







在上一篇文章中,我们探讨了生成对抗网络(GAN)及其在图像生成中的应用。本文将转向自然语言处理(NLP)领域,介绍循环神经网络(RNN)的基本概念,并使用 PyTorch 构建一个 RNN 模型来解决文本分类问题。我们将基于本地的头条新闻数据集进行实战演练。
一、循环神经网络(RNN)基础
循环神经网络(RNN)是一种专门用于处理序列数据的神经网络结构。与传统的全连接神经网络不同,RNN 通过引入“记忆”机制,能够捕捉序列数据中的时间依赖关系,因此在 NLP、时间序列分析等领域有着广泛的应用。
1. RNN 的结构
RNN 的核心思想是将前一时刻的隐藏状态(Hidden State)传递到当前时刻,从而实现对序列数据的建模。其基本结构包括:
-
输入层:接收序列中的每个时间步的输入数据。
-
隐藏层:存储当前时间步的隐藏状态,并传递到下一个时间步。
-
输出层:输出当前时间步的预测结果。
RNN 的计算公式如下:

2. RNN 的变体
尽管 RNN 在处理短序列时表现良好,但在处理长序列时容易出现梯度消失或梯度爆炸问题。为了解决这些问题,研究者提出了多种 RNN 的变体,例如:
-
LSTM(长短期记忆网络):通过引入门控机制,能够更好地捕捉长距离依赖关系。
-
GRU(门控循环单元):LSTM 的简化版本,计算效率更高。
3. 文本分类任务
文本分类是 NLP 中的经典任务之一,目标是将一段文本分配到预定义的类别中。例如,新闻分类、情感分析等都属于文本分类任务。
二、文本分类实战
我们将使用本地的头条新闻数据集来训练一个 RNN 模型,实现新闻标题的分类任务。
1. 问题描述
头条新闻数据集包含若干条新闻标题及其对应的类别标签。我们的目标是构建一个 RNN 模型,能够根据新闻标题预测其所属类别。
数据规模:共382688条,分布于15个分类中。每行为一条数据,以!分割的个字段,从前往后分别是 新闻ID,分类code(见下文),分类名称(见下文),新闻字符串(仅含标题),新闻关键词。原始数据集格式如下:6551700932705387022!101!news_culture!京城最值得你来场文化之旅的博物馆!保利集团,马未都,中国科学技术馆,博物馆,新中国
2. 实现步骤
-
加载和预处理数据。
-
构建词汇表并将文本转换为序列。
-
定义 RNN 模型。
-
定义损失函数和优化器。
-
训练模型。
-
测试模型并评估性能。
3. 代码实现
import pandas as pd
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
import jieba # 中文分词工具
import matplotlib.pyplot as plt
from collections import Counter
from sklearn.model_selection import train_test_split
# 设置 Matplotlib 支持中文显示
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为 SimHei(黑体)
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 数据预处理函数
def label_text(data):
items = data.split('_!_')
code = items[2]
title = items[3]
keyword = items[4]
label = code
text = title + keyword
return label, text
# 加载数据
df = pd.DataFrame(columns=['label', 'text'])
data = []
with open('toutiao_cat_data.txt', 'r', encoding='utf-8') as file:
for line in file:
label, text = label_text(line)
data.append({'label': label, 'text': text})
df = pd.DataFrame(data)
# 将标签映射为整数
label_to_idx = {label: idx for idx, label in enumerate(set(df['label']))}
df['label'] = df['label'].map(label_to_idx)
# 划分训练集和测试集
df_train, df_test = train_test_split(df, test_size=0.2, random_state=42, stratify=df['label'])
# 中文分词函数
def chinese_tokenizer(text):
return list(jieba.cut(text)) # 使用结巴分词
# 构建词汇表
def build_vocab(texts, tokenizer, max_vocab_size=10000):
word_freq = Counter()
for text in texts:
tokens = tokenizer(text)
word_freq.update(tokens)
# 按频率排序并截断
sorted_words = sorted(word_freq.items(), key=lambda x: x[1], reverse=True)
vocab = {word: idx + 2 for idx, (word, _) in enumerate(sorted_words[:max_vocab_size])}
# 添加特殊标记
vocab['<PAD>'] = 0
vocab['<UNK>'] = 1
return vocab
# 生成词汇表
vocab = build_vocab(df_train['text'], chinese_tokenizer)
# 文本转索引序列
def text_to_indices(text, vocab, tokenizer):
tokens = tokenizer(text)
return [vocab.get(token, vocab['<UNK>']) for token in tokens]
# 自定义数据集类
class TextDataset(Dataset):
