



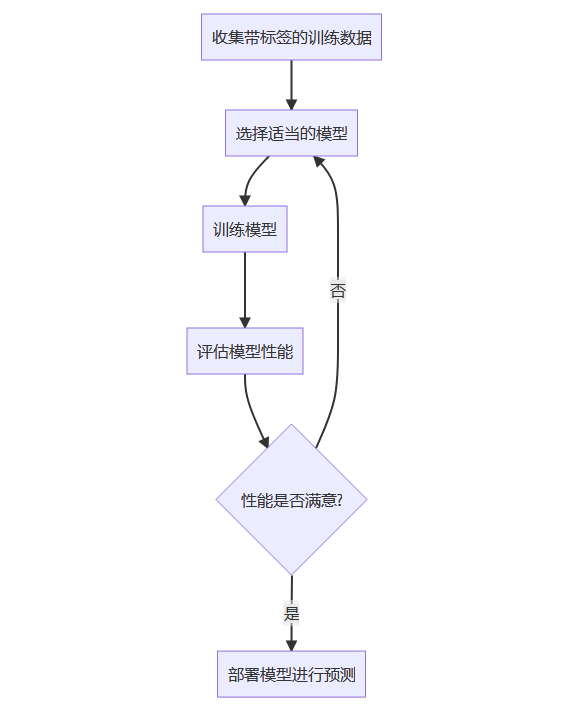
机器学习大致可分为三类:监督学习、非监督学习、半监督学习,下面我们就来分别介绍。
机器学习是人工智能的核心领域之一,而根据学习过程中使用的标签数据的不同,机器学习主要分为三大类:监督学习(Supervised Learning)、半监督学习(Semi-supervised Learning)和无监督学习(Unsupervised Learning)。
监督学习
用数据挖掘领域著名学者韩家炜
教授的话来说,所有的监督学习(Supervised Learning),基本上都是分类(Classification)的代名词。它从有标签的训练数据中学习模型,然后对某个给定的新数据利用模型预测它的标签。
这里的标签其实就是某个事物的分类。在某种程度上,你可以把它理解为作业的“标准答案”,而对于每次监督学习的输出,可理解为自己作答的答案。如果我们给出的答案和标准答案不一致,老师或家长就会监督我们来纠错,这样一来二去,我们对题目的理解就会更加深刻,在做新题时,正确率也会越来越高。
比如,小时候父母告诉我们某个动物是猫、狗或猪,然后在我们的大脑里就会形成或猫或狗或猪的印象(相当于模型构建),当面前来了一只“新”小狗时,如果你能叫出“这是一只小狗”,那么恭喜你,标签分类成功!
但如果你回答说“这是一头小猪”,这时你的父母就会纠正你的偏差:“乖,不对,这是一只小狗。”这样一来二去地进行训练,不断更新你大脑的认知体系,当下次再遇到这类新的猫、狗、猪时,你就会在很大概率上做出正确的“预测”分类。
监督学习的示意图如图 1 所示。
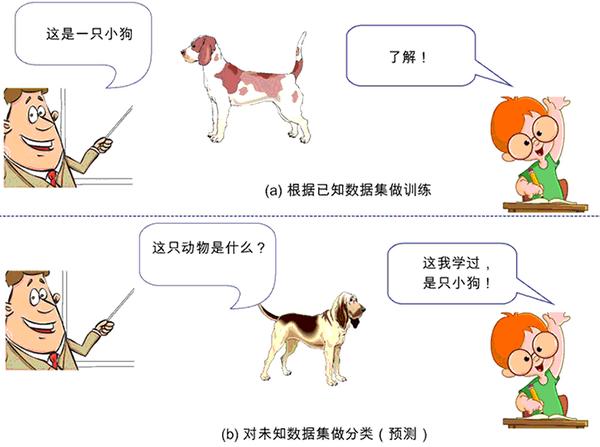
图 1:监督学习的示意图
事实上,整个机器学习的过程就是在干一件事,即通过训练学习得到某个模型,然后期望这个模型也能很好地契合(fitting)“新样本”。这种让模型契合新样本的能力,也称为“泛化能力”,它是机器学习算法中非常重要的性质。
优缺点
监督学习的优点在于:
- 可以通过大量已有标记数据训练模型,使得模型的预测结果更加准确。
- 可以对数据进行分类和预测。
但是,监督学习也有一些缺点:
- 需要大量的已标记数据,而且需要人工进行标记。
- 模型只能预测已知类别,对于未知类别的数据无法进行有效预测。
典型算法:
线性回归(Linear Regression)
逻辑回归(Logistic Regression)
决策树(Decision Tree)
支持向量机(Support Vector Machine, SVM)
神经网络(Neural Networks)
随机森林(Random Forest)
梯度提升树(Gradient Boosting Decision Tree, GBDT)
代码示例:使用Scikit-learn实现监督学习
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征
y = iris.target # 标签
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建随机森林分类器
