






试 题:广电大数据存储与处理
要 求:
1、以自己姓名缩写使用CREATE语句创建广电用户数据库XXX,并使用“IF NOT EXISTS”判断该数据库是否已经存在。
2、数据清洗(无效(重复、特殊线路)用户数据、无效收视行为数据、无效账单和订单数据)
3、使用LOAD语句实现数据的装载。
4、统计用户基本数据表中品牌名称的种类个数
5、查询用户发生状态变更的时间及开户时间
6、统计用户数最多的3种用户状态
7、统计2022年度月均账单金额最高的20个用户
8、查询用户宽带订单的地址数据
9、利用抽样查询对用户订购产品的情况进行抽样统计
10、统计出节目类型为直播的频道Top10
目 录
一、大数据环境搭建
二、数据预处理
三、创数据库并使用LOAD语句实现数据的装载
四、统计与查询
五、总结
- 大数据环境搭建
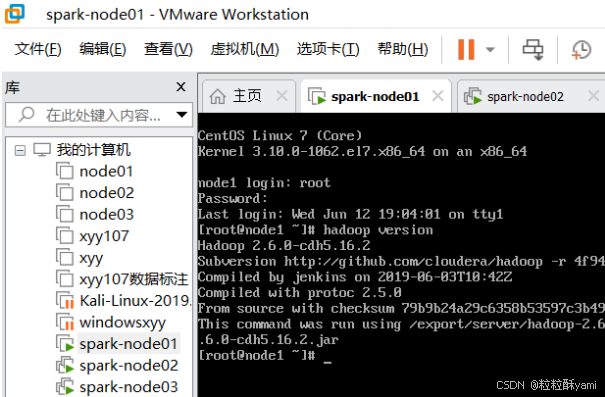
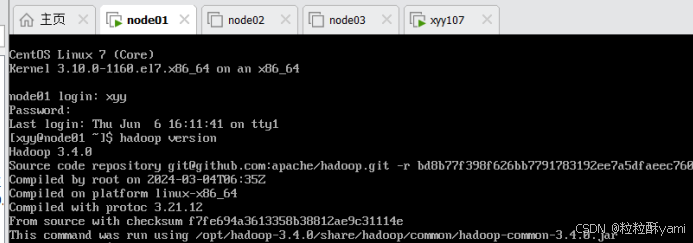
1.1安装Hadoop
Node01:192.168.88.100
Node02:192.168.88.101
Node03:192.168.88.102
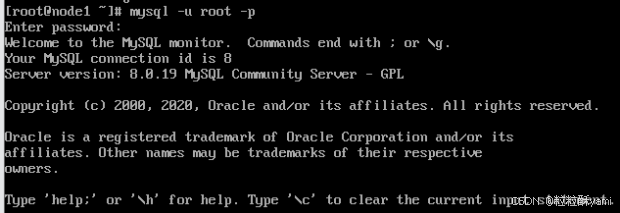
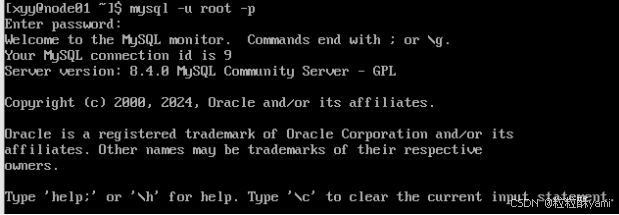
1.2安装MySQL
1.3安装Hive仓库
启动hadoop:
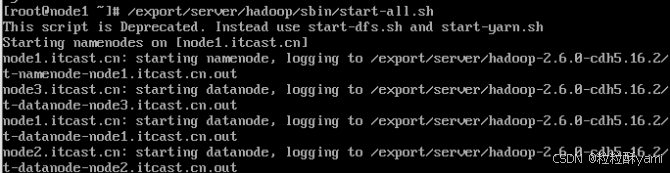
先开启 metastore:
nohup hive --service metastore &
再开启 hiveserver2:
nohup hive --service hiveserver2 &
命令netstat -ntulp |grep 10000:
![]()
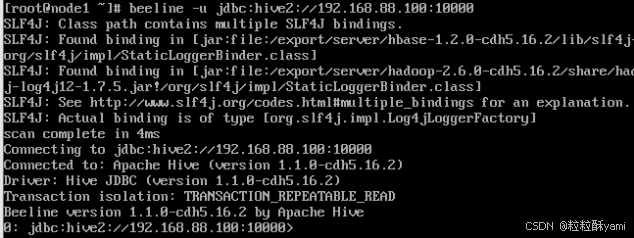
启动beeline客户端:
nohup start-beeline.sh &
使用beeline进入hive:
beeline -u jdbc:hive2://192.168.88.100:10000
- 数据预处理
软件:Anaconda Navigator--Jupyter notebook
2.1文件media_index.csv
(1)处理重复数据:
false表示没有重复,true表示有重复,默认从上到下比较,若上一行的数据和下一行的数据重复,则下一行标记为true。
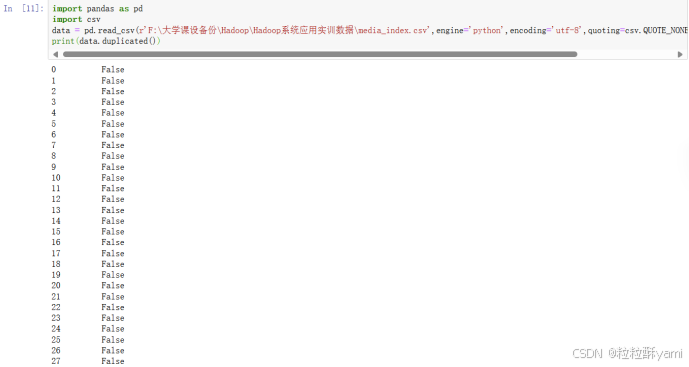
直接查看有多少行重复的数据:

查看源数据文件信息:

删除重复数据:
![]()
重置文件的索引:
![]()
查看索引信息:

删除成功。
(2)其它错误处理:
在导入时,

报错:
![]()
修改:

报错:
![]()
第18行多出几列数据
修改18行。
重新导入:

成功。
最后将列名简化:
terminal_no;phone_no;duration;station_name;origin_time;end_time;owner_code;owner_name;vod_cat_tags;resolution;audio_lang;region;res_name;res_type;vod_title;category_name;program_title;sm_name
2.2文件mediamatch_userevent.csv
(1)处理重复数据:

false表示没有重复,true表示有重复,默认从上到下比较,若上一行的数据和下一行的数据重复,则下一行标记为true。

直接查看有多少行重复的数据:

查看源数据文件信息:

删除重复数据:
![]()
重置文件的索引:
![]()
查看索引信息:

删除成功。
(2)其它错误处理:
无其它错误需要处理。
最后将列名简化:
phone_no;run_name;run_time;owner_name;owner_code;open_time;sm_name
2.3文件mediamatch_usermsg.csv
(1)处理重复数据:

false表示没有重复,true表示有重复,默认从上到下比较,若上一行的数据和下一行的数据重复,则下一行标记为true。
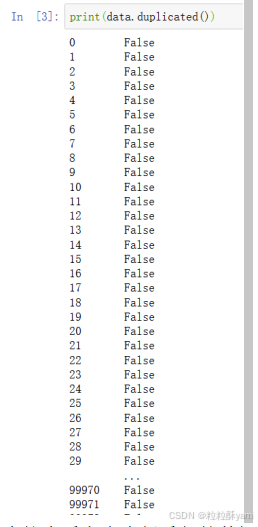
直接查看有多少行重复的数据:

无重复数据需要处理。
(2)其它错误处理:
无其它错误需要处理。
最后将列名简化:
terminal_no;phone_no;sm_name;run_name;sm_code;owner_name;owner_code;run_time;addressoj;open_time;force
2.4文件mmconsume_billevents.csv
(1)处理重复数据:

false表示没有重复,true表示有重复,默认从上到下比较,若上一行的数据和下一行的数据重复,则下一行标记为true

直接查看有多少行重复的数据:

查看源数据文件信息:

删除重复数据:
![]()
重置文件的索引:
![]()
查看索引信息:

删除成功。
(2)其它错误处理:
无其它错误需要处理。
最后将列名简化:
terminal_no;phone_no;fee_code;year_month;owner_name;owner_code;sm_name;should_pay;favour_fee
2.5文件order_index.csv
(1)处理重复数据:

false表示没有重复,true表示有重复,默认从上到下比较,若上一行的数据和下一行的数据重复,则下一行标记为true。

直接查看有多少行重复的数据:

