






【论文阅读】RULE: Reliable Multimodal RAG for Factuality in Medical Vision Language Models
论文地址:链接
github地址:链接
Accepted by EMNLP’24

1.论文背景与动机
- 增强医学多模型大模型(Med-LVLMs):尽管医学多模型大模型性能已经表现得的很不错,但是它们仍然容易产生偏离事实信息的回复,从而可能导致不正确的医学诊断,这种现象称作“幻觉”,在关键的医疗应用中,需要加强机制来确保事实的一致性。
- 检索增强生成(RAG)的挑战:直接将RAG策略用在医学多模型大模型上面临挑战,检索上下文过多或者是不足,或者过度依赖检索的信息,都会影响模型生成结果的准确性。
2.问题研究
问题描述:医学多模型大模型事实性困难面临着挑战,尽管RAG可以改进其表现,但是仍然面临以下的问题。
- 有限的检索上下文可能无法覆盖所有重要的信息。
- 过多的检索可能回引入不相关或者不正确的引用。
- 在模型最开始生成出正确的答案之后,应用RAG可能回导致过度依赖检索的上下文,导致不正确的答案。
3.主要贡献
-
提出的方法:主要贡献在于RULE引入了一种创新方法来增强基于检索的Med-LVLM。其核心贡献包括:
- 通过可证明的校准参考上下文的选择来控制事实风险
- 通过精心策划的偏好数据集进行偏好微调来平衡模型的知识和检索上下文
-
效果提升:在三个数据集上展示了 RULE 在医疗 VQA 和报告生成任务中的有效性,事实准确率平均提高了 47.4%。
-
提供代码和基准测试。
4.提出的方法
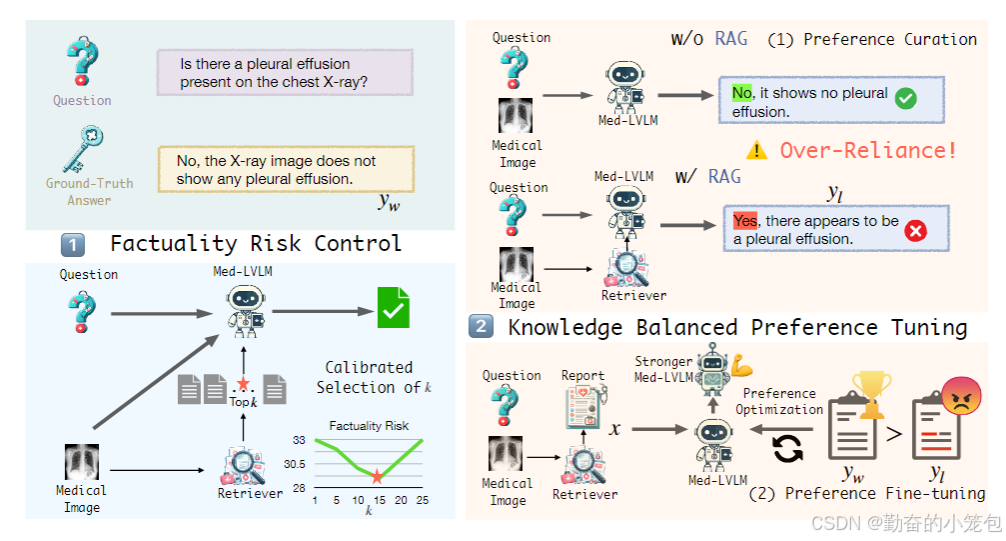
图 2:RULE 框架由两个主要部分组成: (1) 通过校准选择 k 来控制事实风险的策略;(2) 知识检索平衡调整。 在调整阶段,首先从样本中构建一个偏好数据集,在这些样本中,模型由于过度依赖检索到的上下文而出现错误。 随后,我们通过偏好优化,利用该数据集对 Med-LVLM 进行微调。
(1)检索上下文优化
- 在多模型知识检索阶段,RULE会检索与目标医学图像特征最相似的文本描述/报告,用于指导医学图像响应的生成。
- 根据CLIP的设计,检索器(retriever)首先使用视觉编码器和文本编码器分别将每个图像和相应的报告编码为嵌入表示。并通过对比学习进行微调以适应医学领域。
- 在推理阶段,当遇到需要生成医学报告的目标医学图像 xt 时,会提取前 K 个相似的医学报告。
(2)通过校准检索语境选择进行事实性风险控制
- 对于RAG策略,top-3/5结果通常用作参考,但是无法包含所有相关的检索上下文,尤其是面对医学图像的细粒度特征时。
- 提出一种基于统计的方法,自动确定检索上下文的最优数量k,以控制事实性风险。
- 通过计算不同k值的事实性风险和对应的概率,采用Bonferroni矫正等多重检验方法,选择满足风险容忍度的k值。
- 这一方法在验证集上进行校准,并直接用于测试集。
(3)知识平衡偏好微调
- 提出了知识平衡偏好微调策略减轻过度依赖检索上下文和增强在医学生成的事实性。
- 构造偏好数据集,将模型本来回答正确但是因为过度依赖检索导致模型回答错误的数据找出来,采用 Direct Preference Optimization(DPO)方法进行训练。
- 微调后的模型在生成医学内容时,能够更好地融合检索知识和模型固有知识。
5.结论与结果
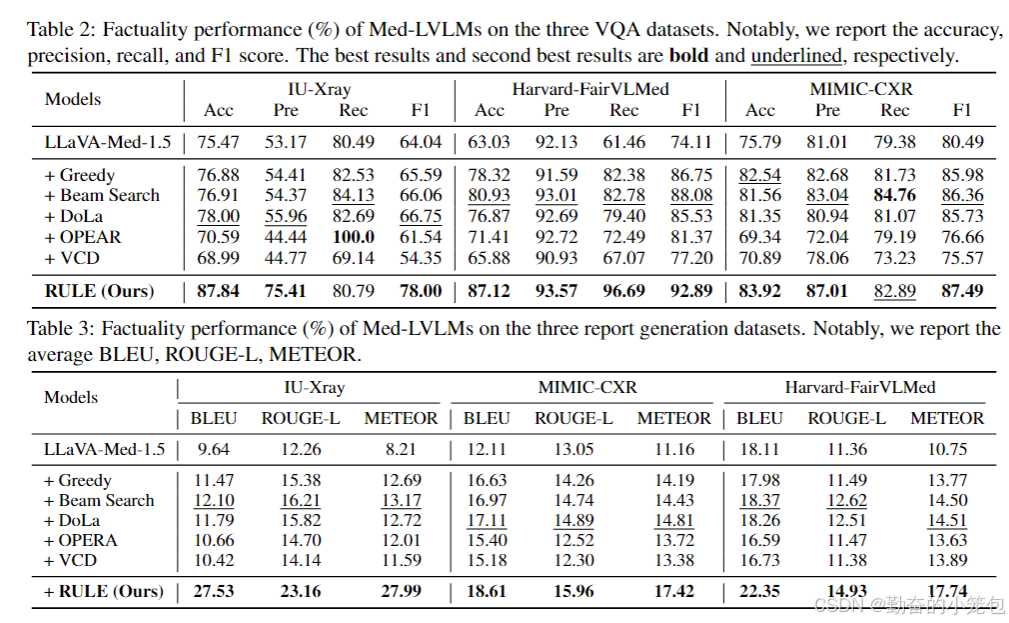
- RULE在各种减少幻觉方法的比较结果中,在两个任务中的平均准确率提高了47.4%。
- 无论是在放射学还是眼科学领域,RULE 都表现出卓越的性能,大大超过了其他开源 Med-LVLM。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









