







 文章讲述了在使用DA-CLIP进行训练时遇到的错误,涉及到文本张量维度不匹配问题,尤其是在编码阶段。作者发现可能的原因是数据集加载时文本处理的长度设置与模型期望不符,且提到可能与预训练模型的使用和datasetloader有关。
文章讲述了在使用DA-CLIP进行训练时遇到的错误,涉及到文本张量维度不匹配问题,尤其是在编码阶段。作者发现可能的原因是数据集加载时文本处理的长度设置与模型期望不符,且提到可能与预训练模型的使用和datasetloader有关。
背景
【DA-CLIP】使用train.py训练 http://t.csdnimg.cn/KLxMf
http://t.csdnimg.cn/KLxMf
结论是要设置--da为true
train文件夹下的main.py文件,主函数参数是命令行参数,这样没办法进行调试。感觉修改为非命令行的方式为了测试比较复杂,所以以下都是print出中间过程来查报错点 。
把--name命令行参数注释方便测试,有相关代码生成时间戳而不会报实验名重复问题。
上两个是自动生成的log文件夹名
报错
输出包含架构和参数总共12000字,为方便阅读已省略部分,自己训练不想看可以在main.py把这两玩意注释掉
logging.info(f"{str(model)}")logging.info(f" {name}: {val}")
2024-04-08,13:55:44 | INFO | Running with a single process. Device cuda:0.#运行在GPU
2024-04-08,13:55:44 | INFO | Loaded daclip_ViT-B-32 model config.#加载模型配置文件
2024-04-08,13:55:47 | INFO | Loading pretrained daclip_ViT-B-32 weights (E:\daclip\pretrained\daclip_ViT-B-32.pt).#加载模型权重文件
2024-04-08,13:55:48 | INFO | Model:
2024-04-08,13:55:48 | INFO | DaCLIP(
(clip): CLIP(#为了方便阅读省略部分内部框架
(visual): VisionTransformer(...)
(transformer): Transformer(...))
(visual): VisionTransformer(...)
(visual_control): VisionTransformer(...)
)
2024-04-08,13:55:48 | INFO | Params:
#包含各种读取到的配置参数
C:\Users\86136\anaconda3\envs\DA-CLIP\lib\site-packages\torch\nn\functional.py:5476: UserWarning: 1Torch was not compiled with flash attention.
#我的电脑不支持 flash attention,这只是警告
真正问题
Traceback (most recent call last):
File "C:\Users\86136\anaconda3\envs\DA-CLIP\lib\runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "C:\Users\86136\anaconda3\envs\DA-CLIP\lib\runpy.py", line 87, in _run_code
exec(code, run_globals)
File "C:\Users\86136\Desktop\daclip-uir-main\da-clip\src\training\main.py", line 490, in <module>
main(sys.argv[1:])
File "C:\Users\86136\Desktop\daclip-uir-main\da-clip\src\training\main.py", line 422, in main
evaluate(model, data, completed_epoch, args, writer)
File "C:\Users\86136\Desktop\daclip-uir-main\da-clip\src\training\train.py", line 266, in evaluate
model_out = model(images, texts)
File "C:\Users\86136\anaconda3\envs\DA-CLIP\lib\site-packages\torch\nn\modules\module.py", line 1514, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "C:\Users\86136\anaconda3\envs\DA-CLIP\lib\site-packages\torch\nn\modules\module.py", line 1527, in _call_impl
return forward_call(*args, **kwargs)
File "C:\Users\86136\Desktop\daclip-uir-main\da-clip\src\open_clip\daclip_model.py", line 68, in forward
text_features = self.encode_text(caption, normalize=True) if text is not None else None
File "C:\Users\86136\Desktop\daclip-uir-main\da-clip\src\open_clip\daclip_model.py", line 59, in encode_text
return self.clip.encode_text(text, normalize)
File "C:\Users\86136\Desktop\daclip-uir-main\da-clip\src\open_clip\model.py", line 245, in encode_text
x = x + self.positional_embedding.to(cast_dtype)# 报错的地方在这里
RuntimeError: The size of tensor a (39) must match the size of tensor b (77) at non-singleton dimension 1
进程已结束,退出代码0没办法运行调试
查错
caption张量维度[batch_size,39]与context_length长度77不匹配
报错点文本编码 encode_text(),项目本地open_clip文件夹下的model.py中CLIP类的方法
def encode_text(self, text, normalize: bool = False):
# normalize,是否对最终的嵌入向量进行归一化处理。输入为True
cast_dtype = self.transformer.get_cast_dtype()
# float32
x = self.token_embedding(text).to(cast_dtype)
# [batch_size, n_ctx, d_model],
# batch_size批处理大小,n_ctx文本窗口大小,d_model模型处理维度
p=self.positional_embedding.to(cast_dtype)
x = x + p# 报错的地方在这里
x[175,39,512] ,p[77,512],两者在第一维512上匹配,在第二维39与77不匹配
再往上扒
DA-CLIP的encode_text()与CLIP 的相同,该方法在DA-CLIP的forward()中被调用
def forward(
self,
image: Optional[torch.Tensor] = None,
text: Optional[torch.Tensor] = None,
):
(caption, degradation) = text.chunk(2, dim=-1) if text is not None else (None, None)