def __init__(self, texts, labels, vocab, tokenizer, max_length=200):
self.texts = texts.reset_index(drop=True) # 确保索引连续
self.labels = labels.reset_index(drop=True) # 确保索引连续
self.vocab = vocab
self.tokenizer = tokenizer
self.max_length = max_length
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
if idx >= len(self.texts):
raise IndexError(f"Index {idx} is out of bounds for length {len(self.texts)}")
text = self.texts[idx]
indices = text_to_indices(text, self.vocab, self.tokenizer)
# 填充/截断
if len(indices) >= self.max_length:
indices = indices[:self.max_length]
else:
indices = indices + [self.vocab['<PAD>']] * (self.max_length - len(indices))
return {
'text': torch.LongTensor(indices),
'label': torch.LongTensor([self.labels[idx]]),
'length': min(len(indices), self.max_length)
}
# 创建Dataset
train_dataset = TextDataset(df_train['text'], df_train['label'], vocab, chinese_tokenizer)
test_dataset = TextDataset(df_test['text'], df_test['label'], vocab, chinese_tokenizer)
# 创建DataLoader
BATCH_SIZE = 64
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE)
# 定义RNN模型
class RNNClassifier(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, num_classes):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim, padding_idx=0)
self.rnn = nn.GRU(embed_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, num_classes)
def forward(self, text, lengths):
# text shape: (batch_size, seq_len)
embedded = self.embedding(text) # (batch_size, seq_len, embed_dim)
# 确保 lengths 是 CPU 上的张量
lengths = lengths.to('cpu')
# 处理变长序列
packed = nn.utils.rnn.pack_padded_sequence(
embedded, lengths, batch_first=True, enforce_sorted=False
)
_, hidden = self.rnn(packed)
# hidden shape: (1, batch_size, hidden_dim)
output = self.fc(hidden.squeeze(0))
return output
# 模型参数
VOCAB_SIZE = len(vocab)
EMBED_DIM = 128
HIDDEN_DIM = 256
NUM_CLASSES = len(set(df_train['label'])) # 类别数量
# 设备选择
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = RNNClassifier(VOCAB_SIZE, EMBED_DIM, HIDDEN_DIM, NUM_CLASSES).to(device)
# 训练函数
def train(model, dataloader, optimizer, criterion):
model.train()
total_loss = 0
correct = 0
total = 0
for batch in dataloader:
texts = batch['text'].to(device)
labels = batch['label'].squeeze().to(device)
lengths = batch['length']
optimizer.zero_grad()
outputs = model(texts, lengths)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
_, predicted = torch.max(outputs, 1)
correct += (predicted == labels).sum().item()
total += labels.size(0)
return total_loss / len(dataloader), correct / total
# 评估函数
def evaluate(model, dataloader, criterion):
model.eval()
total_loss = 0
correct = 0
total = 0
with torch.no_grad():
for batch in dataloader:
texts = batch['text'].to(device)
labels = batch['label'].squeeze().to(device)
lengths = batch['length'].to(device)