clf = RandomForestClassifier(n_estimators=100, random_state=42)
# 训练模型
clf.fit(X_train, y_train)
# 预测
y_pred = clf.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy:.2f}")非监督学习
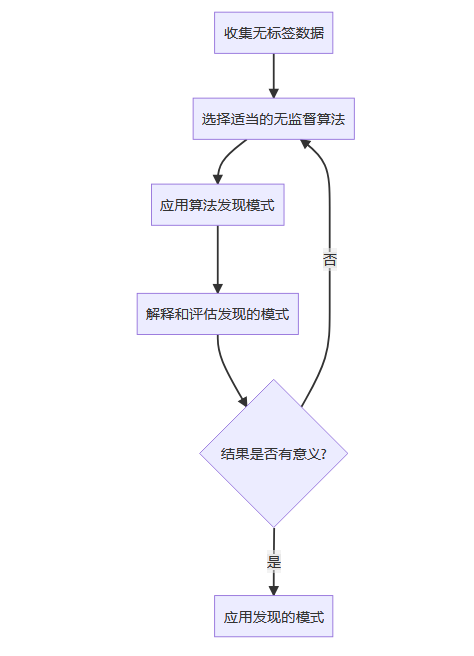
与监督学习相反,非监督学习(Unsupervised Learning)所处的学习环境中都是没有标签的数据。韩家炜教授又指出:非监督学习,本质上就是“聚类”(Cluster)的近义词。聚类的思想起源非常早,在中国最早可追溯到《周易·系辞上》中的“方以类聚,物以群分,吉凶生矣。”
但真正意义上的聚类算法
,却是 20 世纪 50 年代前后才被提出的。为何会如此滞后呢?原因在于,聚类算法的成功与否高度依赖于数据。数据量小了,聚类意义不大;数据量大了,人脑就不灵光了,只能交由计算机来解决问题,而计算机在 1946 年才出现。
如果说分类是指根据数据的特征或属性,将新对象划分到已有的类别当中,那么聚类一开始并不知道数据会分为几类,而是通过分析将数据聚成若干个群。简单来说,给定数据后,聚类能从数据中学习得到什么,就看数据本身具备什么特性了。
基于此,北京航空航天大学的于剑教授对聚类做出了 12 字的精彩总结:“归哪类,像哪类。像哪类,归哪类。”但这里的“类”也好,“群”也罢,事先我们是不知情的。一旦归纳出一系列“类”或“群”的特征,再来一个新数据时,我们就可以根据它距离哪个“类”或“群”较近,预测它属于哪个“类”或“群”,从而完成新数据的“分类”或“分群”功能。这就是非监督学习。
非监督学习示意图如图 2 所示。
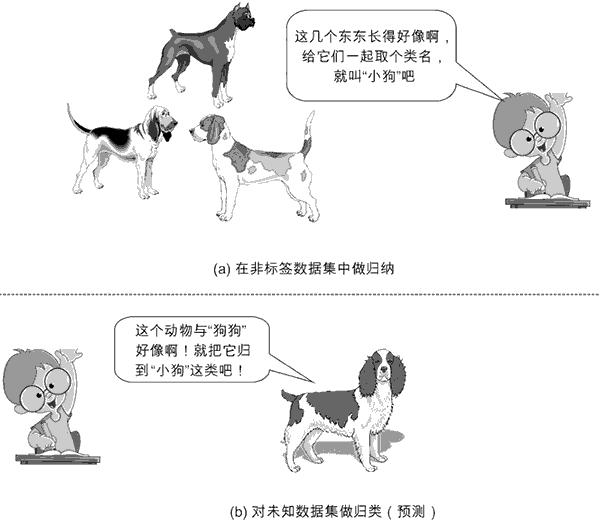
图 2:非监督学习示意图
优缺点
无监督学习的优点在于:
- 无需标记大量数据,降低了数据标记的成本。
- 可以自动发现数据的结构和模式,可以帮助解决一些特定问题,如异常检测、聚类分析等。
但是,无监督学习也有一些缺点:
- 无法利用标记数据进行训练,因此预测结果可能不够准确。
- 很难对生成的结果进行验证和解释,需要人工进行进一步分析。
典型算法:
K均值聚类(K-means Clustering)
层次聚类(Hierarchical Clustering)
主成分分析(Principal Component Analysis, PCA)
自编码器(Autoencoder)
高斯混合模型(Gaussian Mixture Model, GMM)
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)
代码示例:使用K-means进行聚类
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 生成模拟数据
X, y = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# 创建K-means模型
kmeans = KMeans(n_clusters=4, random_state=0)
