







随着互联网技术的广泛应用,5G以及物联网和云计算的迅猛发展,带动了全球数据爆发式增长,随之而来的是不断增长的数据规模和数据的动态快速产生,这对大数据计算引擎带来了极大的挑战,离线批处理、实时计算和高吞吐量催生了新技术的发展和旧技术的革新,计算引擎出现了百花齐放的景象。计算引擎大致分两类,离线计算和实时计算,下面为大家介绍几个主流的大数据计算引擎。
一、离线计算引擎
1. MapReduce
MapReduce产生的灵感来源于2004年Google发表的《MapReduce》论文中的大数据计算模型,用于大规模数据集(TB甚至PB级)的并行计算,利用分治策略,将计算过程分两个阶段,Map阶段和Reduce阶段,可谓是第一代大数据分布式计算引擎,为后来各类优秀的大数据计算引擎的出现提供了基础和可行性。
(1)MapReduce的架构
MapReduce 1.x架构如下:
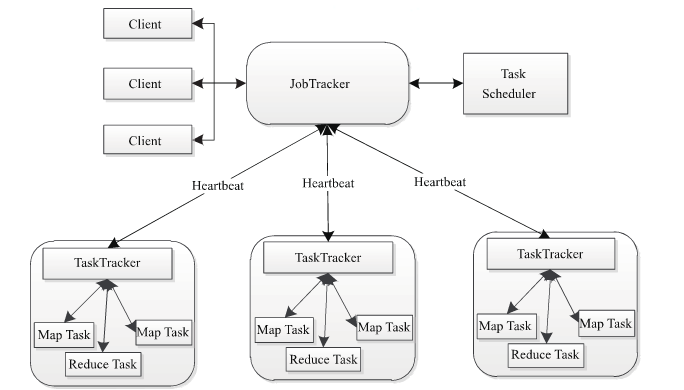
-
客户端向JobTracker提交任务
-
JobTraker将任务拆解为多个子任务,分配给TaskTracker执行
-
TaskTracker定时与JobTracker保持心跳,汇报任务执行情况
存在的问题:
-
单点故障:一旦JobTracker出现故障,会导致任务无法提交和正常执行
-
JobTracker负载高:所有的任务的提交和分配以及资源管理都是由JobTracker控制,压力过于集中
-
场景有限制:只能运行MapReduce作业,可兼容性差
为了解决MR v1的问题,MapReduce v2引入了资源管理器YARN (Yet Another Resource Negotiator),即新一代的MapReduce 2.0。
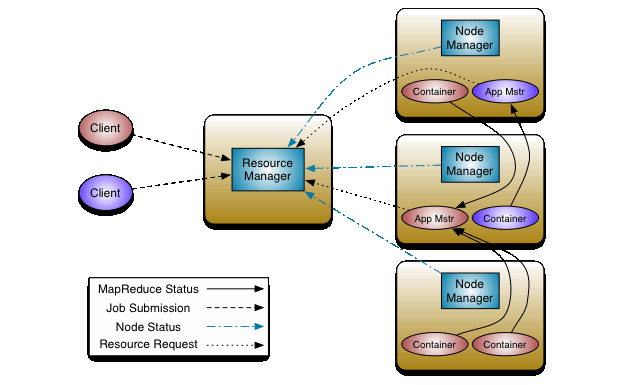
认识一下YARN中的重要角色及功能:
-
ResourceManager:资源管理节点(RM),对应MR v1的JobTracker
-
负责处理来自客户端的提交的Job
-
启动Application Master管理任务
-
监控Application Master状态
-
为NodeManager分配资源(CPU、内存、磁盘、网络)
-
-
NodeManager:工作节点(NM),对应MR v1的TaskTracker
-
管理节点container任务资源和运行情况
-
与ResourceManager保持通信,汇报自身的状态
-
-
Application Master:任务管理服务(AM),其实就是ResourceManager的小弟
-
负责检查集群资源,申请mr程序所需资源
-
分配任务到相应的container容器执行
-
监控任务执行状态并向ResourceManager汇报任务执行情况
-
-
Container:YARN资源抽象,封装了节点上的资源,如内存、CPU、磁盘等
YARN的优势:
-
ResourceManager支持HA,解决了JobTracker单点故障的问题,提高集群可用性
-
实现资源管理和job管理分离,解决了JobTracker负载高的难题
-
提供Application Master负责监控所有的任务,解决了JobTracker集中管理监控的压力
-
高扩展性,不仅可以跑mr任务,还支持spark作业以及其他计算引擎任务
-
提高了资源的利用率
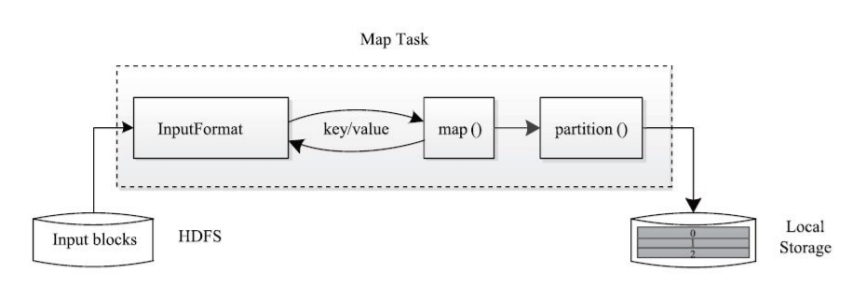
(2)MapReduce核心计算阶段
-
Mapper阶段:负责数据 的载入、解析、转换和过滤,map任务的输出被称为中间键和中间值
-
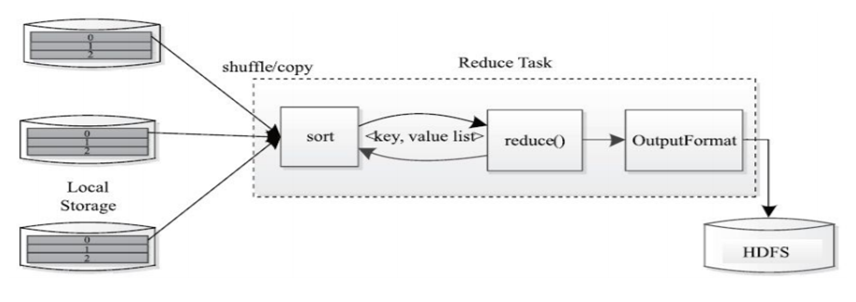
Reducer阶段:负责处理map任务输出结果,对map任务处理完的结果集进行排序、局部聚合计算再汇总结果
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