查看源数据文件信息:
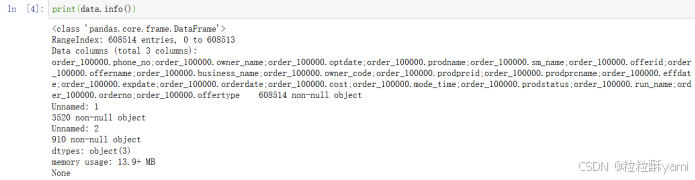
删除重复数据:
![]()
重置文件的索引:
![]()
查看索引信息:

删除成功。
(2)其它错误处理:
无其它错误需要处理。
最后将列名简化:
phone_no;owner_name;optdate;prodname;sm_name;offerid;offername;business_name;owner_code;prodprcid;prodprcname;effdate;expdate;orderdate;cost;mode_time;prodstatus;run_name;orderno;offertype
- 创数据库并使用LOAD语句实现数据的装载
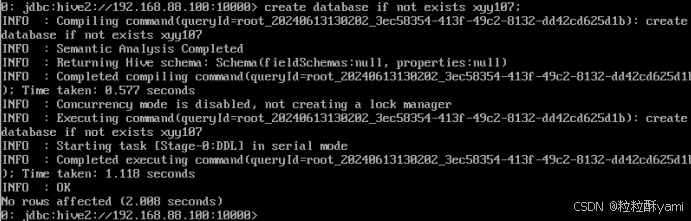
3.1创建数据库xyy107
以自己姓名缩写使用CREATE语句创建广电用户数据库XXX,并使用“IF NOT EXISTS”判断该数据库是否已经存在。
3.2使用LOAD语句实现数据的装载
通过Xftp 7传输Hadoop系统应用实训数据到node01里:
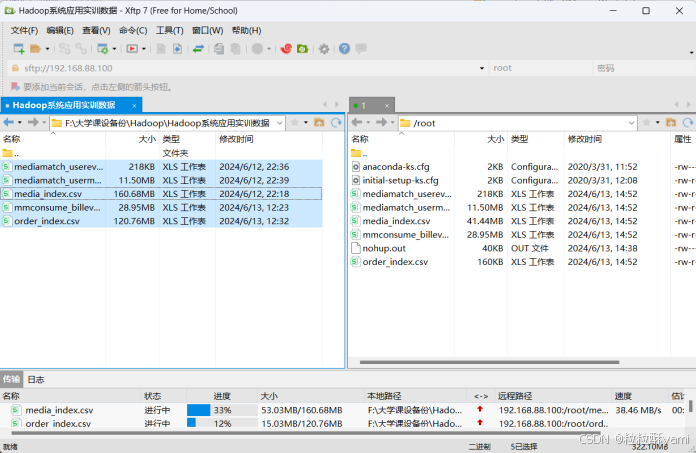
通过MobaXterm软件来辅助操作。
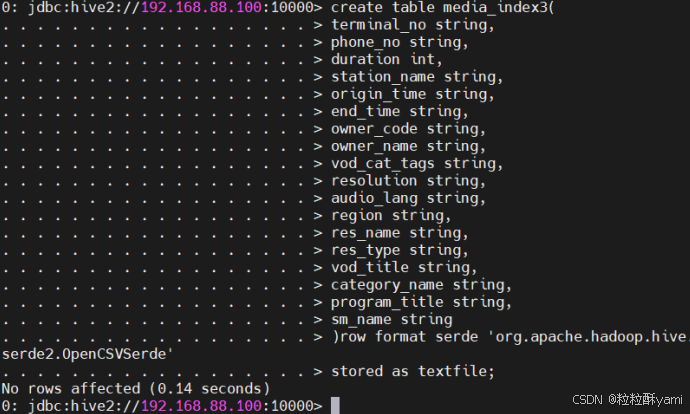
(1)table media_index3

