






 本文详细介绍了Java的基础知识,包括内存管理、数据类型、对象引用、异常处理、集合框架等。讨论了栈与堆的区别、单例模式的实现、构造器、面向对象特性、线程安全以及String与StringBuilder的使用。此外,还涵盖了异常分类、静态方法与实例方法的差异,以及对象相等与引用相等的概念。最后,深入解析了线程状态和集合类如ArrayList与LinkedList的性能比较。
本文详细介绍了Java的基础知识,包括内存管理、数据类型、对象引用、异常处理、集合框架等。讨论了栈与堆的区别、单例模式的实现、构造器、面向对象特性、线程安全以及String与StringBuilder的使用。此外,还涵盖了异常分类、静态方法与实例方法的差异,以及对象相等与引用相等的概念。最后,深入解析了线程状态和集合类如ArrayList与LinkedList的性能比较。
堆和栈的问题
基本类型变量在栈里面存储,随着方法的弹出栈(方法执行完毕后),基本类型变量会从栈中移除。
引用类型变量在堆里面存储,当该变量不被引用,引用类型变量会从堆里移除。
main方法会在栈中执行。
局部变量

单例模式
创建有五种方法,常用的就是懒汉式和饿汉式
饿汉式步骤:1、声明一个静态的私有对象。
2、构造方法私有化
3、提供一个对外获取对象的静态方法
静态方法不管怎么调用,静态方法锁对象都是当前类。
普通方法调用,普通方法的锁对象就是那个实例对象。
异常
编译时异常:代码编译期间,如果有异常,就会显示
运行时异常:在代码运行期间,如果有异常,就会显示在控制台上。
Java基础
面向过程:分析的是问题的解决过程。
- 优点:性能执行效率高
- 缺点:后期不易维护。
- 用途:嵌入式开发,游戏开发等
面向对象:分析问题的解决对象是谁?
- 优点:程序便于维护,后期重构。
- 缺点:性能差点
- 用途:企业级系统开发。
Java语言有那些特点:
- 任意平台可以运行
- 面向对象(三大特点:封装,多态,继承)。
- 可靠性
- 安全性
- 支持多线程(C++语言没有内置的多线程机制,因此必须调用操作系统的多线程功能来进行多线程程序设计,而Java语言却提供了多线程支持)
- 支持网络编程并且很方便(Java语言诞生本身就是为了简化网络编程设计的,因此Java语言不仅支持网络编程而且还很方便)。
- 编译和解释并存。
JDK,JRE,JVM
- 从范围大小来说:
1、jdk:Java开发环境
2、jre:Java运行环境
3、jvm:java虚拟机(作用:解释执行字节码class字节码文件的)
结论:jdk包含jre,jre包jvm - 从内容来说:jdk主要包含三大部分
1、Java的核心命令:
后缀名为.java—源码,开发程序
后缀名为.class—字节码文件,先编译
Java核心命令:javac.exe(编译命令)java.exe(java 运行命令)
核心jar:tools.jar,rt.jar(里面有C语言的文件)等等(jar包大部分都是class文件,不能直接阅读)
源码包:src.zip(source.zip,里面都是Java文件,可以直接阅读对应的jar的class文件)
比如:src.zip:A,.java(可以直接阅读)---------define.jar:A,class(不能直接阅读)
字符型常量和字符串常量的区别
- 字符: char a = ‘a’ ;在内存中占2个字节,char基本类型
- 字符串:比如 string str = “ab”,在内存中根据字符串的长度去判断占多少字节,string是引用类型
构造器Constructor是否可被override重写
- 重写:子类(子接口)重写父类(父接口)的方法
- 重载:在类中,方法名相同,方法的参数个数,参数类型不同,与返回值无关
- 构造器Constructor不可以被重写。
面向对象三大特性
- 封装:将属性私有化,提供get set 方法,方便程序员自己修改
- 继承:子类继承父类,可以实现程序的复用性,减少代码的冗余,父类的私有属性不可用,只能在本类中使用。
- 多态:同一种行为,不同子类对象具有不同的表现形式,要求是:继承+重写,
- 口诀:父类引用指向子类对象:父类型的引用类型变量保存的是子类对象的地址值。
- 编译看左边,运行看右边。父类种定义的功能,子类才能使用,否则报错。
String ,StringBuffer,StringBuilder的区别?
