







在这半个月学习查询解析模块的过程中,我不断地翻看源码,不断地上网查找相应的资料,终于对这个模块有了进一步的认识。
原本我认为查询分析模块的作用就是对所有的 SQL 语句进行分析处理最终生成查询树,而实际上只是对于查询处理命令( SELECT/INSERT/DELETE/UPDATE )才为其构建查询树,若是功能性命令( CREATE TABLE/CREATE USER 等 )则将其分配到功能性命令处理模块。我认为这是我在学习了相关的知识后,对这个模块作用上的认识的一个很大的改观。除此之外,我也对查询分析过程中的三个步骤有了更多的理解。
词法分析
词法分析的定义是:
从查询语句中识别出系统支持的关键字、标识符、运算符、终结符等,并确定每个词固有的词性。
应当想到,既然关键字、标识符、运算符、终结符等在系统看来是不同的东西,那么就一定预先定义好了词的类别,同时,还要有与之配套的操作,而这些都在词法文件 scan.l 中,所以我对该文件做了解析:
不过,虽然运算符、终结符等这些词可以在 scan.l 中定义,但是关键字这一类并不是在这里定义的,它们是在 src/include/parser 目录下的 kwlist.h 中被定义的。而如何查找 SQL 语句中的关键字呢?我们这时就需要用到 ScanKeywordLookup() 函数,而这个函数在 kwlookup.cpp 中:
对于标识符,我们也需要能够对其进行预处理的函数,其中一些常用的就在 scansup.cpp 中:
语法分析
同词法分析需要预先定义词法结构一样,我们也需要在语法分析前预先定义语法结构。由于词的组合形式会比词的种类多得多,所以用来定义语法结构的文件 gram.y 的体积会比 scan.l 的大了很多,我对 gram.y 做了一定的解析:
而仅仅分析定义了语法结构的文件还不行,还需要理解语法分析的过程才能加深理解,所以我对语法分析的入口函数 raw_parser() 所在的文件也进行了解析:
到这时,我才对词法分析和语法分析的流程有了更深的理解:
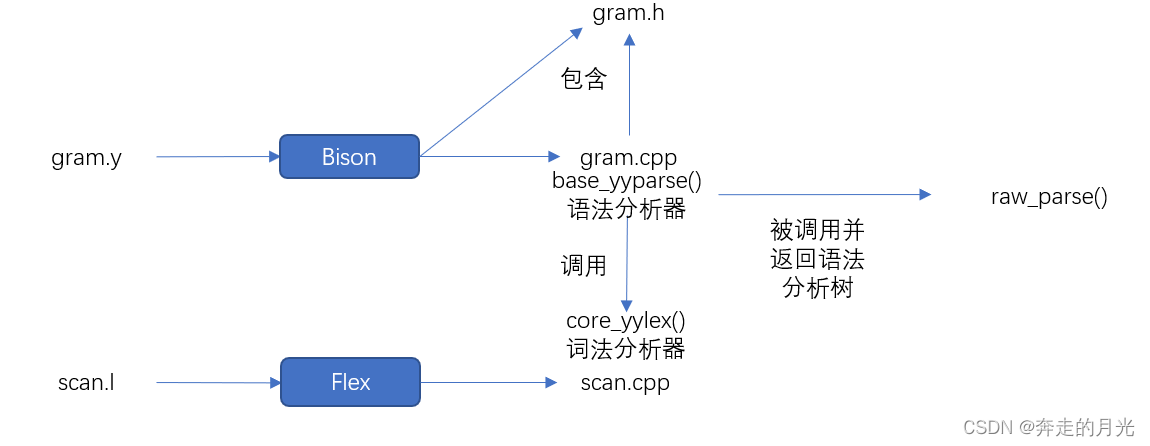
首先,词法文件 scan.l 经 Flex 编译后就生成了 scan.cpp 文件,在这个文件中有我们所需要的词法分析器 core_yylex() ,实际上 core_yylex() 只能算是这个分析器的入口,因为在这个函数内部还调用了其它函数,并且还有着更复杂的调用关系。然后,语法文件 gram.y 经 Bison 编译后就生成了 gram.cpp 文件和 gram.h 头文件,其中,在 gram.cpp 文件中有着我们需要的语法分析器 base_yyparse() ,它还将一同生成的 gram.h 作为头文件。当这个语法分析器工作时,它需要多次调用词法分析器,而每次调用都能让它获得一个返回的 token ,就是这个 token 标示了该 SQL 语句中各个词的词性(关键字、标识符、常量等)。语法分析器利用这个 token ,可以进行一系列的操作,从无到有地构建起一棵原始的语法分析树,也被称为抽象语法树( AST )。之后,词法分析和语法分析的入口函数 raw_parse() ,就会获取储存了这个语法分析树的链表。
语义分析
虽然通过词法分析和语法分析,我们确实构建起了一棵语法分析树,但是又如何保证这棵树代表的查询语句是有效的呢?以下面这条语句为例:
SELECT fir_col FROM sourcetable WHERE id>1;
我们能不能确定 fir_col 是 FROM 子句中 sourcetable 的属性,能不能确定 sourcetable 是存在的,能不能确定 id 是 sourcetable 的属性并且它的值可与数字常量比较?凡此种种,都直接决定了这条 SQL 语句的有效性,决定了所构建出来的语法分析树的有效性,这才有了语义分析这一步。
语义分析阶段会检查命令中是否有不符合语义规则的成分,主要作用是为了检查命令是否可以正确的执行。而语义分析的入口一般就是 parse_analyze() ,它所在的文件是 analyze.cpp ,连同该文件中定义的其他一些重要函数我做了一些解析:
这时,在我查找资料和翻看源码的过程中,我又对整个语法分析树和查询树的转换流程有了更深的理解:
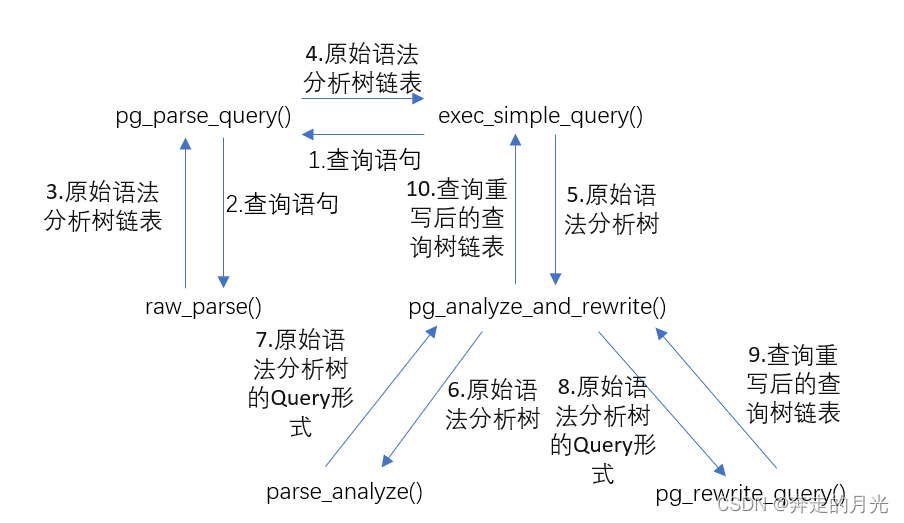
这张图片中,和第8、9步操作有关的 pg_rewrite_query() 函数属于查询重写这个模块,查询重写就是把用户输入的SQL语句转换为更高效的等价SQL,是基于规则的逻辑优化。由于现阶段我还没有涉及这方面的知识,所以这个日后再说。另外,这个函数所在文件为 postgres.cpp ,该文件又在 src/gausskernel/process/tcop 目录下,值得一看。pg_parse_query()、pg_analyze_and_rewrite() 和 exec_simple_query() 函数均在 postgres.cpp 文件中,我们先来看一下 pg_parse_query() 的部分源码:
//代码清单1
//src/gausskernel/process/tcop/postgres.cpp
List* pg_parse_query(const char* query_string, List** query_string_locationlist)
{
List* raw_parsetree_list = NULL;
PGSTAT_INIT_TIME_RECORD();
TRACE_POSTGRESQL_QUERY_PARSE_START(query_string);
if (u_sess->attr.attr_common.log_parser_stats)
ResetUsage();
PGSTAT_START_TIME_RECORD();
List* (*parser_hook)(const char*, List**) = raw_parser;
······
raw_parsetree_list = parser_hook(query_string, query_string_locationlist);
PGSTAT_END_TIME_RECORD(PARSE_TIME);
if (u_sess->attr.attr_common.log_parser_stats)
ShowUsage("PARSER STATISTICS");
······
TRACE_POSTGRESQL_QUERY_PARSE_DONE(query_string);
return raw_parsetree_list;
}可以看到,在代码清单1中 pg_parse_query() 的返回值是 List* 类型的指针 raw_parsetree_list ,也可以认为是原始语法分析树链表,而得到 raw_parsetree_list 用到了 parser_hook() 函数,再往前看就发现 parser_hook() 其实就是 raw_parser() 函数,这就说明上图步骤2、3是合理的。还有一点,为什么返回的是原始语法分析树链表而不是原始语法分析树呢应为当用户在一个命令字符串中执行多个SQL命令,也就是说客户端提交给服务进程的字符串包含多个SQL命令时,比如:
//代码清单2
CREATE TABLE newtable(id INTERGER,name VARCHAR(10));
INSERT INTO newtable VALUES(7,'Luoge');
SELECT id FROM newtable;那么在接收到该字符串之后进行词法和语法分析的结果就是三个分析树:CreateStmt、InsertStmt和 SelectStmt ,在返回的 raw_parsetree_list 中就有三个 ListCell 结构体分别包含上述的这三个分析树。
再来看一下 pg_analyze_and_rewrite() 的部分源码:
//代码清单3
//src/gausskernel/process/tcop/postgres.cpp
List* pg_analyze_and_rewrite(Node* parsetree, const char* query_string, Oid* paramTypes, int numParams)
{
Query* query = NULL;
List* querytree_list = NULL;
TRACE_POSTGRESQL_QUERY_REWRITE_START(query_string);
/*
* (1) Perform parse analysis.
