






 本文介绍如何使用lxml库解析XML文件,包括从文件和字符串中读取XML内容的方法,以及如何获取节点名称、属性和文本等关键信息。
本文介绍如何使用lxml库解析XML文件,包括从文件和字符串中读取XML内容的方法,以及如何获取节点名称、属性和文本等关键信息。
PS:仅为本人笔记
lxml.etree._ElementTree对象,使用该对象的getroot方法获得根节点
如果得到某个节点的所有子节点,使用getchildren方法
不管什么节点都是lxml.etree._ElementTree对象
获得节点名称,使用tag属性
获得节点名称,使用text属性
获得节点属性值,get方法,例如:get('id')获得当前节点的id属性值
索引形式获取节点的子节点,例如child表示当前节点,child[0]用于获得第1个子节点对象
准备一个xml文件
<products>
<product id ="0001">
<name>手机</name>
<price>4500</price>
</product>
<product id ="0002">
<name>电脑</name>
<price>8500</price>
</product>
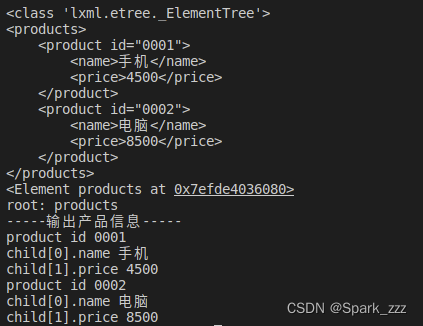
</products>读取*.xml文件代码
读取xml文件,使用parse函数,需要传入一个xml文件名
from lxml import etree
# 读取products.xml文件
tree=etree.parse('products.xml')
print(type(tree))
# 将tree重新转换为字符串形式的xml文档,并输出
print(str(etree.tostring(tree,encoding="utf-8"),"utf-8"))
# 获得根节点对象
root=tree.getroot()
print(root)
# 输出根节点名称
print("root:",root.tag)
# 获得根节点的所有子节点
children=root.getchildren()
print('-----输出产品信息-----')
# 迭代这些子节点,并输出对应属性和节点文本
for child in children:
print("product id",child.get('id'))
print("child[0].name", child[0].text)
print("child[1].price", child[1].text)运行结果:
读取以字符串形式出现的xml文档
解析字符串形式的xml文档,使用fromstring函数,函数参数为xml字符串
# 分析字符串形式的xml文档
root=etree.fromstring("""
<products>
<product1 name="iphone"/>
<product2 name="ipad"/>
</products>
""")
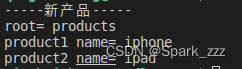
print('-----新产品-----')
# 输出根节点的节点名
print("root=",root.tag)
children=root.getchildren()
# 迭代这些子节点,并输出节点名称和name属性名
for child in children:
print(child.tag,'name=',child.get('name'))运行结果:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









