







一、HDFS数据写流程
- 流程图如下
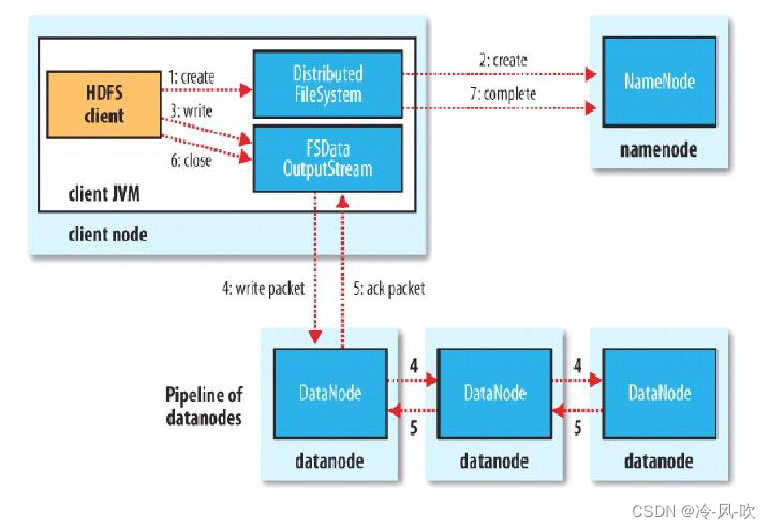
- 具体案例如下
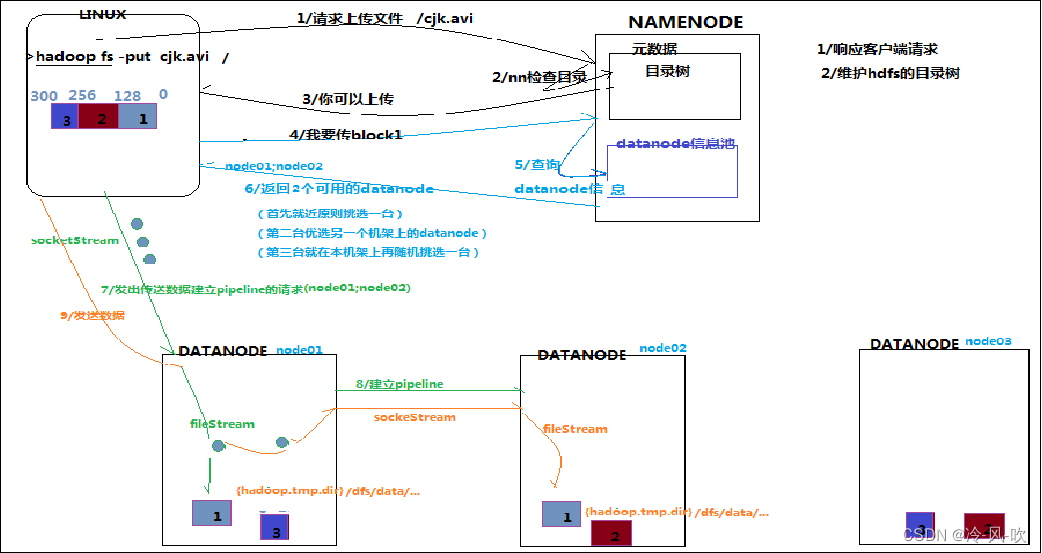
- 写入过程如下
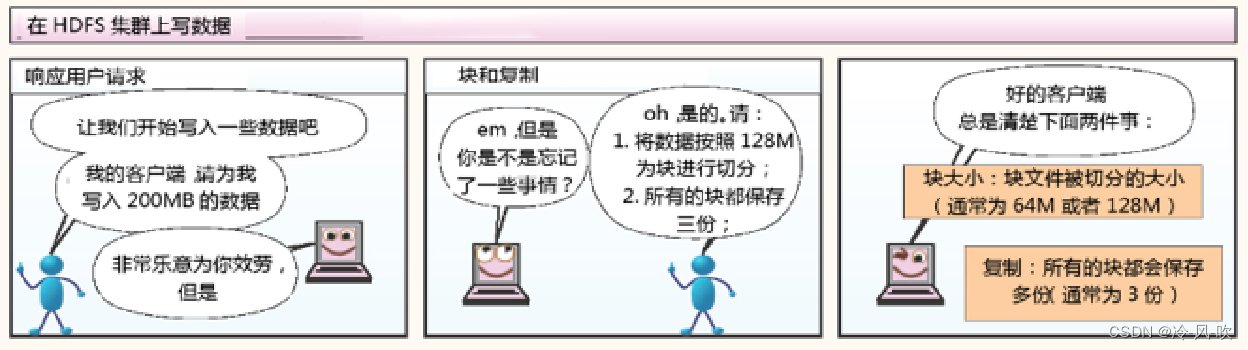
- Client发起文件上传请求,通过RPC向NameNode发起请求,NameNode检查目标文件是否已经存在,父目录是否存在,创建者是否有权进行操作
- NameNode返回是否可以上传(若成功则返回可以上传,否则会让客户端抛出异常)
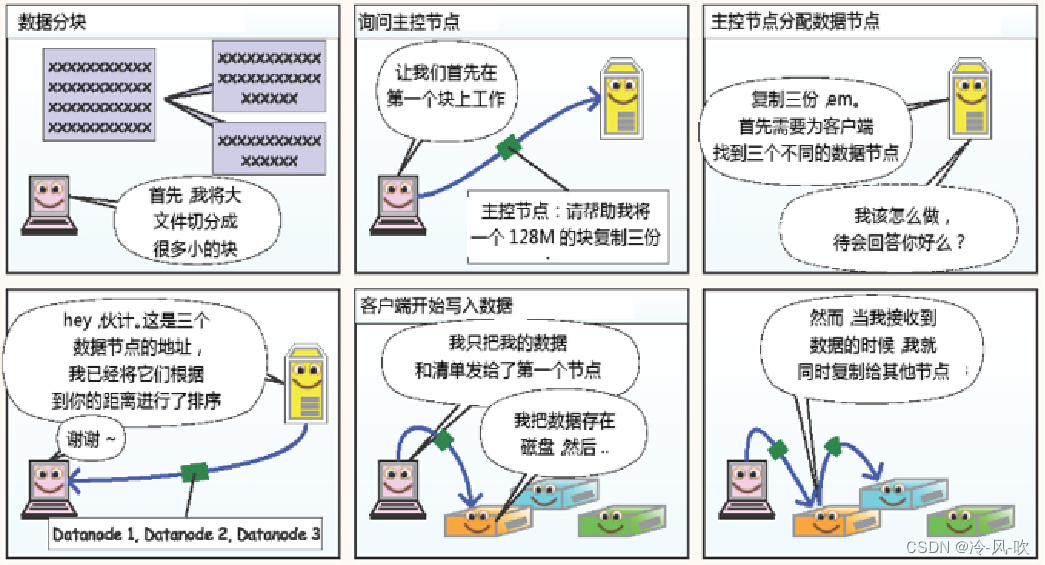
- 当客户端开始写入文件的时候,开发库会将文件切分为多个packets,并在内部以“dataqueue”的形式管理这些packets,并向Namenode申请新的blocks,clients请求第一个block该传输到哪些DataNode服务器上。
- NameNode返回三个DataNode服务器DataNode1,DataNode2,DataNode3
