



这个博主讲得很不错!:https://www.cnblogs.com/kongen/p/18088002
视频:Transformer的PyTorch实现_哔哩哔哩_bilibili
如果是刚接触Transformer,强烈建议去把上边两个看了!!!在此之前,希望你能仔细读2遍原文!!!
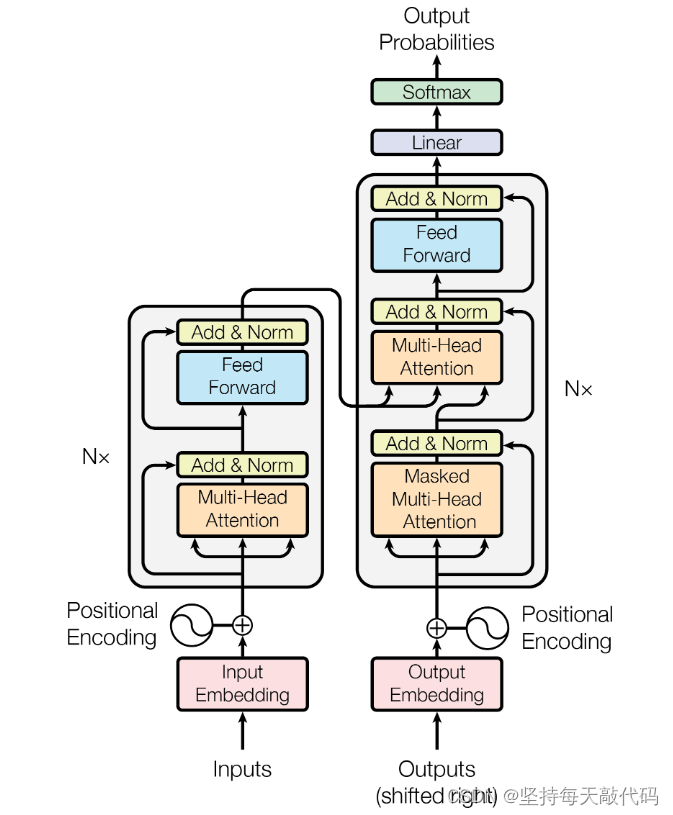
这里其实想讲一下为什么通过自注意力机制,就能够预测出来目标值了。一开始我也比较懵懵懂懂,毕竟刚接触, 只知道我的输入a = "我 有 一只 猫" 经过encoder 和 decoder 之后,就得到了b = "I have a cat ", 后来想了想,我觉得大致是这样的,Encoder里边的Multi-Head Attention,得到了编码器输入的注意力权重,也就是输入序列a中每个单词对其他单词的注意力权重;同理Decoder的第一个Multi-Head Attention 也是得到目标序列中,各个单词之间的注意力权重。Decoder中的第二个Multi-Head Attention是将Encoder 和 Decoder 两者结合起来计算注意力权重,这样就能得到源句子中单词,对应目标句子中的单词的权重,最后转换为概率,概率最大的目标单词就是我们的答案。如果扩展一下,分别构建源语言词汇表(src_vocab)和目标语言词汇表(tgt_vocab),我们经过多轮训练之后就能得到比较准确的映射,知道最大概率翻译成哪个target词汇。我建议,先大致看一下理论,然后在代码实现里边找细节!
好,正式开始我们的主题:transformer的pytorch代码实现,首先我会分每个部分分别讲解代码,每个部分都是我觉得比较关键的点,所以顾及不了所有点,如果有不理解的,可以在评论区向我提问,很乐意讨论,完整代码放到最后。另外,我建议你在实现代码的时候,可以单独创建一个test.py文件用来测试,将每一个部分的数据打印出来看看是什么样子,尤其是你存有疑惑的数据!