# encode_image
# ...
text_features = self.encode_text(caption, normalize=True) if text is not None else None
对以上代码的张量维度进行输出
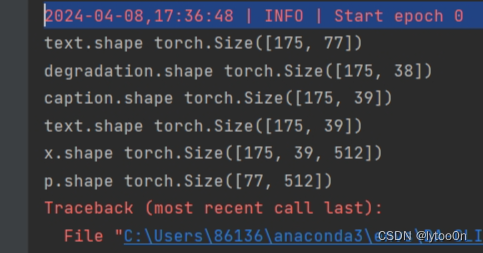
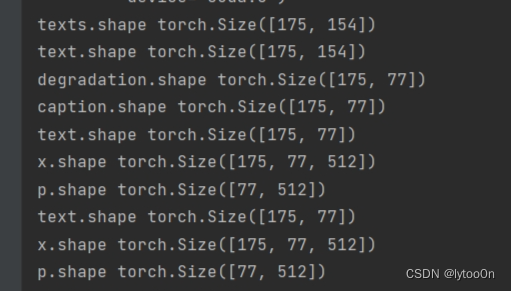
显示报错时总的文本张量为【175,77】,175是我val.csv中的数据量,77应该是dataloader将文本转张量时的特定长度。caption是39列,degradation是38列。原因如下:
对于代码 caption, degradation= text.chunk(2, dim=-1)
text张量的形状是[175, 77],意味着它有175行和77列。当我们调用text.chunk(2, dim=-1)时,我们是在请求将每行分割成长度为2的多个块。由于dim=-1代表最后一个维度,这里的最后一个维度是列(即宽度),所以我们会将每列分割成长度为2的多个小块。对于每一列,我们将得到一个包含多个长度为2的块的列表。
caption=
(77 + 1) // 2=39
chunk小demo
import torch
# 创建一个形状为[1, 5]的张量text
text = torch.tensor([[1, 2, 3, 4, 5]])
# 使用chunk函数将每列分割成大小为2的块
# 由于我们的张量只有一行,我们需要使用unsqueeze方法增加一个维度,使其变为[1, 1, 5]
text_reshaped = text.unsqueeze(0) # 现在形状为[1, 1, 5]
caption, degradation = text_reshaped.chunk(2, dim=-1)
# 移除增加的维度,使其形状回到[1, 5],并打印结果
caption = caption.squeeze(0)
degradation = degradation.squeeze(0)
print("caption:", caption)
print("degradation:", degradation)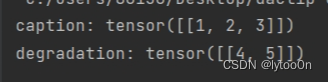
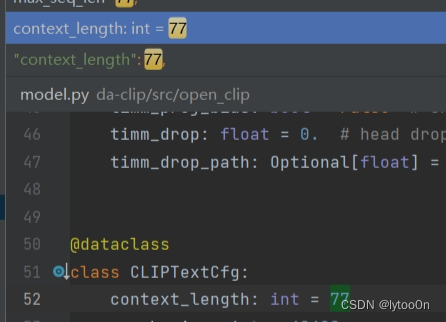
维度定义
context_length
查到是在open_clip的model.py文件的CLIPTextCfg类中定义的context_length变量
小结
以上只是初步判断问题源。我们可以得到一个判断:读取我的val.csv时将文本长度77一分为二以获得对应caption和degradation。为了获得文本特征text_feature将caption与位置编码[77,512]相加,然而未设置相关判断,在文本长度上显然不相等而报错。
然而由于缺乏相关训练提示,仍存在以下问题
- 为什么是读取验证集时报错,而不是训练集的数据?
- 如何让两者尺度匹配而不影响后续训练?
- 这个报错与加载的模型有关还是跟代码有关?
