







在之前的文章中,我们探讨了图像分类、文本生成和强化学习等任务。本文将聚焦于时间序列预测问题,使用 PyTorch 实现一个简单的 LSTM 模型,预测未来时间步的数值。通过这个例子,读者将掌握处理序列数据的基础方法。
一、时间序列预测基础
时间序列是按时间顺序排列的数据点序列,广泛存在于股票价格、气象数据、传感器记录等领域。预测未来时间步的值是时间序列分析的核心任务之一。
1. LSTM 模型简介
长短期记忆网络(LSTM)是一种特殊的循环神经网络(RNN),通过门控机制解决传统 RNN 的梯度消失问题,擅长捕捉长期依赖关系。其核心结构包括:
-
遗忘门:决定丢弃哪些信息。
-
输入门:更新细胞状态。
-
输出门:决定输出的隐藏状态。
2. 数据预处理
时间序列预测通常需要将数据划分为滑动窗口样本。例如,用过去 7 天的数据预测第 8 天的值。
二、时间序列预测实战
我们将使用合成的正弦波数据,训练一个 LSTM 模型预测未来值。
1. 实现步骤
-
生成并预处理数据。
-
定义 LSTM 模型。
-
训练模型。
-
预测并可视化结果。
2. 代码实现
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
# 生成正弦波数据
def generate_sin_data(seq_length=1000):
x = np.linspace(0, 50, seq_length)
y = np.sin(x) * 0.5 + 0.5 # 归一化到 [0,1]
return y
# 数据预处理(滑动窗口)
def create_dataset(data, window_size=20):
X, Y = [], []
for i in range(len(data)-window_size):
X.append(data[i:i+window_size])
Y.append(data[i+window_size])
return np.array(X), np.array(Y)
# 参数设置
SEQ_LENGTH = 1000
WINDOW_SIZE = 20
BATCH_SIZE = 32
EPOCHS = 100
# 生成数据
data = generate_sin_data(SEQ_LENGTH)
X, Y = create_dataset(data, WINDOW_SIZE)
# 划分训练集和测试集
split = int(0.8 * len(X))
X_train, X_test = X[:split], X[split:]
Y_train, Y_test = Y[:split], Y[split:]
# 转换为PyTorch张量
X_train = torch.FloatTensor(X_train).unsqueeze(-1) # [样本数, 窗口大小, 特征数]
Y_train = torch.FloatTensor(Y_train)
X_test = torch.FloatTensor(X_test).unsqueeze(-1)
Y_test = torch.FloatTensor(Y_test)
# 定义LSTM模型
class LSTMPredictor(nn.Module):
def __init__(self, input_size=1, hidden_size=50, output_size=1):
super().__init__()
self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
self.linear = nn.Linear(hidden_size, output_size)
def forward(self, x):
x, _ = self.lstm(x) # 输出形状: [batch, seq_len, hidden_size]
x = x[:, -1, :] # 取最后一个时间步的输出
return self.linear(x)
# 初始化模型、损失函数和优化器
model = LSTMPredictor()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练模型
train_losses = []
for epoch in range(EPOCHS):
model.train()
optimizer.zero_grad()
outputs = model(X_train)
loss = criterion(outputs.squeeze(), Y_train)
loss.backward()
optimizer.step()
train_losses.append(loss.item())
if (epoch+1) % 10 == 0:
print(f'Epoch [{epoch+1}/{EPOCHS}], Loss: {loss.item():.4f}')
# 预测测试集
model.eval()
with torch.no_grad():
test_pred = model(X_test).squeeze().numpy()
# 可视化结果
plt.figure(figsize=(12, 6))
plt.subplot(1,2,1)
plt.plot(train_losses)
plt.title("Training Loss Curve")
plt.xlabel("Epoch")
plt.ylabel("MSE Loss")
plt.subplot(1,2,2)
plt.plot(Y_test.numpy(), label="True Value")
plt.plot(test_pred, label="Prediction")
plt.title("Test Prediction")
plt.legend()
plt.show()三、代码解析
-
数据生成:
-
使用
generate_sin_data生成包含 1000 个点的正弦波。 -
通过
create_dataset创建滑动窗口样本(用前 20 个点预测第 21 个点)。
-
-
模型结构:
-
LSTMPredictor包含一个 LSTM 层和一个全连接层。 -
LSTM 的
hidden_size设置为 50,可根据数据复杂度调整。
-
-
训练过程:
-
使用均方误差(MSE)作为损失函数。
-
Adam 优化器进行参数更新。
-
训练 100 个 epoch,每 10 个 epoch 打印损失值。
-
-
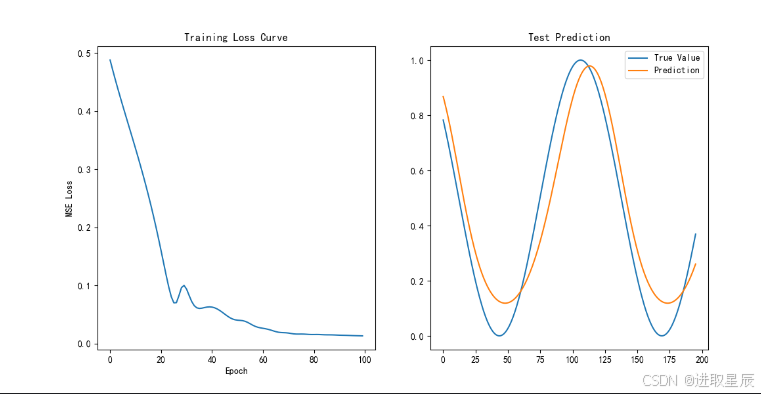
结果可视化:
-
左图显示训练损失下降曲线。
-
右图对比测试集的真实值和预测值。
-
四、运行结果
运行代码后,你将看到:
-
训练损失从约 0.1 逐渐下降至 0.001 以下。
-
测试集的预测曲线(橙色)与真实曲线(蓝色)基本重合。
五、改进建议
-
增加特征维度:除了历史值,可加入温度、湿度等多维特征。
-
使用更复杂模型:如堆叠多层 LSTM 或结合 CNN。
-
调整超参数:尝试不同的
hidden_size或WINDOW_SIZE。 -
使用真实数据:替换为股票价格或电力负荷数据。
六、总结
本文介绍了时间序列预测的基本概念,并使用 PyTorch 实现了一个简单的 LSTM 预测模型。通过这个例子,我们学习了如何处理序列数据、构建 LSTM 模型以及进行训练和预测。
在下一篇文章中,我们将探讨生成对抗网络(GAN)在图像生成中的应用。敬请期待!
代码实例说明:
-
可直接在 Python 3.7+ 环境中运行,依赖库:
torch,numpy,matplotlib。 -
GPU 加速:修改
model = model.to('cuda')并转移数据到 GPU。 -
调整
WINDOW_SIZE可改变历史数据长度,hidden_size影响模型容量。
希望这篇文章能帮助你入门时间序列预测!如有问题,欢迎在评论区讨论。

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