# 训练模型
kmeans.fit(X)
# 预测聚类标签
labels = kmeans.predict(X)
# 可视化结果
plt.scatter(X[:, 0], X[:, 1], c=labels, s=50, cmap='viridis')
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.5)
plt.title("K-means聚类结果")
plt.show()半监督学习
半监督学习(Semi-supervised Learning)既用到了标签数据,又用到了非标签数据。
有一句骂人的话,说某个人“有妈生,没妈教”,抛开这句话中的骂人含义,其实它说的是“非监督学习”。但我们绝大多数人,不仅“有妈生,有妈教”,还有小学教、中学教、大学教,“有人教”的意思是,有人告诉我们事物的对与错(即对事物打标签),然后我们就可据此改善自己的性情,慢慢把自己调教得更有教养,这自然就属于“监督学习”。
但总有那么一天,我们会长大。而长大的标志之一,就是自立。何谓自立呢?就是远离父母、走出校园,没有人告诉你对与错,一切认知都要基于自己早期已获取的知识,并从社会中学习,扩大自己的认知体系,当遇到新事物时,我们能泰然自若地处理,而非六神无主。
从这个角度来看,现代人类成长学习的最佳方式当属“半监督学习”!它既不是纯粹的“监督学习”(如果是这样,我们的创造力和认知体系可能会被扼杀,我们也永远不可能超越父辈和师辈),也不属于完全的“非监督学习”(如果是这样,我们会如无根之浮萍,花很多时间重造轮子)。
那么到底什么是“半监督学习”呢?下面我们给出它的形式化定义:
给定一个来自某个未知分布的有标记示例集 {(x1, y1), (x2, y2), ..., (xk, yk )},其中 xi 是输入数据,yi 是标签。对于一个未标记示例集 U={xk+1, xk+2, ..., xk+u },这里 u 为未标记样本数。我们期望通过学习得到某个函数:fY→X,通过它准确地对未标记的数据 lix+,预测其标签 iy。这里 xi∈X,均为 d 维向量,yi∈Y,为示例 xi 的标签。
半监督学习的示意图如图 3 所示。
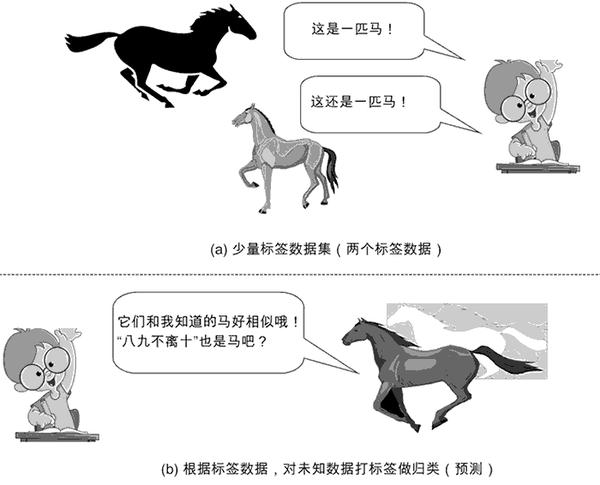
图 3:半监督学习示意图
形式化的定义比较抽象,下面我们列举一个现实生活中的例子来辅助说明这个概念。假设我们已经学到:
a) 马晓云同学(数据1)是一个牛人(标签为牛人);
b) 马晓腾同学(数据2)是一个牛人(标签为牛人)。
假设我们并不知道李晓宏同学(数据3)是谁,也不知道他是不是牛人,但考虑他经常和二马同学共同出入高规格大会,都经常会被上层人士接见(也就是说他们虽独立,但同分布),所以我们很容易根据“物以类聚,人以群分”的思想,给李晓宏同学打上“牛人”标签。
这样一来,我们的已知领域(标签数据)就扩大了(由两个扩大到三个),这也就完成了半监督学习的过程。事实上,半监督学习就是以“已知之认知(标签化的分类信息)”扩大“未知之领域(通过聚类思想将未知事物归类为已知事物领域)”。但这里隐含了一个基本假设—聚类假设(Cluster Assumption),其核心要义就是,相似的样本拥有相似的输出。