相关提问:
https://github.com/Algolzw/daclip-uir/issues/30
有朋友使用该仓库代码准备训练自己的数据集时,存在与该问题相同报错,分析也与我相同。
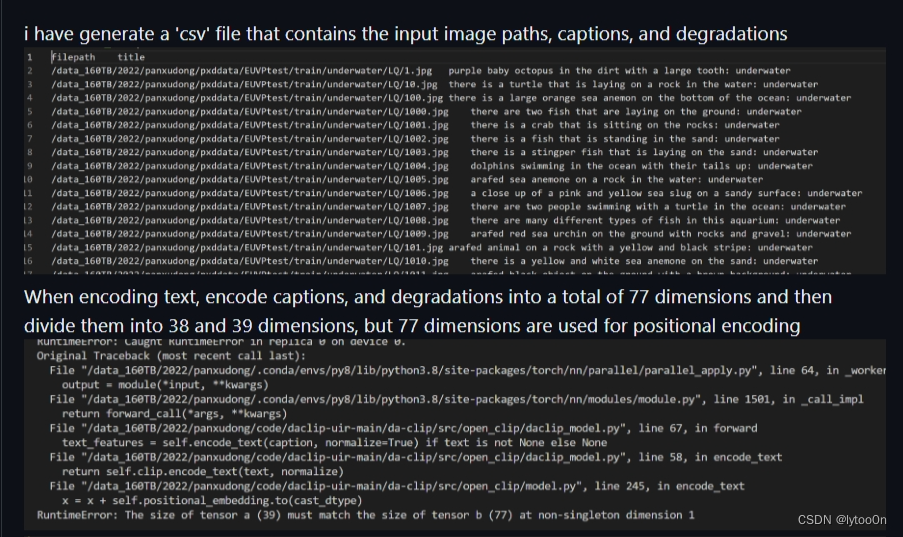
Aha, but I haven't met this error yet. BTW, have you modified the dataset loader? And can you print the dimension of the tokenized text here?
作者的回复是,未遇到过该问题 。建议查看dataset读取过程的代码,并检查文本token维度
随后该提问者提出,他使用的是作者提供的daclip模型权重文件。而非readme中指定的https://huggingface.co/laion/CLIP-ViT-B-32-laion2B-s34B-b79K/resolve/main/open_clip_pytorch_model.bin
他怀疑是否是因为这个原因导致的上述报错。
This pretrained model is always for the original CLIP model.
Actually, we haven't provided the code for finetuning on our DA-CLIP weights. You can easily retrain the model on your dataset from scratch (maybe ~10 hours, depending on your dataset).
But it's a good suggestion to have the finetuning function in training, we will fix that later.
作者说这个预训练模型本来就是用原始的CLIP模型,而不是使用他们的训练好的模型
然而,根据分析,我认为更多的还是dataset loader的过程中代码处理的问题。
直接使用该模型会报state_dict不匹配问题。
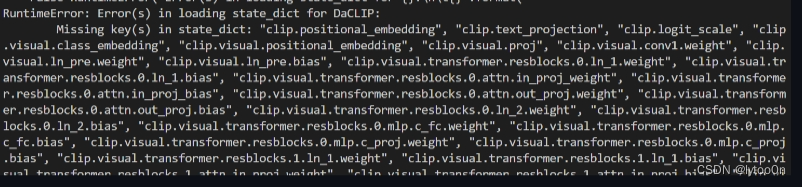
作者建议
Can you use the official open_clip to load that weight?
随后没有下文。 还要看open_clip仓库?还没看,我使用部分匹配解决这个state_dict不匹配,还是报张量不匹配。修改load_checkpoint的strict参数为False。
def load_checkpoint(model, checkpoint_path, strict=False):我的疑惑是,如果是按作者所说读取clip预训练模型权重,但是设置的模型名称是daclip,代码应该已经有相关的配置进行权重字典匹配,为什么还会报错?
我的csv内容为
 main.py训练过程报错代码
main.py训练过程报错代码
查看da-clip/src/training/main.py
主函数前面部分主要涵盖了从参数解析到模型初始化、日志记录、分布式训练设置、优化器创建等关键步骤。
报错代码 evaluate(model, data, completed_epoch, args, writer),然而还要读懂上文操作
for epoch in range(start_epoch, args.epochs):
...
train_one_epoch(model, data, loss, epoch, optimizer, scaler, scheduler, dist_model, args, tb_writer=writer)
completed_epoch = epoch +1
if any(v in data for v in ('val', 'imagenet-val', 'imagenet-v2')):
evaluate(model, data, completed_epoch, args, writer)
train_one_epoch来源from training.train ,应该是读取train.csv进行了一次训练过程,但是没有输出并且没有报错,难道train和val两者dataset读取方式不一样吗?