- Client请求3台中的一台DataNode1(遵循就近原则,如果都一样,就随机挑选一台DataNode;上传数据本质上是一个RPC调用建立pipline)上传数据,DataNode1收到请求会继续调用DataNode2,然后DataNode2调用DataNode3,将整个pipeline建立完成,逐级返回客户端
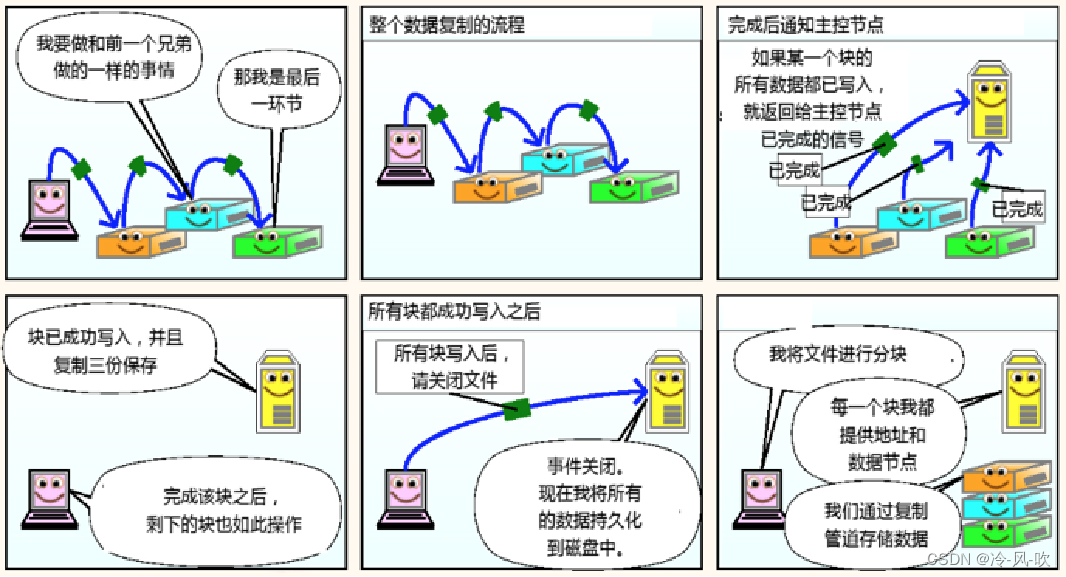
- Client开始往DataNode1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet(默认为64KB)为单位,DataNode1收到一个packet就会传递给DataNode2,DataNode2传递给DataNode3;DataNode1每传一个pocket会放入一个答应队列等待答应
- 到一个block传输完成之后,Client再次请求DataNode上传第二个block服务器
- 重复执行上述操作
二、HDFS数据读流程
-
流程图如下
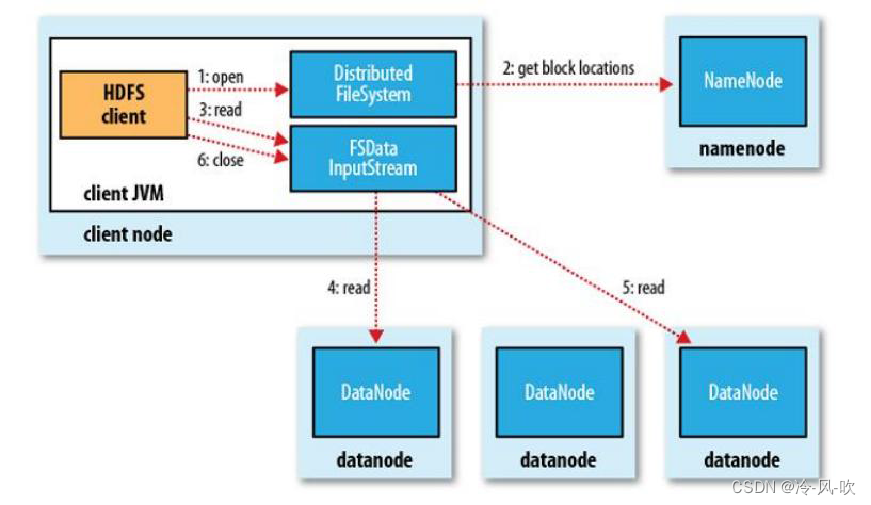
-
具体案例如下
