






在交货过账时,有时需要做一些增强校验,比如检查库存地、交货数量等增强。
通常我们使用一代增强:
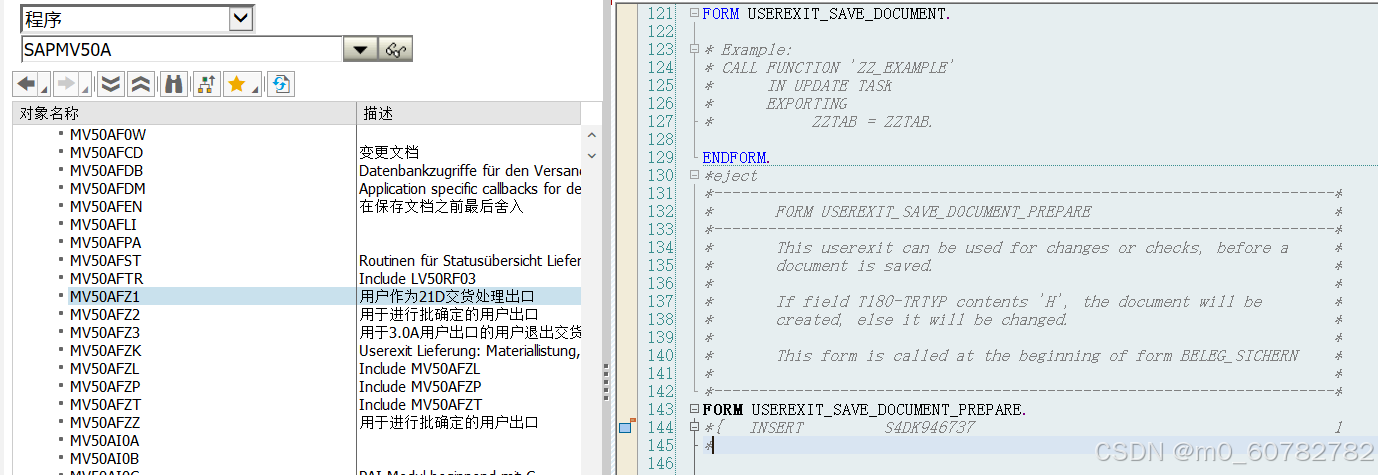
增强点:MV50AFZ1
子程序:FORM USEREXIT_SAVE_DOCUMENT_PREPARE.
或者三代增强:LE_SHP_DELIVERY_PROC
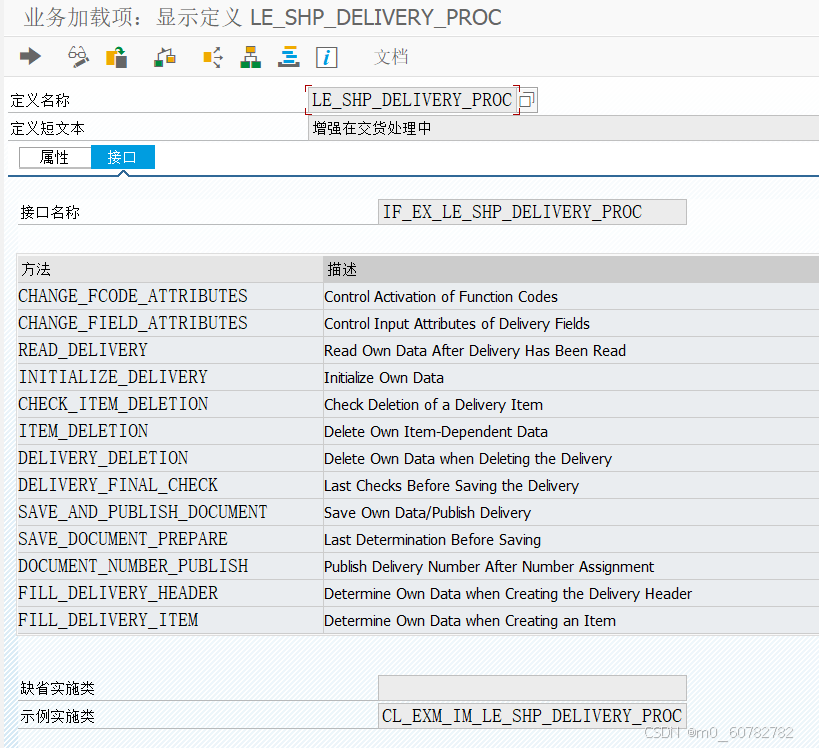
这两代基本满足大部分需求,但他们都没有序列号相关数据的传入。
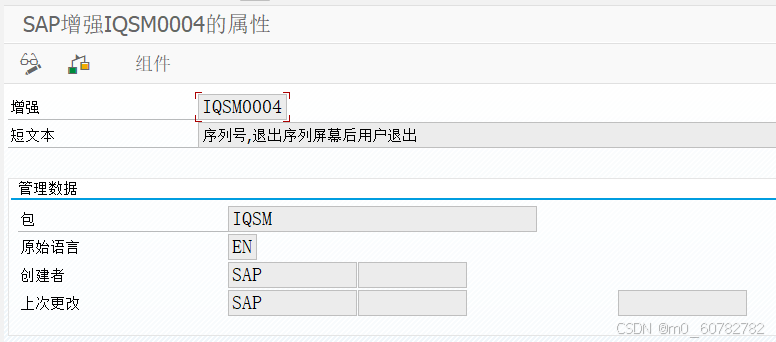
为了对序列号做校验,我们必须要用二代增强:IQSM0004 EXIT_SAPLIPW1_004
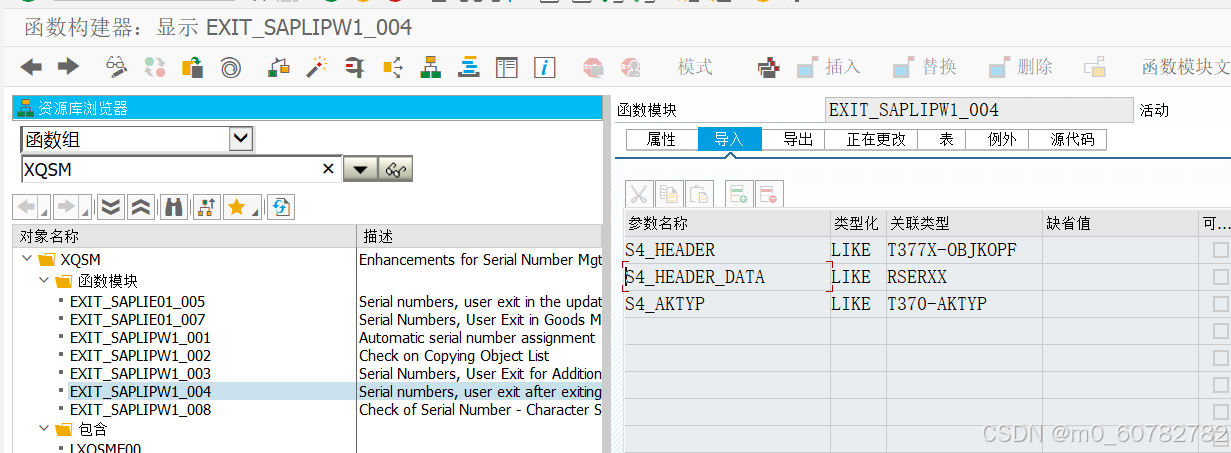
传入参数 S4_HEADER_DATA存储序列号对应的交货单行项目信息。
表 S4_IEQUI 存储所有本次有修改更新变动的序列号信息,包括更新前与更新后.
交货单表头没有传入,用内存指针获得。
XOBJK为序列号维护屏幕pai中存储修改前记录的表。
与S4_IEQUI 对比获知修改序列号部分做判断。
代码需求为:退货交货时,校验序列号末尾为TH标识,且前半段序列号存在于系统。
FIELD-SYMBOLS: <fs_stu> TYPE any,
<fs_lfart> TYPE likp-lfart,
<fs_sernr> TYPE equi-sernr,
<ft_xobjk> TYPE ANY TABLE.
DATA: lv_len TYPE char5,
lv_before TYPE char20,
lv_later TYPE char5.
DATA: r_sernr TYPE RANGE OF equi-sernr.
ASSIGN ('(SAPMV50A)XLIKP') TO <fs_stu>.
IF <fs_stu> IS ASSIGNED.
ASSIGN COMPONENT 'LFART' OF STRUCTURE <fs_stu> TO <fs_lfart>.
ENDIF.
ASSIGN ('(SAPLIPW1)XOBJK[]') TO <ft_xobjk>.
IF <ft_xobjk> IS ASSIGNED.
LOOP AT <ft_xobjk> ASSIGNING FIELD-SYMBOL(<fs_xobjk>).
ASSIGN COMPONENT 'SERNR' OF STRUCTURE <fs_xobjk> TO <fs_sernr>.