(2)table mediamatch_serevent
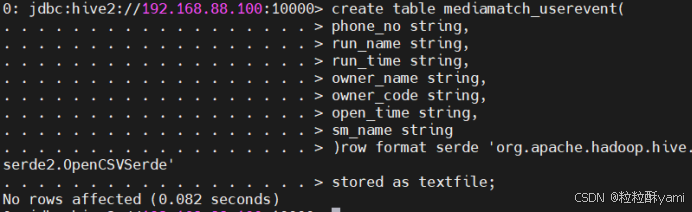

(3)table mediamatch_usermsg
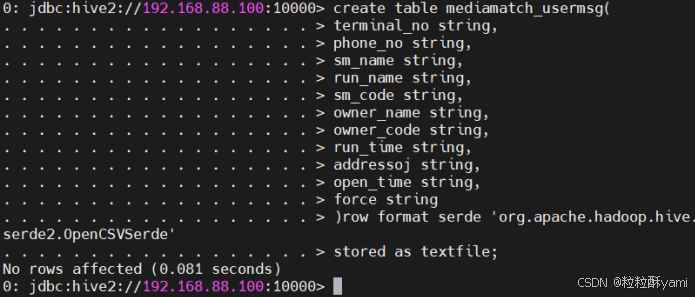

(4)table mmconsume_billevents
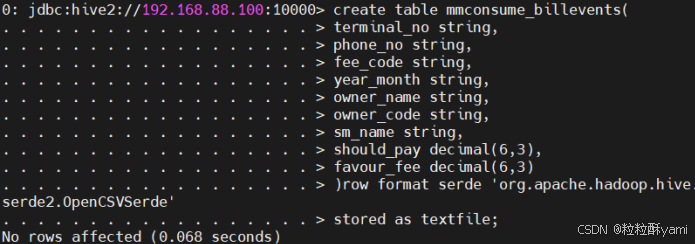
![]()
(5)table order_index
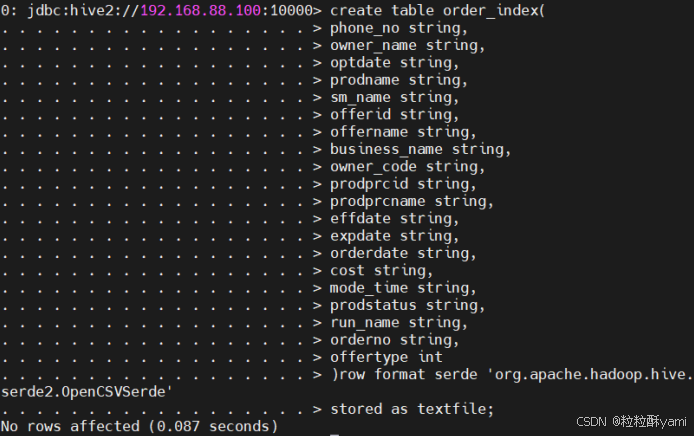
![]()
- 统计与查询
4.1统计用户基本数据表中品牌名称的种类个数
![]()
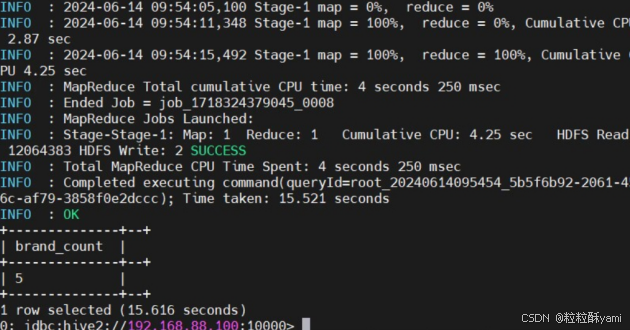
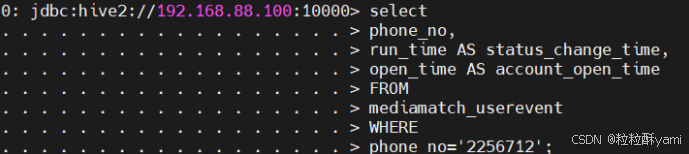
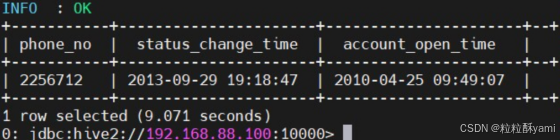
4.2查询用户发生状态变更的时间及开户时间
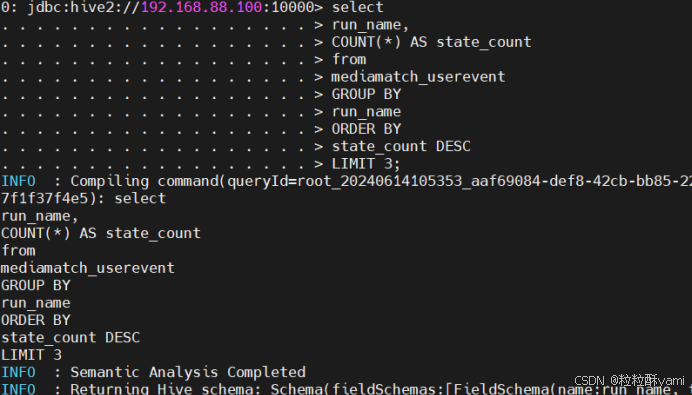
4.3统计用户数最多的3种用户状态
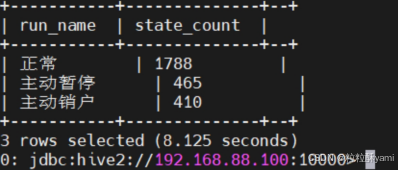
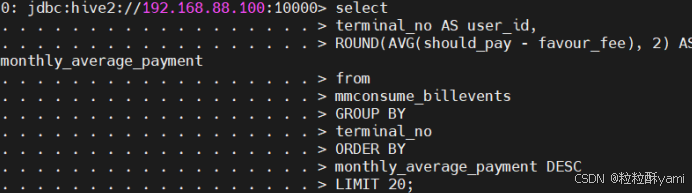