train_one_epoch
又是很长的方法定义多个参数,看的我头疼。先看接受的参数来源,再看方法定义。
model来源
命令行指定
"--model", "daclip_ViT-B-32",main读取并使用create_model_and_transforms()
model, preprocess_train, preprocess_val = create_model_and_transforms(
args.model,
args.pretrained,
precision=args.precision,
device=device,
jit=args.torchscript,
force_quick_gelu=args.force_quick_gelu,
force_custom_text=args.force_custom_text,
force_patch_dropout=args.force_patch_dropout,
force_image_size=args.force_image_size,
pretrained_image=args.pretrained_image,
image_mean=args.image_mean,
image_std=args.image_std,
aug_cfg=args.aug_cfg,
output_dict=True,
)相关内容参考之前解读。创建了一个daclip模型实例。
data来源
from training.data import get_data
data = get_data(args, (preprocess_train, preprocess_val), epoch=start_epoch, tokenizer=get_tokenizer(args.model))
get_data()
def get_data(args, preprocess_fns, epoch=0, tokenizer=None):
preprocess_train, preprocess_val = preprocess_fns
data = {}
if args.train_data or args.dataset_type == "synthetic":
data["train"] = get_dataset_fn(args.train_data, args.dataset_type)(
args, preprocess_train, is_train=True, epoch=epoch, tokenizer=tokenizer)
if args.val_data:
data["val"] = get_dataset_fn(args.val_data, args.dataset_type)(
args, preprocess_val, is_train=False, tokenizer=tokenizer)
.......根据get_data_fn()函数里的相关判断选择返回执行相应的函数
def get_dataset_fn(data_path, dataset_type):
if dataset_type == "webdataset":
return get_wds_dataset
elif dataset_type == "csv":
return get_csv_dataset
elif dataset_type == "synthetic":
return get_synthetic_dataset
elif dataset_type == "auto":
ext = data_path.split('.')[-1]
if ext in ['csv', 'tsv']:
return get_csv_dataset
elif ext in ['tar']:
return get_wds_dataset
else:
raise ValueError(
f"Tried to figure out dataset type, but failed for extension {ext}.")
else:
raise ValueError(f"Unsupported dataset type: {dataset_type}")
args.dataset_type找不到相关定义,训练时的命令行参数也没设置。但参数列表显示为auto.
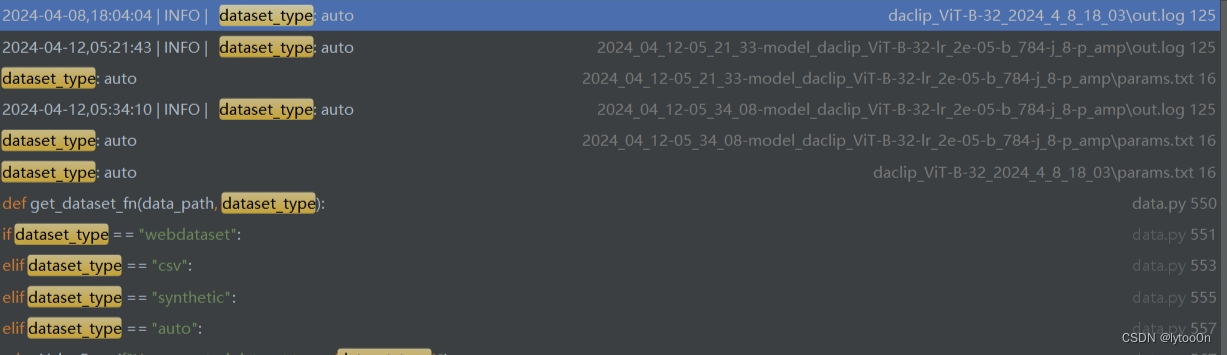
返回执行get_csv_dataset()
def get_csv_dataset(args, preprocess_fn, is_train, epoch=0, tokenizer=None):
input_filename = args.train_data if is_train else args.val_data
assert input_filename
dataset = CsvDataset(
input_filename,
preprocess_fn,
img_key=args.csv_img_key,
caption_key=args.csv_caption_key,
sep=args.csv_separator,
tokenizer=tokenizer,
da=args.da,
crop=args.crop,
)
num_samples = len(dataset)
sampler = DistributedSampler(dataset) if args.distributed and is_train else None
shuffle = is_train and sampler is None
dataloader = DataLoader(
dataset,
batch_size=args.batch_size,
shuffle=shuffle,
num_workers=args.workers,
pin_memory=True,
sampler=sampler,
drop_last=is_train,
)
dataloader.num_samples = num_samples
dataloader.num_batches = len(dataloader)
return DataInfo(dataloader, sampler)根据是否用于训练的参数is_train判断读的是train.csv函数val.csv
da!!!
