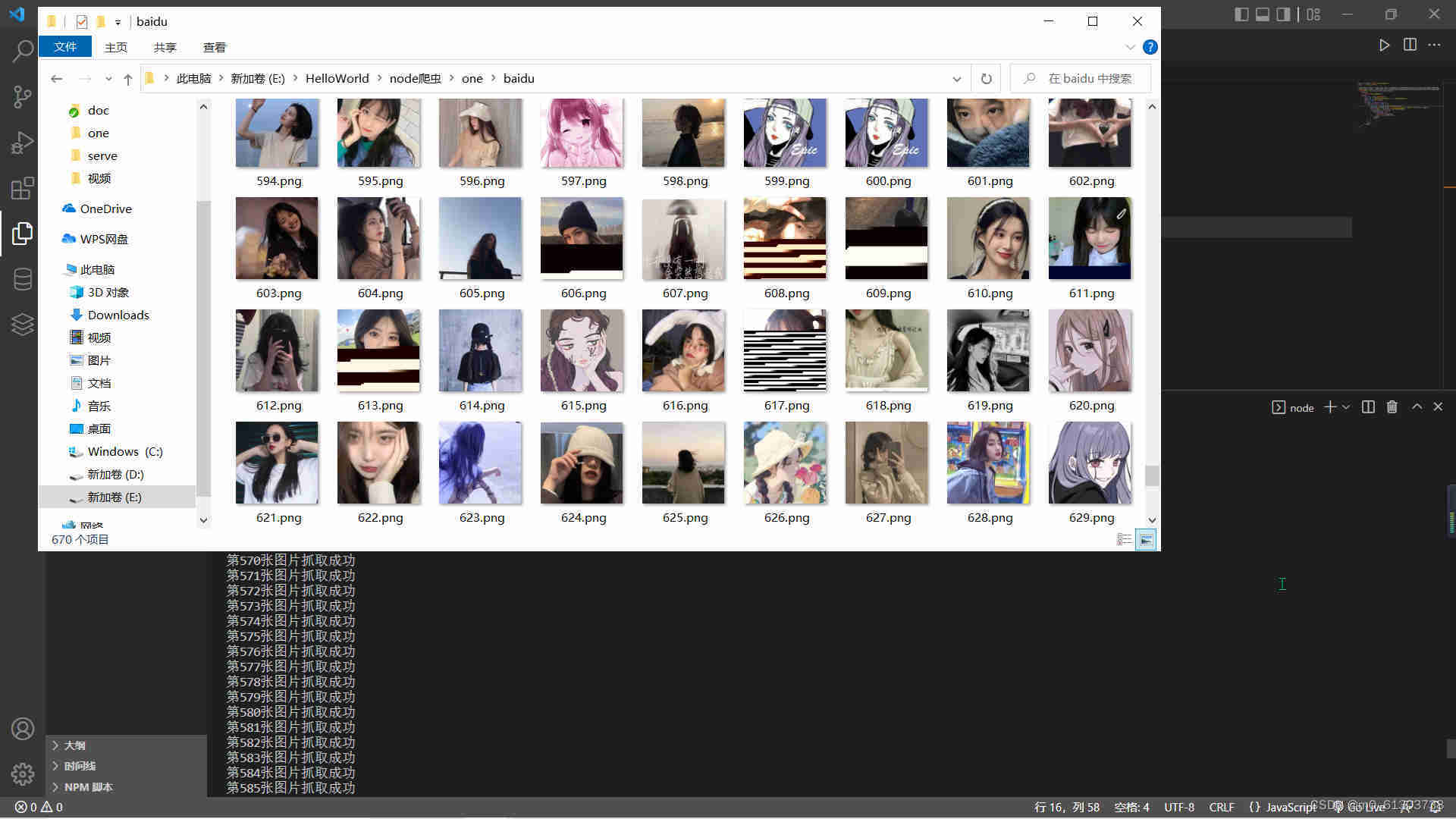
总结:那么到这里百度图片的爬取就已经完毕了,希望对你有所帮助,good bye!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