4.4统计2022年度月均账单金额最高的20个用户
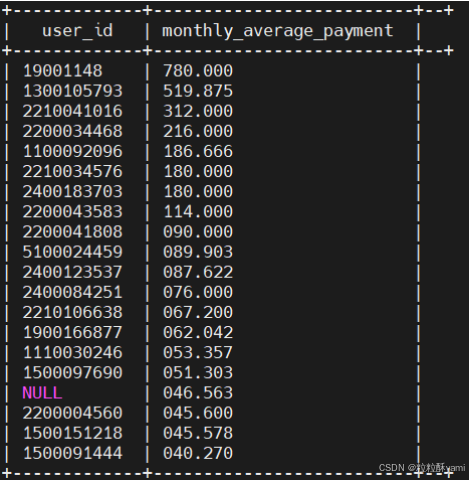
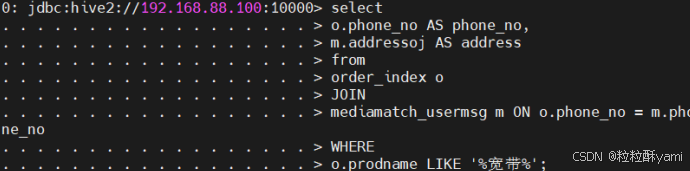
4.5查询用户宽带订单的地址数据
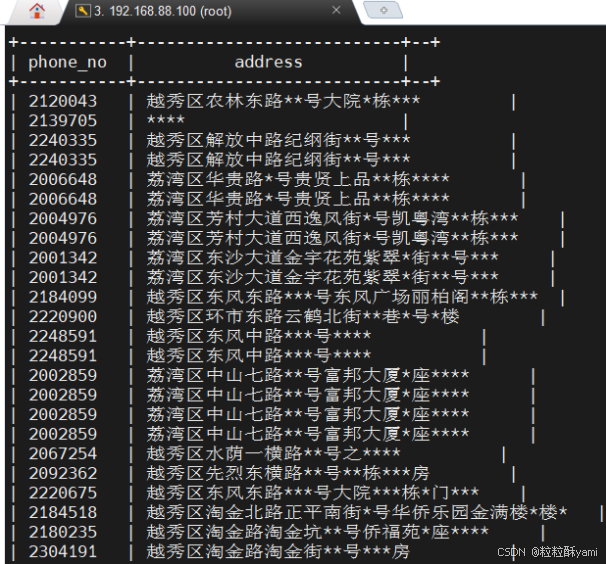
4.6利用抽样查询对用户订购产品的情况进行抽样统计
未完成,思路为
Hive中的抽样查询是借助桶表实现的,抽样查询使用TABLESAMPLE关键字
即语法结构:
SELECT SENTENCE TABLESAMPLE(BUCKET x oUT OF y ON field );
其中x决定了从哪个桶开始抽取;y必须是桶表桶数的倍数或因子,根据y的大小决定抽样的比例。
步骤:
·创建一个桶表order_index_bucket,将订单数据表order_index中的数据按照用户编号phone_no分为4个桶
·向桶表中导入数据
·使用抽样查询,抽取其中一个桶中的数据。
4.7统计出节目类型为直播的频道Top10
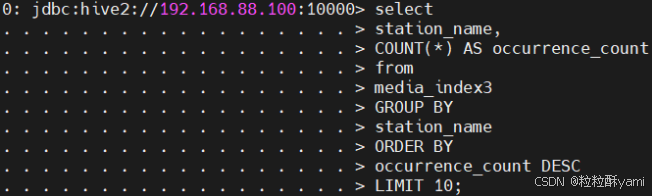
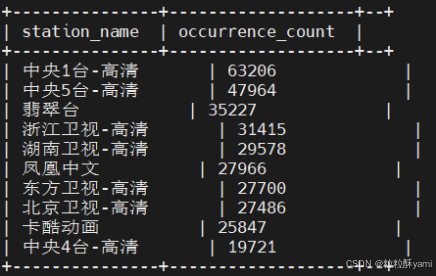
- 总结
(1)遇到的问题:hive报错Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