常见的半监督学习算法有生成式方法、半监督支持向量机
(Semi-supervised Support Vector Machine,简称 S3VM,是 SVM 在半监督学习上的推广应用)、图半监督学习、半监督聚类等。
事实上,我们对半监督学习的现实需求是非常强烈的。原因很简单,因为人们能收集到的标签数据非常有限,而手动标记数据需要耗费大量的人力、物力,但非标签数据却大量存在且触手可得,这个现象在互联网数据中更为常见,因此半监督学习显得尤为重要。
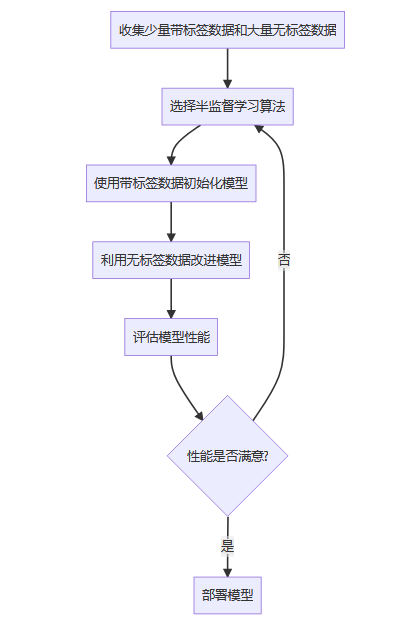
优缺点
半监督学习的优点在于:
- 可以减少标记数据的数量,降低数据标记的成本。
- 可以利用未标记数据来提高模型的预测能力,使预测结果更加准确。
但是,半监督学习也有一些缺点:
- 需要大量未标记数据,模型可能会过度拟合未标记数据,导致预测结果不准确。
- 无法处理未知类别的数据。
典型算法:
自训练(Self-training)
协同训练(Co-training)
标签传播(Label Propagation)
基于图的半监督学习(Graph-based Semi-supervised Learning)
半监督支持向量机(Semi-supervised SVM, S3VM)
代码示例:标签传播算法
import numpy as np
from sklearn import datasets
from sklearn.semi_supervised import LabelPropagation
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 随机选择10%的样本作为带标签数据
rng = np.random.RandomState(42)
random_unlabeled_points = rng.rand(len(y)) < 0.9
y_train = np.copy(y)
y_train[random_unlabeled_points] = -1 # -1表示无标签
# 创建标签传播模型
label_prop_model = LabelPropagation(kernel='knn', n_neighbors=10)
# 训练模型
label_prop_model.fit(X, y_train)
# 预测所有样本
y_pred = label_prop_model.predict(X)
# 计算准确率
accuracy = accuracy_score(y, y_pred)
print(f"模型准确率: {accuracy:.2f}")
总结
- 选择监督学习:当你有大量带标签数据且目标是预测明确的输出时
- 选择无监督学习:当你没有标签数据且目标是探索数据内在结构时
- 选择半监督学习:当你有少量带标签数据和大量无标签数据时
附加补充
除了3种机器学习方式,还有强化学习、自监督学习(Self-supervised Learning)等


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









