







【大模型微调学习4】-大模型微调技术
1.Adapter Tuning (2019 Google) 开启大模型 PEFT
论文:《Parameter-Efficient Transfer Learning for NLP》
Adapters最初来源于CV领域的《Learning multiple visual domains with residual adapters》一文,其核心思想是在神经网络模块基础上添加一些残差模块,并只优化这些残差模块,由于残差模块的参数更少,因此微调成本更低。
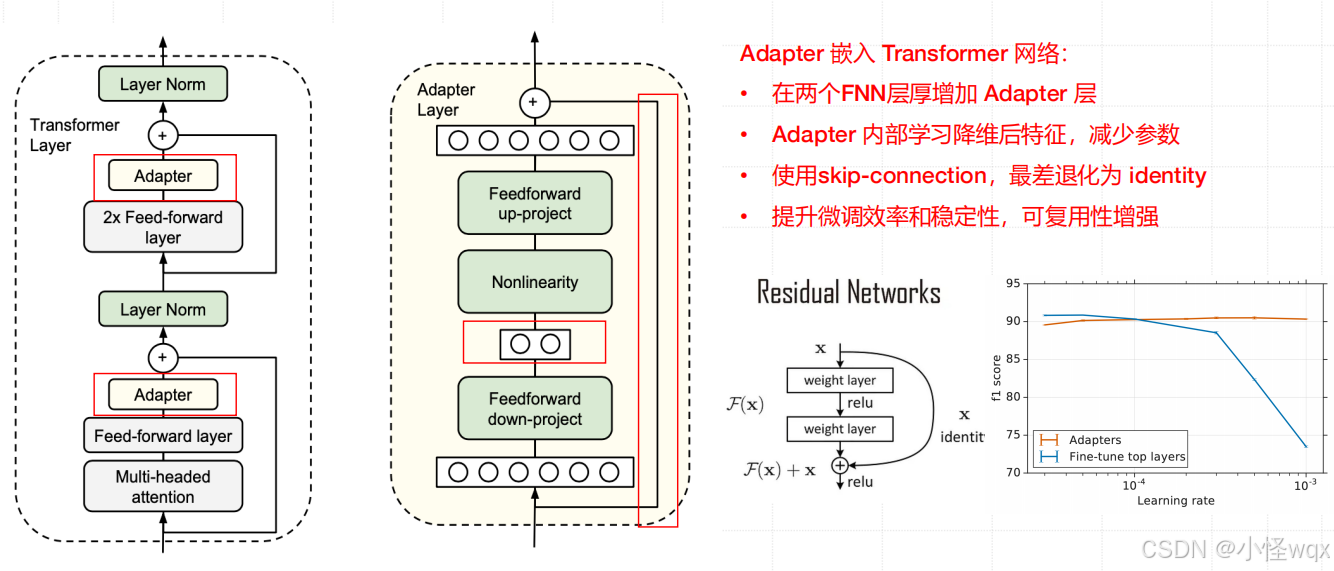
图1:Adapter Tuning核心技术图
- 左侧:我们在每个Transformer layer中两次添加适配器模块——在多头注意力后的投影之后和在两个前馈层之后。
- 右侧:适配器整体是一个bottleneck结构,包括两个前馈子层(Feedforward)和跳连接( skip connection)。
- Feedforward down-project:将原始输入维度d(高维特征)投影到m(低维特征),通过控制m的大小来限制Adapter模块的参数量,通常情况下,m<<d;
- Nonlinearity:非线性层;
- Feedforward up-project:还原输入维度d,作为Adapter模块的输出。通时通过一个skip connection来将Adapter的输入重新加到最终的输出中去(残差连接)
def transformer_block_with_adapter(x):
residual = x
x = SelfAttention(x)
x = FFN(x) # adapter
x = LN(x + residual)
residual = x
x = FFN(x) # transformer FFN
x = FFN(x) # adapter
x = LN(x + resid 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









