







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前在阿里
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
1、查看运行配置
命令格式:
# ceph daemon {daemon-type}.{id} config show
命令举例:
# ceph daemon osd.0 config show
2、tell子命令格式
使用 tell 的方式适合对整个集群进行设置,使用 * 号进行匹配,就可以对整个集群的角色进行设置。而出现节点异常无法设置时候,只会在命令行当中进行报错,不太便于查找。
命令格式:
# ceph tell {daemon-type}.{daemon id or *} injectargs --{name}={value} [--{name}={value}]
命令举例:
# ceph tell osd.0 injectargs --debug-osd 20 --debug-ms 1
- daemon-type:为要操作的对象类型如osd、mon、mds等。
- daemon id:该对象的名称,osd通常为0、1等,mon为ceph -s显示的名称,这里可以输入*表示全部。
- injectargs:表示参数注入,后面必须跟一个参数,也可以跟多个
3、daemon子命令
使用 daemon 进行设置的方式就是一个个的去设置,这样可以比较好的反馈,此方法是需要在设置的角色所在的主机上进行设置。
命令格式:
# ceph daemon {daemon-type}.{id} config set {name}={value}
命令举例:
# ceph daemon mon.ceph-monitor-1 config set mon_allow_pool_delete false
三、集群操作
命令包含start、restart、status
1、启动所有守护进程
# systemctl start ceph.target
2、按类型启动守护进程
# systemctl restart ceph-mgr.target
# systemctl restart ceph-osd@id
# systemctl restart ceph-mon.target
# systemctl restart ceph-mds.target
# systemctl restart ceph-radosgw.target
3、更新所有节点的配置文件的命令
ceph-deploy --overwrite-conf config push cephnode01 cephnode02 cephnode03
四、添加和删除OSD
1、添加OSD
1、格式化磁盘
ceph-volume lvm zap /dev/sd<id>
2、进入到ceph-deploy执行目录/my-cluster,添加OSD
# ceph-deploy osd create --data /dev/sd<id> $hostname
2、删除OSD
1、调整osd的crush weight为 0
ceph osd crush reweight osd.<ID> 0.0
2、将osd进程stop
systemctl stop ceph-osd@<ID>
3、将osd设置out
ceph osd out <ID>
4、立即执行删除OSD中数据
ceph osd purge osd.<ID> --yes-i-really-mean-it
5、卸载磁盘
umount /var/lib/ceph/osd/ceph-?
五、扩容PG
ceph osd pool set {pool-name} pg_num 128
ceph osd pool set {pool-name} pgp_num 128