- String的值不可变:底层保存数据的是final char[ ],数组里面的值不可变。
- StringBuffer,StringBuilder值可以变:底层保存数据是char[ ],数组里的值可以改变
- String 被final修饰,不能被继承
- StringBuffer,StringBuilder 可以被继承
- StringBuffer是线程安全的,因为里面使用了同步锁,所以性能差
- StringBuilder是线程不安全的,所以性能好。
- 从使用场景来说
- 1、操作少量的数据=String
- 2、单线程(一般是安全的)操作字符串缓冲区下操作大量数据=StringBuilder
- 3、多线程(一般线程不安全)操作字符串缓冲区下操作大量数据=StringBuffer
在一个静态方法内调用一个非静态成员为什么是非法的
- 因为静态的优先于非静态的加载,在静态方法里面不能调用非静态的成员变量。
Java中为什么要有无参构造
- 1、给成员变量赋值
- 2、实例化该类对象
- 为什么类中要有无参构造方法
- 在框架中,创建对象默认使用的都是无参构造方法,所以我们在开发中,一定要显示定义无参构造方法。
接口和抽象类的区别
- 接口可以多实现,类只能单继承
- 抽象类可以有普通方法,接口(jdk8之前)都是抽象方法
- 接口默认是public,所有方法在接口中不能有实现(java 8开始接口方法可以默认实现),抽线类可以有非抽象的方法
- 接口中实例变量默认是final类型,抽象类则不一定
- 一个类可以实现多个接口,但最多只能实现一个抽象类
- 一个类实现接口的话要实现接口的所有方法,而抽象类不一定
- 接口不能new实例化,但可以声明,但是必须引用一个实现该接口的对象,从设计层面来说抽象是对类的抽象,是一种模板设计,接口是行为的抽象,是一种行为的规范。
成员变量与局部变量的区别
- 1、从语法形式上,成员变量属于类的,而局部变量是在方法中定义的变量或是方法的参数;成员变量可以被 public,private,static 等修饰符所修饰,而局部变量不能被访问控制修饰符及 static 所修饰;但是,成员变量和局部变量都能被 final 所修饰;
- 2、从变量在内存中的存储方式来看,成员变量是对象的一部分,而对象存在于堆内存,局部变量存在于栈内存
- 3、从变量在内存中的生存时间上看,成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动消失。
- 4、成员变量如果没有被赋初值,则会自动以类型的默认值而赋值(一种情况例外被 final 修饰但没有被 static 修饰的成员变量必须显示地赋值);而局部变量则不会自动赋值。
- 从内存存储位置来说
局部变量在栈里面, 成员变量在堆里面存储 - 从生命周期来说
局部变量随着方法的进展而初始化,随着方法出栈而被移除.
成员变量在不被引用时,会从堆里面移除 - 从类中存储来说
局部变量在方法内部,必须赋值
成员变量在方法外部,不用必须赋值,有初始默认值.