导库
import math
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data数据预处理以及参数设置
为了方便理解,模型没有使用大数据集,用了两对“德译英”的例子,下面是代码中的操作讲解:
- 分别构建源语言(source)和目标语言(target)的词汇表(词汇表就是字典,形式:“word”:number),这里的词汇表是手动写的,正常大数据集需要代码。
- src_len就是源句子的长度是5,tgt_len就是目标句子的长度是6。
- 'P' 就是填充项,我们要统一句子长度,但并不是每一个句子都有那么长,所以不够的用'P'填充。
- make_data()的作用是将原来的单词转化为对应在词汇表中的数字,并生成enc_inputs,dec_inputs,dec_outputs这几个数据,务必要记住他们的形状。
- 自定义数据集MyDataSet类,方便管理数据集;创建DataLoader,用来生成mini-batch。
# S: Symbol that shows starting of decoding input
# E: Symbol that shows starting of decoding output
# P: Symbol that will fill in blank sequence if current batch data size is short than time steps
sentences = [
#enc_input dec_input dec_output
['ich mochte ein bier P','S i want a beer .','i want a beer . E'],
['ich mochte ein cola P','S i want a coke .','i want a coke . E']
]
#Padding Should be Zero
src_vocab = {'P' : 0,'ich' : 1,'mochte':2,'ein':3,'bier':4,'cola':5}
src_vocab_size = len(src_vocab)
tgt_vocab = {'P' : 0,'i' : 1,'want':2,'a':3,'beer':4,'coke':5,'S':6,'E':7,'.':8}
tgt_vocab_size = len(tgt_vocab)
idx2word = {i:w for i,w in enumerate(tgt_vocab)}
src_len = 5#enc_input max sequence length
tgt_len = 6#dec_input(=dec_output) max sequence length
def make_data(sentences):
enc_inputs,dec_inputs,dec_outputs = [],[],[]
for i in range(len(sentences)):
enc_input = [[src_vocab[n] for n in sentences[i][0].split()]] # [[1, 2, 3, 4, 0], [1, 2, 3, 5, 0]]
dec_input = [[tgt_vocab[n] for n in sentences[i][1].split()]] # [[6, 1, 2, 3, 4, 8], [6, 1, 2, 3, 5, 8]]
dec_output = [[tgt_vocab[n] for n in sentences[i][2].split()]] ## [[1, 2, 3, 4, 8, 7], [1, 2, 3, 5, 8, 7]]
enc_inputs.extend(enc_input)
dec_inputs.extend(dec_input)
dec_outputs.extend(dec_output)
return torch.LongTensor(enc_inputs),torch.LongTensor(dec_inputs),torch.LongTensor(dec_outputs)
enc_inputs, dec_inputs, dec_outputs = make_data(sentences)
class MyDataSet(Data.Dataset):
def __init__(self,enc_inputs,dec_inputs,dec_outputs):
super(MyDataSet, self).__init__()
self.enc_inputs = enc_inputs
self.dec_inputs = dec_inputs
self.dec_outputs = dec_outputs
def __len__(self):
return self.enc_inputs.shape[0]
def __getitem__(self, idx):
return self.enc_inputs[idx],self.dec_inputs[idx],self.dec_outputs[idx]
mydataset = MyDataSet(enc_inputs,dec_inputs,dec_outputs)
loader = Data.DataLoader(mydataset,2,shuffle = True)
模型参数
下面变量的含义依次是:
- d_model:词嵌入的维度(= 位置嵌入维度)
- d_ff:Feed Forward中两层linear中间的过渡维度(512 -> 2048 -> 512)
- d_k、d_v:分别是K 、V的维度,其中Q和K相等的就省略了