注:
1、扩容大小取跟它接近的2的N次方
2、在更改pool的PG数量时,需同时更改PGP的数量。PGP是为了管理placement而存在的专门的PG,它和PG的数量应该保持一致。如果你增加pool的pg_num,就需要同时增加pgp_num,保持它们大小一致,这样集群才能正常rebalancing。
六、Pool操作
列出存储池
ceph osd lspools
创建存储池
命令格式:
# ceph osd pool create {pool-name} {pg-num} [{pgp-num}]
命令举例:
# ceph osd pool create rbd 32 32
设置存储池配额
命令格式:
# ceph osd pool set-quota {pool-name} [max\_objects {obj-count}] [max\_bytes {bytes}]
命令举例:
# ceph osd pool set-quota rbd max\_objects 10000
删除存储池
#在ceph.conf配置文件中添加如下内容:
[mon]
mon allow pool delete = true
#重启ceph-mon服务
systemctl restart ceph-mon.target
#执行删除pool命令
ceph osd pool delete {pool-name} [{pool-name} --yes-i-really-really-mean-it
命令举例:
ceph osd pool delete kube kube --yes-i-really-really-mean-it
重命名存储池
ceph osd pool rename {current-pool-name} {new-pool-name}
查看存储池统计信息
rados df
给存储池做快照
ceph osd pool mksnap {pool-name} {snap-name}
删除存储池的快照
ceph osd pool rmsnap {pool-name} {snap-name}
获取存储池选项值
ceph osd pool get {pool-name} {key}
调整存储池选项值
ceph osd pool set {pool-name} {key} {value}
size:设置存储池中的对象副本数,详情参见设置对象副本数。仅适用于副本存储池。
min_size:设置 I/O 需要的最小副本数,详情参见设置对象副本数。仅适用于副本存储池。
pg_num:计算数据分布时的有效 PG 数。只能大于当前 PG 数。
pgp_num:计算数据分布时使用的有效 PGP 数量。小于等于存储池的 PG 数。
hashpspool:给指定存储池设置/取消 HASHPSPOOL 标志。
target_max_bytes:达到 max_bytes 阀值时会触发 Ceph 冲洗或驱逐对象。
target_max_objects:达到 max_objects 阀值时会触发 Ceph 冲洗或驱逐对象。
scrub_min_interval:在负载低时,洗刷存储池的最小间隔秒数。如果是 0 ,就按照配置文件里的 osd_scrub_min_interval 。
scrub_max_interval:不管集群负载如何,都要洗刷存储池的最大间隔秒数。如果是 0 ,就按照配置文件里的 osd_scrub_max_interval 。
deep_scrub_interval:“深度”洗刷存储池的间隔秒数。如果是 0 ,就按照配置文件里的 osd_deep_scrub_interval 。
获取对象副本数
ceph osd dump | grep 'replicated size'
七、用户管理
Ceph 把数据以对象的形式存于各存储池中。Ceph 用户必须具有访问存储池的权限才能够读写数据。另外,Ceph 用户必须具有执行权限才能够使用 Ceph 的管理命令。