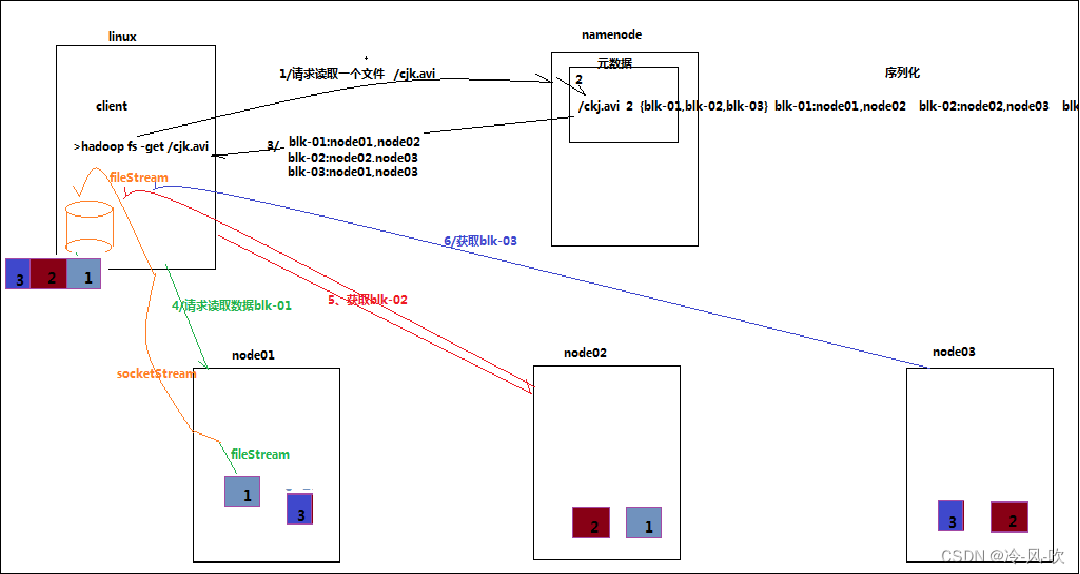
-
读过程如下
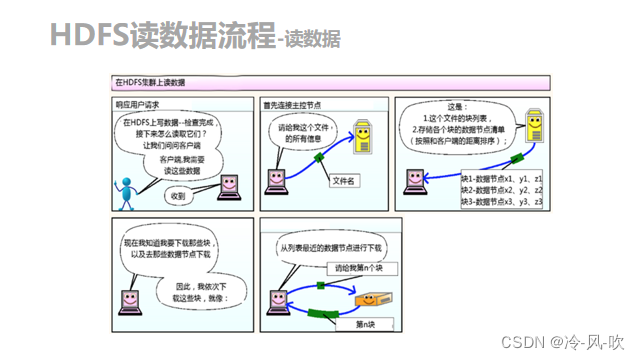
- client跟NameNode通信查询元数据,找到文件块所在的DataNode服务器
- 挑选一台DataNode(遵循就近原则,如果都一样,则随机挑选一台DataNode)服务器,请求建立socket流
- DataNode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做效验)
- 客户端以packet为单位接收,先存在本地缓存,然后写入目标文件。
三、HDFS读写实物图(漫画流程)
HDFS的读写流程就介绍完了,看着有点抽象,可以借助下边的图片来理解一下
1. 写数据
2. 读数据

老师上课讲的知识点,感觉挺重要的,然后就整理了一下。,若有不对或这描述不清楚的地方请指正,如果有帮助或者喜欢就给个赞和关注一下吧😁😁✌✌



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