对象和引用关系
特点:对象在堆里面存储,对象的地址引用在栈里存储
- 一个对象可以有多个地址引用?:正确
- 一个地址引用可以对应多个对象?:错误
- 如果地址引用不同,那么比较两个对象肯定不一样,在实际开发中,比较对象是否一样,其实比较的对象里面的内容是否一样?错误
- 一个对象可以有多个引用(引用指的对象的hashcode值)
- new运算符,new创建对象实例(对象实例在堆内存中),对象引用指向对象实例(对象引用存放在栈内存中)。一个对象引用可以指向0个或1个对象(一根绳子可以不系气球,也可以系一个气球);一个对象可以有n个引用指向它(可以用n条绳子系住一个气球)。
- 总结:
对象实体: 其实一个hashcode值,在堆里面存储,只能有1个对象实体或者0个
对象引用: 在栈空间存储, 可以有多个引用
静态方法和实例方法有何不同
- 从加载时机:静态方法优先加载
- 从调用方式来说:静态方法调用:1、可以通过类名调用,2、可以通过对象调用。实例方法只能通过对象调用
- 从访问变量来说:静态方法:调用静态变量,实例方法:静态或非静态变量都可调用
对象的相等与指向他们的引用相等,两者有什么不同
- 对象的相等,比的是比的是内存中存放的内容是否相等。而引用相等,比较的是他们指向的内存地址是否相等。
- 总结:
对象的引用: 其实一个hashcode值(一个引用一般对应一个对象)
对象实体: 指的对象里面的数据是否一样
引用相等: 对象是相等(1. 地址一样 2. 对象里面的数据一样)
对象的相等: 引用不一定一样
==与equals区别
- ==:判断两个对象的地址是不是相等,判断两个对象是不是同一个对象(基本数据类型比较的是值,引用数据类型比较的是内存地址(对象的地址引用))
- equals: 它的作用也是判断两个对象里的数据是否相等。但它一般有两种使用情况:
- 1、重写前,比较的是对象的地址值,
- 2、重写后,比较的是对象的值。
- string重写了equals和hashcode方法。
- hashcode值相等,不一定是同一对象。
- equals值相等,一定是同一个对象。
为什么重写equals时必须重写hashCode方法?
- equals方法默认继承object类的方法,底层代码使用的==号进行比较的,为了让具有相同内容的对象调用equals比较时,保证返回值是true,所以我们要重写hashcode方法,保证地址值一样。
- hashCode()介绍
获取哈希码值,也称为散列码,它实际上是返回一个int整数,这个哈希码的作用是缺点该对象在哈希表中的索引位置,hashCode()定义在JDK的object.java中,这就意味着Java中的任何类都包含hashCode()函数。
散列表存储的是键值对,特点:能根据K快速查找对应的值,这其中就利用到散列码 - 为什么要有hashCode?
- 作用就是为了快速查找到堆里面的对象。
我们以HashSet 如何检查重复为例来说明为什么要有HashCode?
- 当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的Java启蒙书《Head fist java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
hashCode() 与 equals()的相关规定
- 如果两个对象相等,则hashCode一定也是相同的
- 两个对象相等,对两个对象分别调用equals方法都返回true
- 两个对象有相同的hashCode值,它们不一定相等
- 因此,equals方法被覆盖过,则hashCode方法也必须被覆盖
- hashCode默认行为是对堆上的对象产生独特值,如果没有重写hashCode(),则该class的两个对象无论如何都不相等。
- 总结:
- hashCode()方法:比较对象的引用,判断地址值是否一样
- equals()方法:比较的是对象实体,判断对象里面的数据是否一样
简述线程,程序,进程的基本概念以及之间的关系
- 程序:开发的应用
- 进程:程序的执行单位,一个程序可以同时执行多个进程
- 比如:qq是应用,运行qq,同时发信息(进程),同时查询qq好友(进程)
- 线程:是进程的基本单位。
线程有那些基本状态?
线程一共有五种状态
- 新建线程:new状态
- 就绪状态:可运行状态,当前线程正在等待CPU的执行权
- 运行状态:当前线程正在运行(start()方法和run()方法,真正执行线程的是run()方法,start()方法是就绪状态)
- 阻塞状态:当前线程执行时,CPU的执行权被强占了。
- 死亡状态:调用死亡方法时(System.exit()方法—退出,线程会死亡)
详情如下:
新建(new):新创建了一个线程对象。
可运行(runnable):线程对象创建后,其他线程(比如main线程)调用了该对象的start()方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获 取cpu的使用权。
总结: 指的线程处于就绪状态, 还没有获取cpu的使用权
运行(running):可运行状态(runnable)的线程获得了cpu时间片(timeslice),执行程序代码。
阻塞(block):阻塞状态是指线程因为某种原因放弃了cpu使用权,也即让出了cpu timeslice,暂时停止运行。直到线程进入可运行(runnable)状态,才有 机会再次获得cpu timeslice转到运行(running)状态。阻塞的情况分三种:
(一). 等待阻塞:运行(running)的线程执行o.wait()方法,JVM会把该线程放 入等待队列(waitting queue)中。
(二). 同步阻塞:运行(running)的线程在获取对象的同步锁时,若该同步锁 被别的线程占用,则JVM会把该线程放入锁池(lock pool)中。
(三). 其他阻塞: 运行(running)的线程执行Thread.sleep(long ms)或t.join()方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状态。当sleep()状态超时join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入可运行(runnable)状态。
Java序列化中如果有些字段不想进行序列化,那么该怎么办?