- n_layers:EncoderLayer的数量,也就是blocks的数量
- n_heads:Multi-Head Attention 的头数
#Transformer Parameters
d_model = 512 # Embedding Size (= Positional Size)
d_ff =2048 # Feed Forward(512 -> 2048 ->512)
d_k = d_v = 64 # (d_k=d_q),dimension of qkv
n_layers = 6 # number of encoder-layer(=n blocks)
n_heads = 8 # number of heads in Multi-Head AttentionPositional Encoding
位置编码模块的过程是这样的,在他之前对输入序列已经进行了词嵌入,所以该模块输入的是word_embedding,形状为:[batch_size, src_len, d_model],而位置编码是写死的,在模块初始化的时候生成,将pos_embedding + word_embedding,然后输出,输出的形状:[batch_size,src_len, d_model ],得到了经过word_embedding 和 pos_embedding 的输入表示。
class PositionalEncoding(nn.Module):
def __init__(self,d_model ,dropout = 0.1,max_len = 5000):
self.dropout = nn.Dropout(p = dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0,max_len, dtype = torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float()*(-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0,1)
self.register_buffer('pe',pe)
def forward(self,x):
'''
:param x: [seq_len, batch_size, d_model]
:return:
'''
#pe[:x.size(0),:] -- [seq_len, 1, d_model]
x = x + self.pe[:x.size(0),:]
return self.dropout(x)计算公式如下:
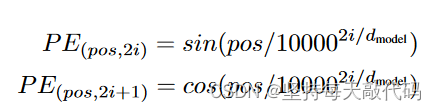
- div_term表示括号里的分母项,这里用exp对公式做了变形,(建议手推一下)求得了div_term。
- i = 0,1,2,...,d_model/2, 。pe[maxlen, d_model]的第2个dim中,每个奇数维度的值对应一个cos,每个偶数维度的值对应一个sin,这样正好d_model个维度。实际操作中就是在0~d_model之间, 取步长为2,取得[0,2,4,...... ,d_model-2],总共d_model/2个,分别做sin、cos,这样就是d_model个,分别放到pe的d_model个维度上。
这里想说一下,具体如何将词嵌入之后的输入x 加上位置编码pe的。
首先说一下pe,即position embedding。1)pe创建的时候, 形状: [maxlen, d_model], 表示的是对第0 - maxlen 位置的单词进行编码,每个单词维度是d_model,当然实际可能每个句子不到maxlen, 后边会截取不用担心。 2)我们对pe进行编码之后,在dim=1增加了一个维度,形状变成了: [max_len, 1, d_model], 。 3)pe[:x.size(0),:] 其实就是取了跟句子长度seq_len一样大小,pe的形状变为:[seqlen, 1, d_model] 。这里的输入x的形状为:[seq_len, batch_size, d_model] (传入参数的时候改变了形状,将dim0和dim1做了交换),如下图:
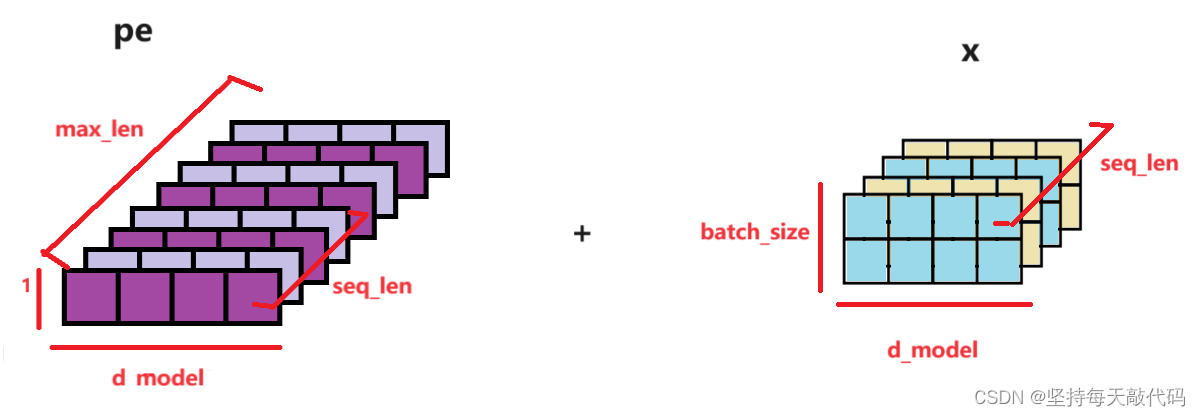
x + pe[:x.size(0),:] pe的第2维度的1会广播到batch_size大小。batch_size 就是几个句子,相当于对每个句子中的每个位置对应的单词都加上了位置编码。
[seq_len, batch_size, d_model] + [seqlen, 1, d_model] -》最后形状为:[seq_len, batch_size, d_model]。最后返回x,后边的代码会对x进行x.transpose(0,1),得到经过word_emb、pos_emb之后的编码输入:[batch_size, seq_len, d_model]
Pad Mask
这里的作用就是Mask Pad,即遮掩掉填充项,让其他单词对于填充项'P'的注意力权重几乎为0。
def get_attn_pad_mask(seq_q, seq_k): # Mask Pad
'''
:param seq_q: [batch_size, seq_len]
:param seq_k: [batch_size, seq_len]
seq_len could be src_len or it could be tgt_len
seq_len
















 1439
1439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









