







1 分页查询优化
1.1 (根据自增且连续的主键)分页查询
MySQL针对如下查询首先会读取10010条数据:
select * from employees limit 10000,10
使用主键索引优化:(限制条件:必须连续,中间不断层)
select * from employees where id > 90000 limit 5; 但这样的优化条件太苛刻,现实工作中不可能中间不删减几条数据?如何解决这个问题?
但这样的优化条件太苛刻,现实工作中不可能中间不删减几条数据?如何解决这个问题?
1.2 根据非主键字段排序的分页优化
分析如下SQL语句:
EXPLAIN select * from employees ORDER BY name limit 90000,5; 理论上来说数据集较小的情况下,会走二级索引idx_name_age_position;但MySQL会判断orderBy适不适合走索引
理论上来说数据集较小的情况下,会走二级索引idx_name_age_position;但MySQL会判断orderBy适不适合走索引
优化成如下语句:(覆盖索引优化 id和name均在idx_name_age_position)
EXPLAIN select * from employees e inner join (select id from employees ORDER BY name limit 90000,5) e1 on e.id = e1.id;
2 join查询优化
-- 示例表:
CREATE TABLE `t1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`), --主键索引
KEY `idx_a` (`a`) --给a创建索引
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
create table t2 like t1;
-- 插入一些示例数据
-- 往t1表插入1万行记录
drop procedure if exists insert_t1;
delimiter ;;
create procedure insert_t1()
begin
declare i int;
set i=1;
while(i<=10000)do
insert into t1(a,b) values(i,i);
set i=i+1;
end while;
end;;
delimiter ;
call insert_t1();
-- 往t2表插入100行记录
drop procedure if exists insert_t2;
delimiter ;;
create procedure insert_t2()
begin
declare i int;
set i=1;
while(i<=100)do
insert into t2(a,b) values(i,i);
set i=i+1;
end while;
end;;
delimiter ;
call insert_t2();EXPLAIN select * from `t1` join t2 on t1.a = t2.a;
2.1 嵌套循环连接 Nested-Loop Join(NLJ) 算法
t2认为是驱动表,t1认为是被驱动表;优化器一般会优先选择小表做驱动表,跟innor join顺序无关
上面sql的大致流程如下:
1. 从表 t2 中读取一行数据(如果t2表有查询过滤条件的,会从过滤结果里取出一行数据)
2. 从第 1 步的数据中,取出关联字段 a,到表 t1 中查找
3. 取出表 t1 中满足条件的行,跟 t2 中获取到的结果合并,作为结果返回给客户端
4. 重复上面 3 步
扫描总行数:2*t2记录数
2.2 基于块的嵌套循环连接 Block Nested-Loop Join(BNL)算法