class CsvDataset(Dataset):
def __init__(self, input_filename, transforms, img_key, caption_key, sep="\t", tokenizer=None, da=False, crop=False):
logging.debug(f'Loading csv data from {input_filename}.')
df = pd.read_csv(input_filename, sep=sep)
self.images = df[img_key].tolist()
self.captions = df[caption_key].tolist()
self.transforms = transforms
logging.debug('Done loading data.')
self.tokenize = tokenizer
self.da = da
self.crop = crop
def __len__(self):
return len(self.captions)
def __getitem__(self, idx):
images = Image.open(str(self.images[idx]))
texts = str(self.captions[idx])
if self.da:
caption, degradation = texts.split(': ')
caption = self.tokenize([caption])[0]
degradation = self.tokenize([degradation])[0]
texts = torch.cat([caption, degradation], dim=0)
# texts = torch.cat([caption, caption], dim=0)
if self.crop and random.random() > 0.2:
images = random_crop(images)
else:
texts = self.tokenize([texts])[0]
images = self.transforms(images)
return images, texts注意if self.da里代码。
直觉告诉我这里应该使da值为true,这样caption和degradation两个tokenize组合,再从中间分开时才是完整的两部分这样77维度才能匹配。显然这次x和p匹配了
--da有默认值,修改为True或指定为true。文件是train文件夹下的params.py
parser.add_argument(
"--da",
default=True,
action="store_true",
help="If true, train/finetune degradation aware CLIP."
)默认值原来为false,应该是没有degradation,只有图像和caption,这应该是微调CLIP的。
为不太了解为什么作者在训练的md既没有指定true,又没有修改默认值????
可以成功运行了

其他训练问题还没理清的有
- train.yml的degradation是不是要改为我的退化类型?
- 不能直接用daclip微调吗?可以的话代码哪里需要改,degradation如何设置?
PS:
- 这训练设置按需修改吧, 每一轮都保存checkpoint一个文件近一个g内存有点吃不消。
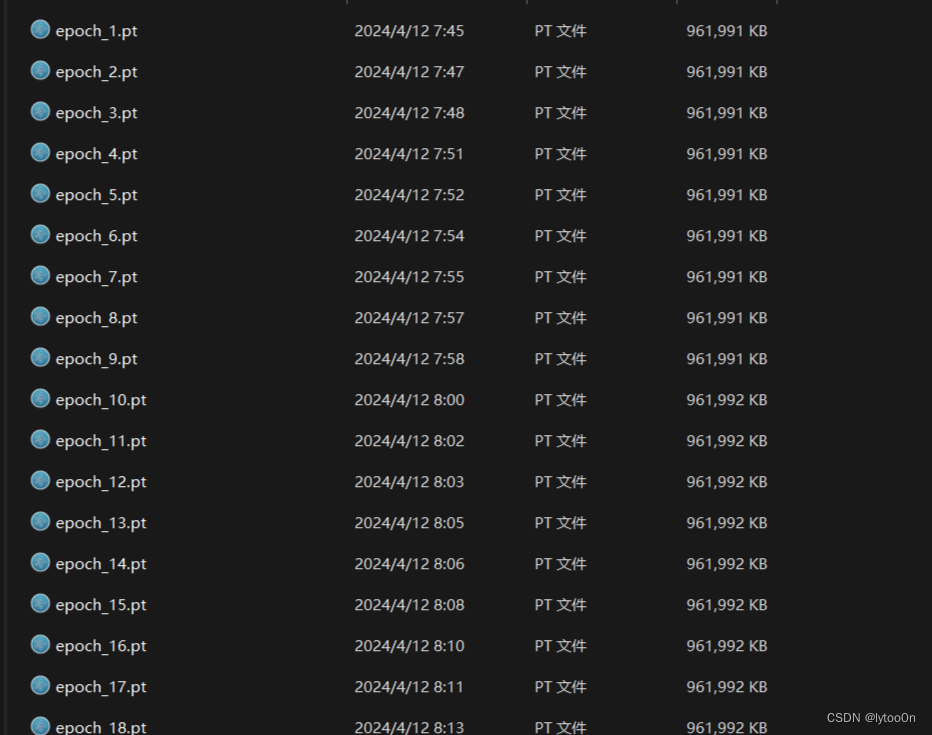
- 其次,跑了 30轮一模一样的数据....这是什么情况我还得分析一下....


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