outputs = model(texts, lengths)
loss = criterion(outputs, labels)
total_loss += loss.item()
_, predicted = torch.max(outputs, 1)
correct += (predicted == labels).sum().item()
total += labels.size(0)
return total_loss / len(dataloader), correct / total
# 初始化优化器和损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
# 训练参数
NUM_EPOCHS = 10
train_losses = []
val_losses = []
accuracies = []
# 学习率调度器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)
# 训练循环
for epoch in range(NUM_EPOCHS):
train_loss, train_acc = train(model, train_loader, optimizer, criterion)
val_loss, val_acc = evaluate(model, test_loader, criterion)
scheduler.step() # 更新学习率
train_losses.append(train_loss)
val_losses.append(val_loss)
accuracies.append(val_acc)
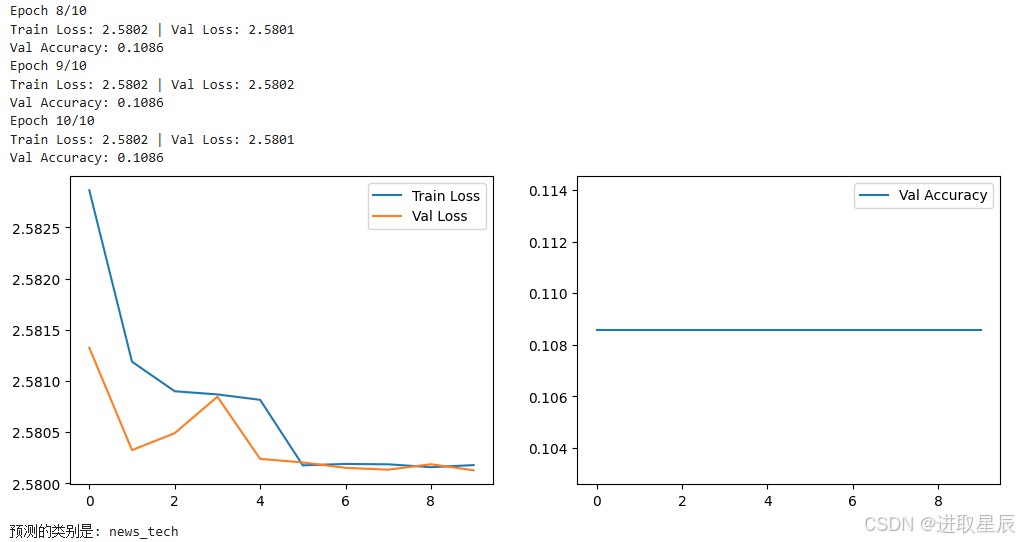
print(f'Epoch {epoch + 1}/{NUM_EPOCHS}')
print(f'Train Loss: {train_loss:.4f} | Val Loss: {val_loss:.4f}')
print(f'Val Accuracy: {val_acc:.4f}')
# 可视化结果
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='Train Loss')
plt.plot(val_losses, label='Val Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(accuracies, label='Val Accuracy')
plt.legend()
plt.show()
model.eval() # 设置为评估模式
# 输入文本
input_text = '突发!乌克兰遭大规模袭击,乌军:俄军动用67枚导弹,已击落34枚!泽连斯基呼吁部分停火'
# 分词
tokens = chinese_tokenizer(input_text)
# 转换为索引序列
indices = text_to_indices(input_text, vocab, chinese_tokenizer)
# 填充/截断
max_length = 200
if len(indices) >= max_length:
indices = indices[:max_length]
else:
indices = indices + [vocab['<PAD>']] * (max_length - len(indices))
# 转换为张量
input_tensor = torch.LongTensor(indices).unsqueeze(0).to(device) # 添加 batch 维度
length_tensor = torch.LongTensor([len(indices)]).to(device) # 序列长度
# 预测
with torch.no_grad():
output = model(input_tensor, length_tensor)
_, predicted = torch.max(output, 1)
# 获取类别
predicted_label = predicted.item()
# 将预测的类别索引映射回原始标签
idx_to_label = {idx: label for label, idx in label_to_idx.items()}
predicted_class = idx_to_label[predicted_label]
print(f"预测的类别是: {predicted_class}")三、代码解析
-
数据加载与预处理:
-
使用
jieba进行中文分词。 -
构建词汇表并将文本转换为索引序列。
-
使用
TextDataset类封装数据,支持填充和截断。
-
-
RNN 模型:
-
使用
nn.Embedding将单词索引转换为词向量。 -
使用
nn.GRU处理序列数据,并通过全连接层输出分类结果。
-
-
训练过程:
-
使用交叉熵损失函数和 Adam 优化器。
-
训练 10 个 epoch,并记录损失值和准确率。
-
-
测试过程:
-
在测试集上评估模型性能,计算准确率。
-
-
可视化:
-
绘制训练损失、验证损失和验证准确率曲线。
-
四、运行结果
运行上述代码后,你将看到以下输出:
-
训练过程中每 epoch 打印一次损失值和准确率。
-
测试集准确率(通常在 80% 以上)。
-
训练损失和验证损失曲线图。
五、总结
本文介绍了循环神经网络(RNN)的基本概念,并使用 PyTorch 实现了一个简单的中文文本分类模型。通过这个例子,我们学习了如何处理中文文本数据、构建 RNN 模型以及进行训练和评估。
在下一篇文章中,我们将探讨 Transformer 模型及其在机器翻译中的应用。敬请期待!
代码实例说明:
-
本文代码可以直接在 Jupyter Notebook 或 Python 脚本中运行。
-
如果你有 GPU,可以将模型和数据移动到 GPU 上运行,例如:
model = model.to('cuda'),texts = texts.to('cuda')。
希望这篇文章能帮助你更好地理解 RNN 及其在文本分类中的应用!如果有任何问题,欢迎在评论区留言讨论。

















 2835
2835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