EXPLAIN select * from t1 inner join t2 on t1.b= t2.b;
由于两张表都没有b的索引,且小表为t2
上面sql的大致流程如下:
1. 把 t2 的所有数据放入到 join_buffer 中
2. 把表 t1 中每一行取出来,跟 join_buffer 中的数据做对比
3. 返回满足 join 条件的数据
扫描总行数:t1记录数+t2记录数;内存比对次数:t1记录数*t2记录数
2.3 join关联查询优化
驱动表:数据量比较小
被驱动表:数据量较大;由驱动表获取一条记录去与被驱动表比较
MySQL会选择小表当驱动表;被驱动表的条件尽量走索引
left join(左为主)、right join(右为主)已经确定了驱动/被驱动表
对于小表明确的定义:t1、t2按各自条件过滤后,结果集较小的
3 in和exists优化
原则:小表驱动大表
3.1 in
当t2表数据集较小时:in>exists
EXPLAIN select * from t1 where id in (select id from t2);
上述SQL等价于:
for(select id from t2){
select * from t1 where t2.id = t1.id;
}3.2 exists
当t2数据集较小时,exist>in
EXPLAIN select * from t2 where EXISTS (select 1 from t1 where t1.id = t2.id);
上述SQL等价于:
for(select * from t2){
select * from t1 where t2.id = t1.id;
}4 count(*)查询优化
字段有索引:count(*)>count(1)>count(字段)>count(主键 id)
字段无索引:count(*)≈count(1)>count(主键id)>count(字段)
原因:
主键id与字段比较:主键构成的索引树是聚簇索引,字段有索引会直接走二级索引
count(1)与count(字段)比较:count(字段)将字段放在内存中统计,而count(1)直接+1
count(*)MySQL做了优化,与count(1)逻辑类似,不取值而直接按行累加
5 阿里巴巴MySQL规范
设计表之前:
1 确定合适的大类型:数字、字符串、时间、二进制
2 确定具体的类型:有无符号、取值范围、变长定长等
5.1 数值类型
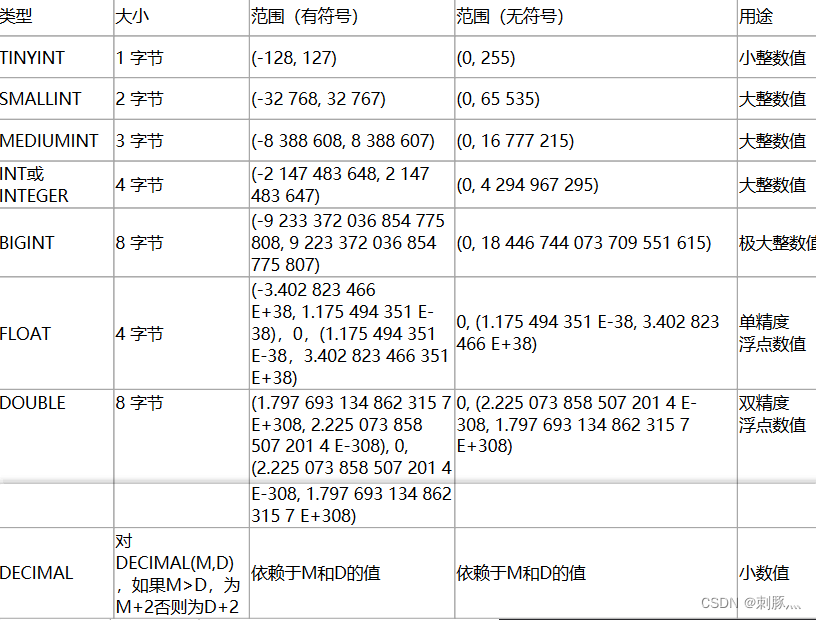
优化建议:
1 如果整形数据没有负数,如ID号,建议指定为UNSIGNED无符号类型,容量可以扩大一倍
2 INT(n)这个数字n仅表示现实的宽度,配合ZEROFILL,表示填充到n;例如5,0*n5;实际没用
5.2 日期和时间
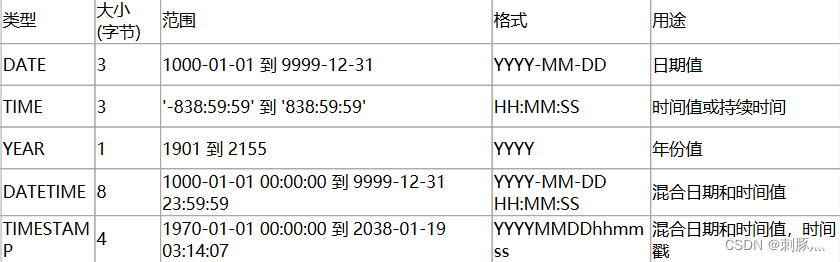
优化建议:
1 只关注日期,建议用DATE数据类型来保存日期;MySQL中默认的日期格式是yyyy-mm-dd
2 除非有特殊需求,一般的公司建议使用TIMESTAMP,它比DATETIME更节约空间,但是像阿里这样的公司一般会用DATETIME,因为不用考虑TIMESTAMP将来的时间上限问题
5.3 字符串
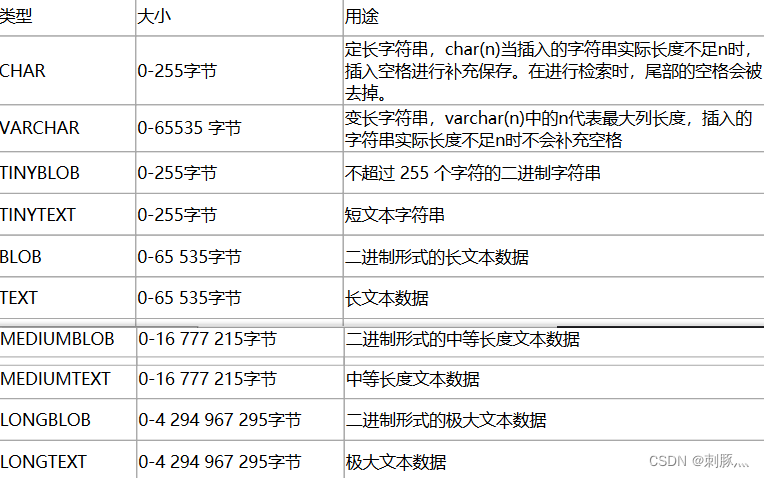
优化建议:
1 字符串的长度相差较大用VARCHAR;字符串短,且所有值都接近一个长度用CHAR
2 CHAR和VARCHAR适用于包括人名、邮政编码、电话号码和不超过255个字符长度的任意字母数字组合;能确定长度尽量用CHAR
3 尽量少用BLOB和TEXT,如果实在要用可以考虑将BLOB和TEXT字段单独存一张表,用id关联(考虑聚簇索引占内存)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