- 开发场景: client<--------所需的字段数据信息,其它字段不要------------------server后端,
- 在后端直接不序列化不需要的字段
- 常见的序列化方式: 将 对象(bean,list, map等等) 序列化为对应的json数据((后期玩微信支付,传输xml格式的数据))
- 1、json序列化: {key: value}, [{key: value},{key: value},], {key:{key: value}},[{key:{key: value}},{key:{key: value}}]
- 2、xml序列化:比如:jackjson
解决方法: - json序列化时,某些字段不参与:使用@Jsonlgonre–jackjson的注解,如果其他json序列化组件,使用Transient
- 其他方式序列化,某些字段不参与:Transient当作修饰符修饰字段,该字段不会被序列化。
异常处理总结
- try块:用于捕获异常,其后可接零个或多个catch块,如果没有catch块,则必须跟一个finally块
- catch块:用于处理try捕获到的异常
- finally块:无论是否捕获或处理异常,finally块里的语句都会被执行,当在try块或catch块中遇到return语句时,finally语句将在方法返回之前被执行
以下4种特殊情况,finally块不会执行:
- 1、在finally语句中发生了异常
- 2、在前面代码中使用了System.exit()退出程序
- 3、程序所在的线程死亡
- 4、关闭CPU
场景:
- 1、实际开发中处理异常, 是抛出,如果抛出, 抛到那一层, 还是捕获,在那一层捕获异常信息,
企业开发中, 需要在数据层抛出异常, 异常信息抛给业务层,在业务层抛出异常, 异常信息抛到web层
在web层捕获异常信息. - 原因: 在web层,使用框架,自带异常处理机制. 比如: springmvc框架,全局的异常处理机制, @ControllerAdvice
- 2、需不要自己定义异常类?
在企业开发中, 需要自定义异常, 通过自定义的异常信息,快速查找到异常出现的位置.
如何自定义异常类?
方式一: 自定义编译期间异常类, 继承Exception(这种方式,使用的少)
方式二: 自定义运行期间异常类, 需要RunnTimeException
集合
list,Set,Map三者的区别和总结
- 体系结构
顶层接口:Collection(单列集合):list ,set
双列集合接口:Map - List特点:有序,数据可重复,List集合保存的数据是由索引的。
实现类:
1、ArrayList:底层是数组保存数据
2、LinkeList:底层是链表(链表+数组)保存数据 - Set特点:无序,不可重复,Set集合保存的数据没有索引的
实现:HashSet , TreeSet - Map 双列集合:底层保存数据entry(KV结构)
- 实现类:HashMap, HashTable , ConCurrentHashMap
Arraylist 和 LinkedList区别?
