









MySQL默认采用InnoDB引擎,而InnoDB引擎下创建的索引默认为B+树结构)
- 能否使用二叉树和红黑树作为索引结构:
答:不能,因为二叉树和红黑树(本质是自平衡二叉树)都有一个共同的特点:
- 大数据量情况下,层级较深,检索速度慢。
所以不采用以上的二叉树作为索引结构
-
以下为b树的结构:
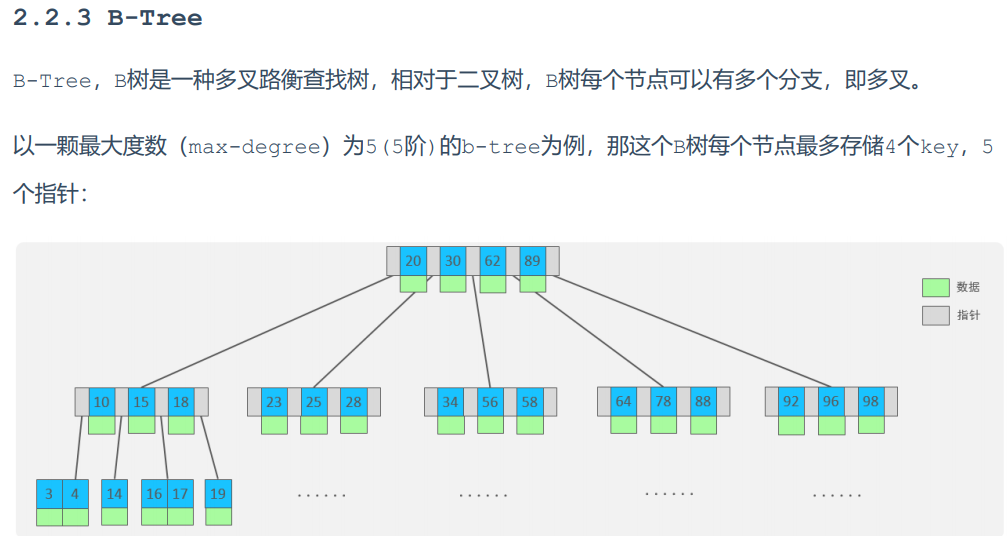
*b树的特点:

*注:树的度数指的是一个节点的子节点的个数
//以下网站是一个数据结构可视化的网站,能帮助理解复杂的数据结构是怎么实现的Data Structure Visualization
-
标准的b+树结构以下为:
- 相对于b树,b+树的数据都存储在了最下面的叶子节点上,上面的节点都只起索引的作用
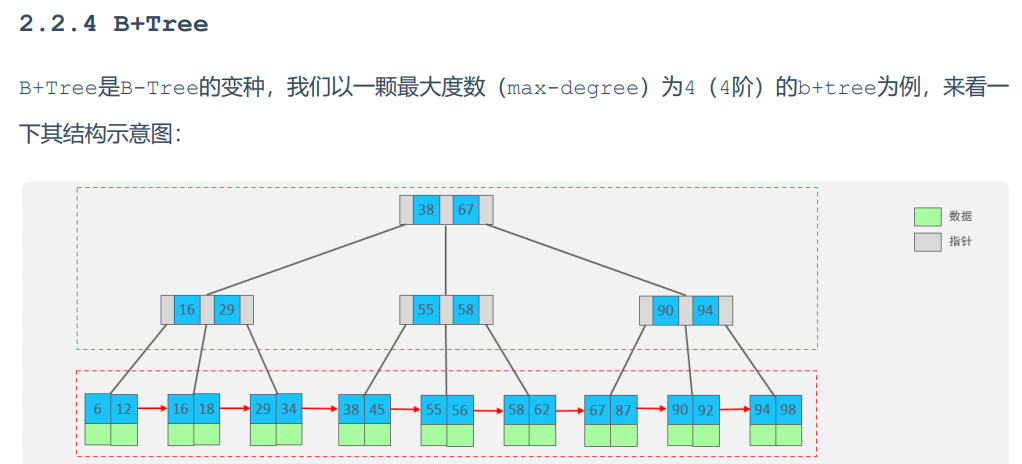
*b+树特点:

-
以下为MySQL优化后的b+树结构:
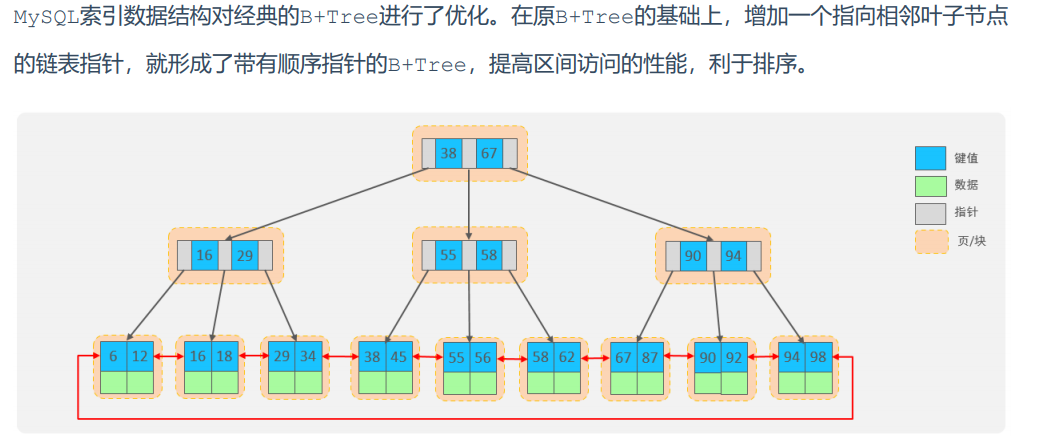
-
以下为Hash索引的结构
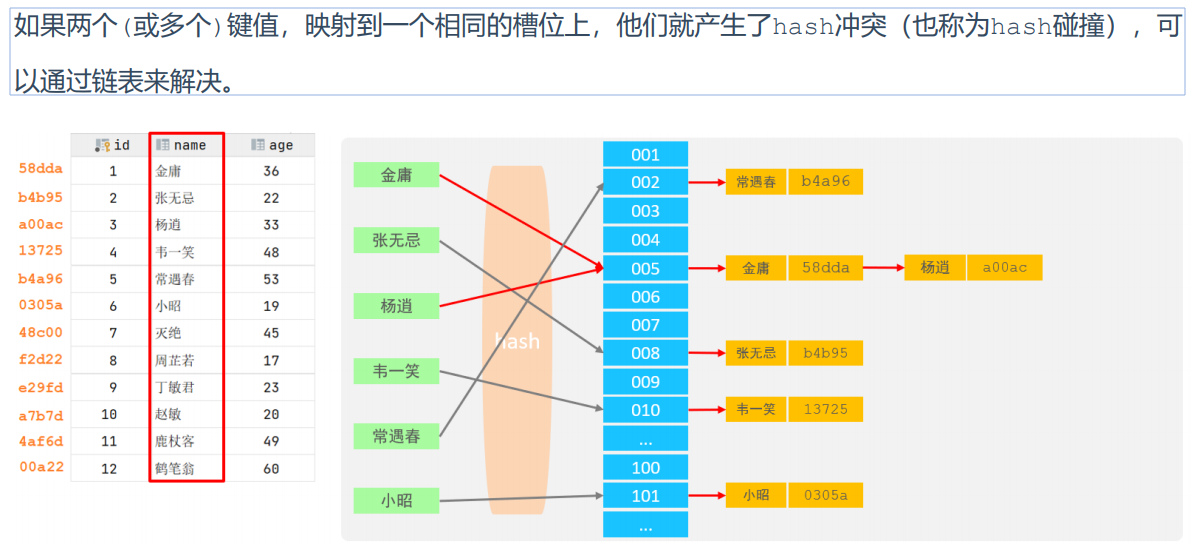
*Hash索引的特点
A. Hash索引只能用于对等比较(=,in),不支持范围查询(between,>,< ,...)
B. 无法利用索引完成排序操作
C. 查询效率高,通常(不存在hash冲突的情况)只需要一次检索就可以了,效率通常要高于B+tree索引
——————————————————————————————————————————
-
常使用的索引结构:
- B+树索引——大部分引擎都支持
- Hsah索引——哈希表实现,不支持范围查询和排序,只能精确匹配索引列。仅支持Memory引擎。
问:为什么InnoDB存储引擎选择使用B+tree索引结构?