*/
if (u_sess->attr.attr_common.log_parser_stats)
ResetUsage();
······
query = parse_analyze(parsetree, query_string, paramTypes, numParams);
if (u_sess->attr.attr_common.log_parser_stats)
ShowUsage("PARSE ANALYSIS STATISTICS");
/*
* (2) Rewrite the queries, as necessary
*/
querytree_list = pg_rewrite_query(query);
······
TRACE_POSTGRESQL_QUERY_REWRITE_DONE(query_string);
return querytree_list;
}可以很清晰地看到函数里的代码分为两部分,一部分用来做语义分析,另一部分用来做查询重写。关键的代码就是第14、21行,第14行是调用了 parse_analyze() 函数,用 Query* 类型的指针接收返回的指向经语义分析得到的查询树的指针,第21行是利用 pg_rewrite_query() 得到重写后的查询树链表,用 List* 类型的 querytree_list 接收,最后该函数返回该值并结束。
最后看一下 exec_simple_query() 函数的部分源码:
//代码清单4
//src/gausskernel/process/tcop/postgres.cpp
static void exec_simple_query(const char* query_string, MessageType messageType, StringInfo msg = NULL)
{
······
if (HYBRID_MESSAGE == messageType) {
parsetree_list = pg_parse_query(sql_query_string);
} else {
if (copy_need_to_be_reparse != NULL && g_instance.status == NoShutdown) {
bool reparse_query = false;
gs_stl::gs_string reparsed_query;
do {
parsetree_list = pg_parse_query(reparsed_query.empty() ?
query_string : reparsed_query.c_str(), &query_string_locationlist);
reparse_query = copy_need_to_be_reparse(parsetree_list, query_string, reparsed_query);
} while (reparse_query);
} else {
parsetree_list = pg_parse_query(query_string, &query_string_locationlist);
}
}
······
/*
* @hdfs
* If we received a hybridmessage, we use sql_query_string to analyze and rewrite.
*/
if (HYBRID_MESSAGE != messageType)
querytree_list = pg_analyze_and_rewrite(parsetree, query_string, NULL, 0);
else
querytree_list = pg_analyze_and_rewrite(parsetree, sql_query_string, NULL, 0);
······
}总结
我的关于查询分析模块的解析博客到这就算是完结了,但是只学习一个模块是孤立的,是不成体系的,后续我会继续去学习其它的模块。而利用解析查询分析模块的经验,我相信这对于解析其它的模块会有很大的帮助。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