- Arraylist底层使用的是数组(存读数据效率高,插入删除特定位置效率低),LinkedList底层使用的是双向循环链表数据结构(插入,删除效率特别高)。学过数据结构这门课后我们就知道采用链表存储,插入,删除元素时间复杂度不受元素位置的影响,都是近似O(1)而数组为近似O(n),因此当数据特别多,而且经常需要插入删除元素时建议选用LinkedList.一般程序只用Arraylist就够用了,因为一般数据量都不会蛮大,Arraylist是使用最多的集合类。
- 相同点:都是List接口的实现类
- 不同点:
- 从底层存储数据结构来说:
- ArrayList:底层使用数组来存储数据
- LinkedList:底层是双向链表来存储数据
- 从操作来说:
- 查询来说:ArrayList查询快,LinkedList查询慢
- 更新来说:指的添加数据和删除数据,ArrayList更新慢,LinkedList更新慢(链表:”指针“)

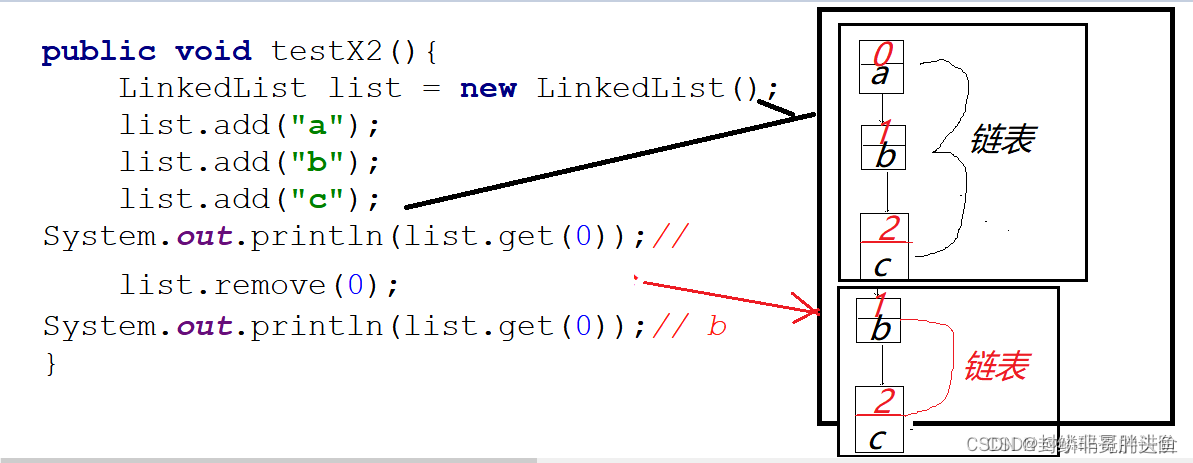
ArrayList 和 LinkedList谁占内存空间大
- Arraylist占空间小,底层数组存储数据, 数组中一个索引对应一个数据
优点: 根据索引查询数据, 查询效率高
缺点:更新(添加,删除)数据时,需要索引移位, 更新效率低 - LinkedList占空间大,底层是双向链表,链表中一个节点对应三个数(上个节点数据,当前节点数据,下个节点数据)
优点: 更新数据时,没有移位这个说法, 节点会链接, 更新效率高
缺点: 查询数据,查询效率低

HashMap 和 HashTable
- 从底层存储数据的数据结构来说
HashMap数据结构: 链表+数组
HashTable数据结构: 链表+数组 - 从线程安全来讲
HashMap: 不安全
HashTable: 线程安全的,里面的方法被synchronized修饰, 使用效率低.
ConcurrentHashMap的源码分析
- 从线程安全性来说
线程安全的. - JDK8以后如何实现线程安全的?
数据结构: 链表+数组的方式, 当数据添加超过一定长度时,而是二叉树(红黑树)+数组
里面而采用了 CAS + synchronized 来保证线程安全性。
CAS是一种算法,后面再说 - JDK8之前如何实现线程安全的?
数据结构: 链表+数组的方式.
数组默认长度是16,Segment把数组进行分段, 再使用ConcurrentHashMap使用那一段数组,给使用的数组加锁.
ConcurrentHashMap采用了分段锁技术,其中Segment继承于ReentrantLock`
HashSet 和 HashMap 区别
HaseSet单列集合
底层数据结构:使用的hashMap
HashMap双列集合
底层数据结构:
jdk8之前: 链表+数组
jdk8之后: 红黑树+数组
扩容机制: 默认长度是16,当首次添加数据超出16时,扩容因子是3/4. 新的长度= 原来长度+ 原来*(3/4)
遍历Set集合,通过索引遍历,说法正确吗? 不正确, 通过迭代器遍历.
遍历Map集合,遍历方式有几种,并代码描述出来?
方式一: 根据 key遍历
方式二: 根据entry遍历


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