APPEND VALUE #( sign = 'I' option = 'EQ' low = <fs_sernr> ) TO r_sernr.
ENDLOOP.
ENDIF.
IF <fs_lfart> = 'ZLR'."退货交货单
DATA(lt_iequi) = s4_iequi[].
DELETE lt_iequi WHERE SERNR NOT IN r_sernr.
IF lt_iequi IS NOT INITIAL.
SELECT equnr, matnr, charge INTO TABLE @DATA(lt_equi)
FROM equi FOR ALL ENTRIES IN @lt_iequi
WHERE matnr = @lt_iequi-matnr
AND charge = @lt_iequi-charge.
SORT lt_equi BY equnr.
ENDIF.
LOOP AT lt_iequi INTO DATA(ls_iequi).
lv_len = strlen( ls_iequi-sernr ) - 2.
lv_before = ls_iequi-sernr+0(lv_len).
lv_later = ls_iequi-sernr+lv_len(2).
IF lv_later NE 'TH'.
CALL FUNCTION 'MESSAGE_STORE'
EXPORTING
arbgb = 'Z001'
msgty = 'E'
msgv1 = ls_iequi-sernr
msgv2 = '退货单序列号必须以TH结尾'
txtnr = '000'.
ENDIF.
READ TABLE lt_equi TRANSPORTING NO FIELDS WITH KEY equnr = lv_before BINARY SEARCH.
IF sy-subrc NE 0.
CALL FUNCTION 'MESSAGE_STORE'
EXPORTING
arbgb = 'Z001'
msgty = 'E'
msgv1 = '序列号'
msgv2 = lv_before
msgv3 = '在系统中不存在'
txtnr = '000'.
ENDIF.
CLEAR: lv_len,lv_before,lv_later.
ENDLOOP.
ENDIF.

















 8230
8230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