1、查看用户信息
查看所有用户信息
# ceph auth list
获取所有用户的key与权限相关信息
# ceph auth get client.admin
如果只需要某个用户的key信息,可以使用pring-key子命令
# ceph auth print-key client.admin
2、添加用户
# ceph auth add client.john mon 'allow r' osd 'allow rw pool=liverpool'
# ceph auth get-or-create client.paul mon 'allow r' osd 'allow rw pool=liverpool'
# ceph auth get-or-create client.george mon 'allow r' osd 'allow rw pool=liverpool' -o george.keyring
# ceph auth get-or-create-key client.ringo mon 'allow r' osd 'allow rw pool=liverpool' -o ringo.key
3、修改用户权限
# ceph auth caps client.john mon 'allow r' osd 'allow rw pool=liverpool'
# ceph auth caps client.paul mon 'allow rw' osd 'allow rwx pool=liverpool'
# ceph auth caps client.brian-manager mon 'allow *' osd 'allow *'
# ceph auth caps client.ringo mon ' ' osd ' '
4、删除用户
# ceph auth del {TYPE}.{ID}
**先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前在阿里**
**深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
**因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。**

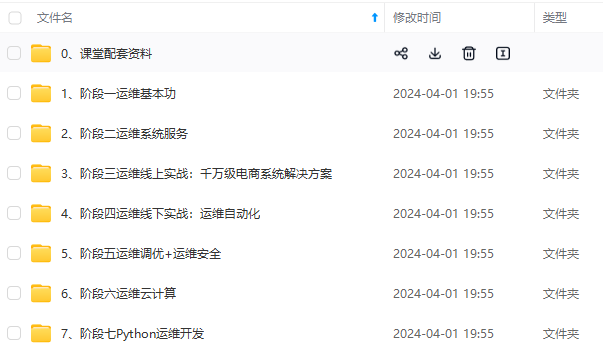
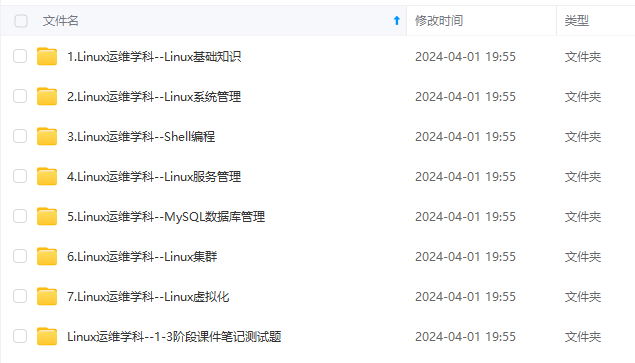
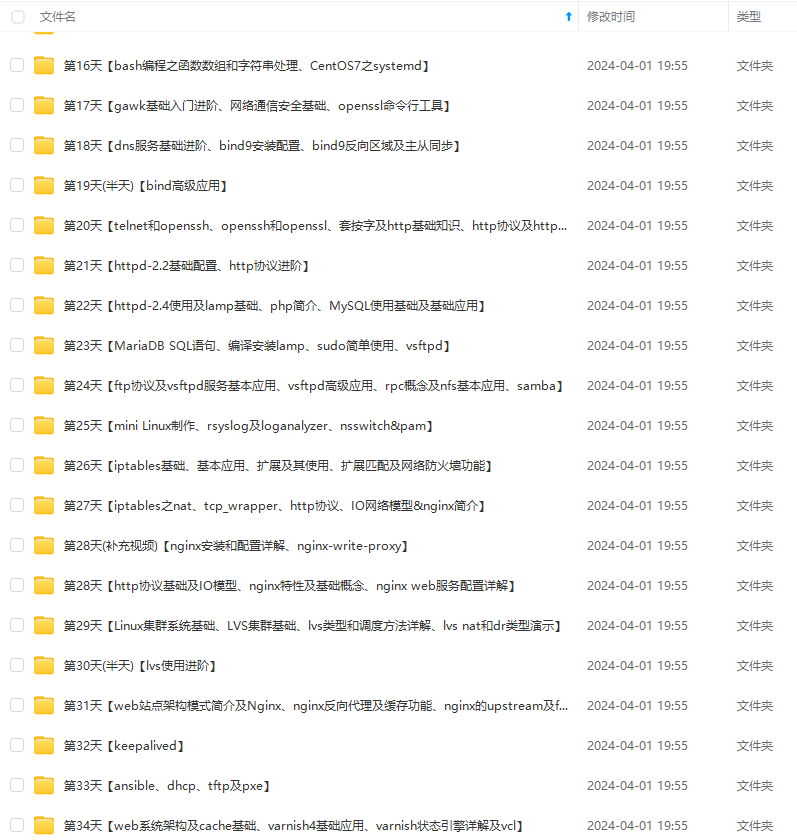
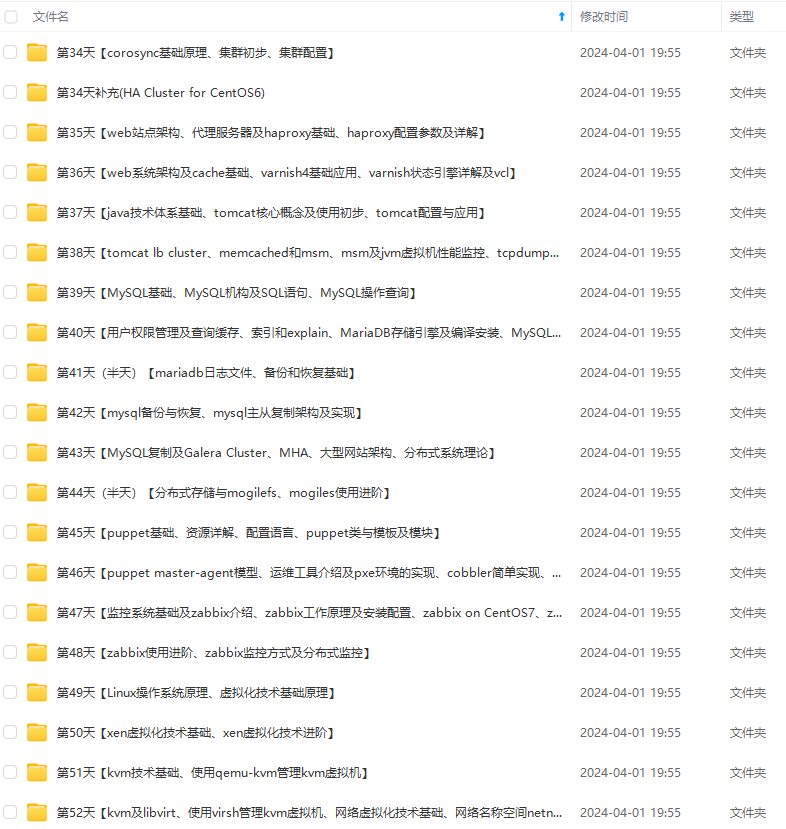
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化的资料的朋友,可以点击这里获取!](https://bbs.youkuaiyun.com/forums/4f45ff00ff254613a03fab5e56a57acb)**
94349644)]
[外链图片转存中...(img-Ev7u2Ny6-1715494349644)]
[外链图片转存中...(img-fkeGHZMR-1715494349645)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化的资料的朋友,可以点击这里获取!](https://bbs.youkuaiyun.com/forums/4f45ff00ff254613a03fab5e56a57acb)**

















 512
512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