A. 相对于二叉树,层级更少,搜索效率高;
B. 对于B-tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针跟着减少,要同样保存大量数据,就只能增加树的高度,导致性能降低;
C. 相对Hash索引,B+tree支持范围匹配及排序操作;
———————————————————————————————————————————



-
以下是InnoDB中的聚集索引和二级索引的结构图:
- id是主键,主键索引即聚集索引 生成的b+树的叶子节点下挂着该行的行数据
- name非聚集索引,即二级索引,索引对应的b+树的叶子节点下挂着name对应的该行主键id
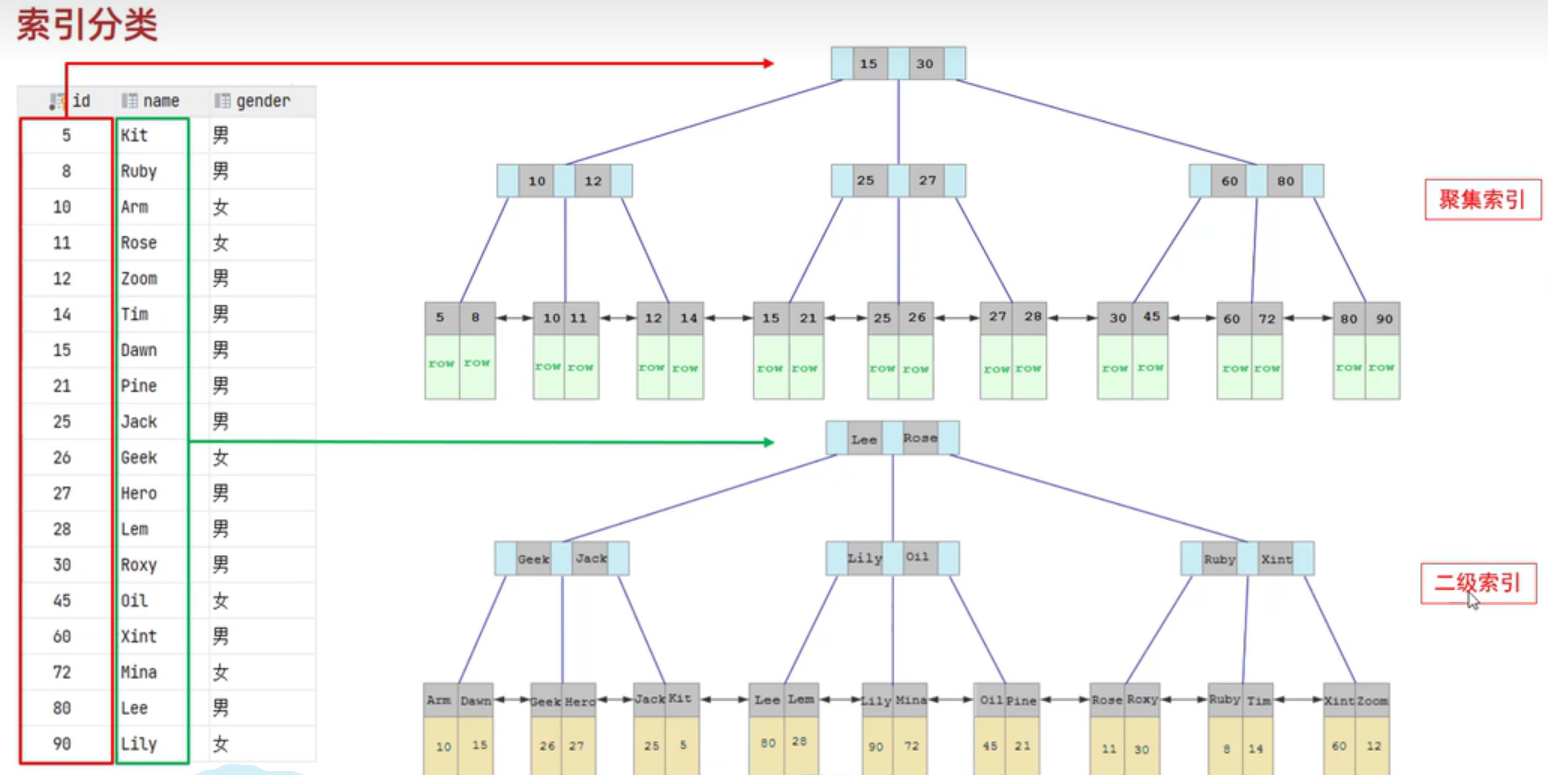
-
以下以一个查询SQL来演示二级索引与聚集索引的回表查询:
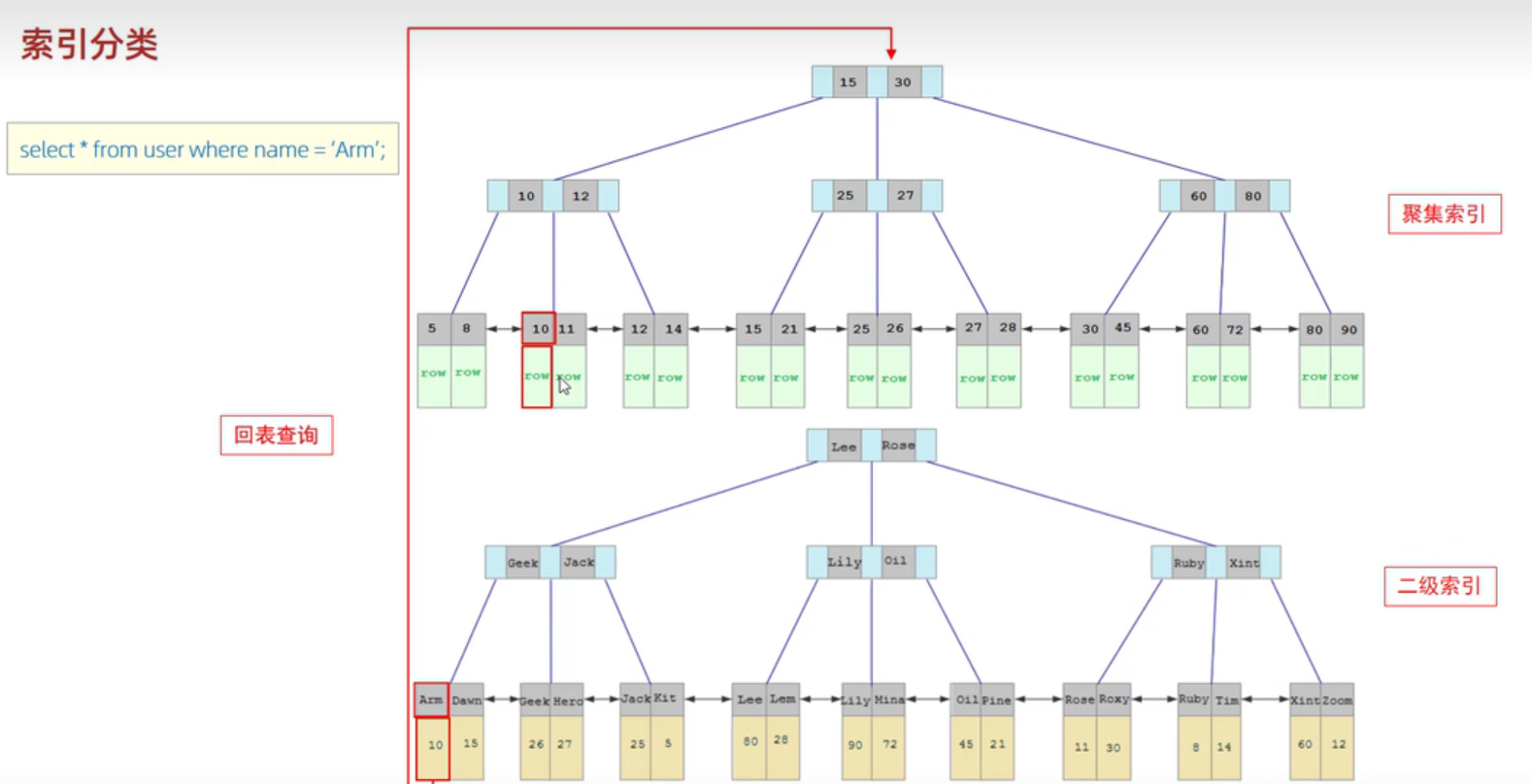
-
索引的使用:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