(2)怎么解决问题:
修改配置文件yarn-site.xml :
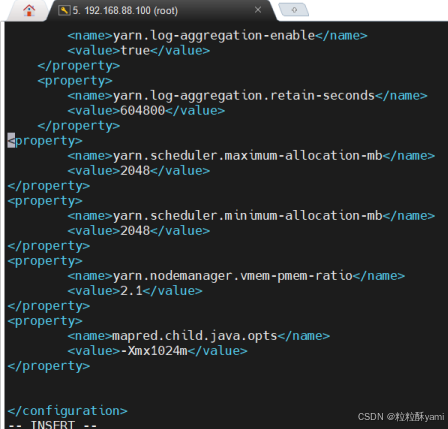
hive下的bin目录下的配置文件hive-config.sh:
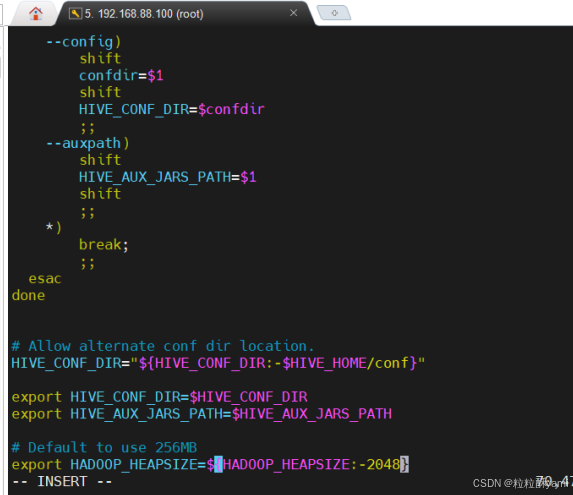
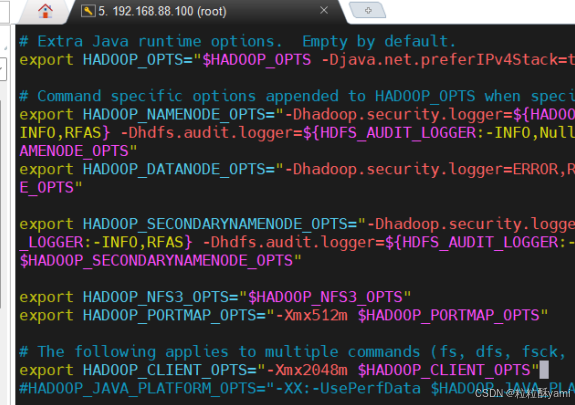
修改配置文件hadoop-env.sh:
(3)有哪些需要改进:本文是用的远程模式Beeline客户端通过HiveServer2服务访问Hive,相比较于bin/hive而言更好,因为企业一般用Beeline,这是本文的优点。但是LOAD语句实现数据的装载时,是本地导进去的,如果将文件上传到HDFS会更好,这是本文需要改进的地方。
(4)不足:只对数据进行了重复数据以及列数的处理,没有清洗特殊线路用户数据、清洗政企用户数据,删除观看时长⼩于20秒和观看时长大于5⼩时的数据,处理无效账单数据...这些可能会对数据的统计和查询造成影响。在以后的学习过程中,本人会加强对数据的清洗、数据预处理多加学习,多加练习,来掌握相关知识。

















 1762
1762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









