






 本文介绍了如何使用PyQuery库来解析HTML文档。通过字符串、URL或文件导入HTML,然后提取所需信息。例如,提取<a>标签的href属性和文本内容,以及网页标题。在处理含有中文的HTML文件时,需要注意编码问题,可能需要先读取文件并重新编码为UTF-8。
本文介绍了如何使用PyQuery库来解析HTML文档。通过字符串、URL或文件导入HTML,然后提取所需信息。例如,提取<a>标签的href属性和文本内容,以及网页标题。在处理含有中文的HTML文件时,需要注意编码问题,可能需要先读取文件并重新编码为UTF-8。
基本用法
pyquery包中包含一个PyQuery类,使用PyQuery前先导入该类,创建PyQuery类的实例
可以使用(字符串、URL、文件)来将HTML文档传入PyQuery对象
import pyquery
from pyquery import PyQuery例子:
import pyquery
import requests
from pyquery import PyQuery as pq
html="""
<div>
<ul>
<li class="item1" value="1234" value2="hello world"><a href ="https://geekori.com">geekori.com</a></li>
<li class="item"><a href ="https://www.jd.com">京东商城</a>
</ul>
<ul>
<li class="item3"><a href ="https://www.taobao.com">淘宝</a></li>
<li class="item"><a href ="https://www.microsoft.com">微软</a></li>
<li class="item2"><a href ="https://www.google.com">谷歌</a></li>
</ul>
</div>
"""
# 使用字符串形式将html文件传入PyQuery对象
doc=pq(html)
# 输出<a>节点href属性值和文本内容
for a in doc('a'):
print(a.get('href'),a.text)
# 使用url形式将html文档传入PyQuery对象
doc=pq(url='https://www.jd.com/')
print(doc('title'))
# 抓取html代码,将html代码传入PyQuery对象
doc=pq(requests.get('https://www.jd.com/').text)
print(doc('title'))结果: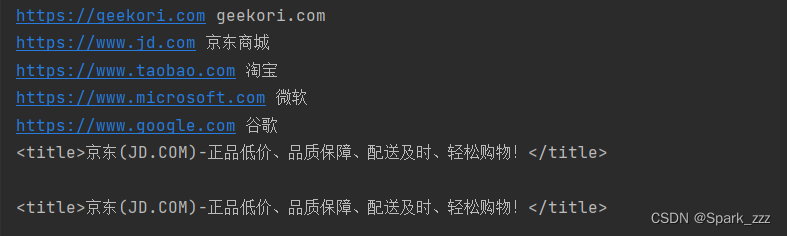
前面文章定义了demo.html文件
# 从html文件 将html代码传入PyQuery对象
doc=pq(filename='demo.html')运行发现报错了: 'gbk' codec can't decode byte 0xac in position 256: illegal multibyte sequence
尝试把demo.html里面中文改成英文,则运行成功
于是我把demo.html格式先处理一下,
先读取文件,重新编码,字符串初始化
with open('demo.html','r+',encoding='utf-8') as f:
text=f.read()
doc=pq(text)
print(doc('head'))结果:




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









