






 本文介绍了如何在PyTorch中使用自定义的`DiabetesDataset`继承`Dataset`类处理数据并进行预处理,以及如何利用`DataLoader`生成并利用mini-batch进行模型训练,涉及epoch、batch-size和iteration的概念。
本文介绍了如何在PyTorch中使用自定义的`DiabetesDataset`继承`Dataset`类处理数据并进行预处理,以及如何利用`DataLoader`生成并利用mini-batch进行模型训练,涉及epoch、batch-size和iteration的概念。
原理:学习内容:B站刘二大人pytorch深度学习实践
Dataset 和DataLoader
这讲主要内容
- 如何继承Dataset来定义自己的数据集类,该类再对数据做预处理。
- 如何使用DataLoader类,来生成mini-batch数据进行训练
之前讨论过随机梯度下降的时候,有的用一整个batch更新 or 有的用一个一个样本更新,为了平衡两者,现在每次用的是mini-batch来更新。下面先了解一下一些概念:
基本概念
什么叫epoch?
所有的训练样本进行一个完整的forward和backward过程就是一个epoch过程。
Batch-size?
批次大小:进行一次forward和backward所用到的训练样本的数量。
Iteration?
迭代:多少次迭代意味着多少个batch ,每次迭代就是用一个batch的数据集训练,然后更新。
Dataloader
dataloader主要作用是把给定的数据集,生成一个一个mini-batch。
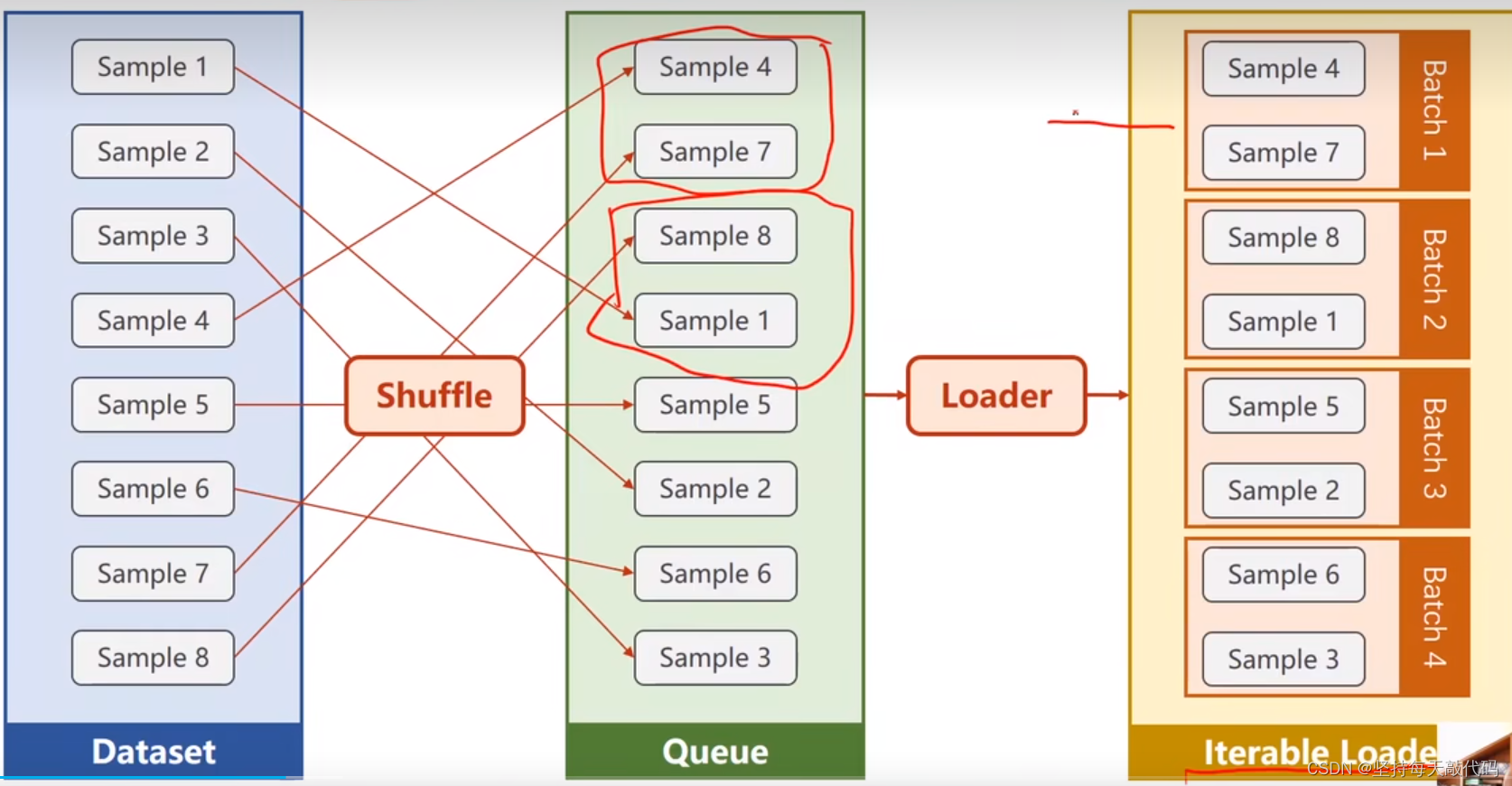
原理: 将数据集送入Dataloader中,会自动(shuffle = True) 随机打乱样本,然后生成Iterable Loader对象,其中包含多个Batch。
准备数据集
import torch
import numpy as np
from torch.utils.data import Dataset,DataLoader
#Dataset是一个抽象类,自定义的数据集类需要继承该类
class DiabetesDataset(Dataset):
def __init__(self,filepath):
xy = np.loadtxt(filepath, delimiter = ',', dtype = np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
#魔法函数,通过index拿到每个样本的数据
def __getitem__(self, index):
return self.x_data[index],self.y_data[index]
#魔法函数,得到数据的长度
def __len__(self):
return self.len
dataset = DiabetesDataset('data/diabetes.csv.gz')
train_loader = DataLoader(dataset = dataset,
batch_size = 32,
shuffle = True,
num_workers = 2)设计模型
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = nn.Linear(8,6)
self.linear2 = nn.Linear(6,4)
self.linear3 = nn.Linear(4,1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self,x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()构建损失和优化器
criterion = torch.nn.BCELoss(size_average = False)
optimizer = torch.optim.SGD(model.parameters(),lr = 0.01)循环训练
if __name__ == '__main__':
for epoch in range(1):
for i,data in enumerate(train_loader,0):
#1.Prepare data
inputs,labels = data
#2.Forward
y_pred = model(inputs)
loss = criterion(y_pred,labels)
print('epoch=',epoch,'batch=',i,'loss = ',loss.item())
#3.Backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
#enumerate函数是Python内置的一个函数,用于将一个可迭代对象转换为一个索引-元素对的枚举对象,从而方便地同时获得索引和元素,并在循环迭代中使用。train_loader中每个mini-batch如下:
[tensor([[-0.7647, 0.0050, 0.0492, -0.5354, 0.0000, -0.1148, -0.7523, 0.0000],
[-0.7647, -0.2563, 0.0000, 0.0000, 0.0000, 0.0000, -0.9795, -0.9667],
[-0.8824, -0.1558, 0.0492, -0.5354, -0.7281, 0.0999, -0.6644, -0.7667],
[-0.0588, 0.0854, 0.1475, 0.0000, 0.0000, -0.0909, -0.2511, -0.6000],
[-0.7647, -0.0754, 0.2459, -0.5960, 0.0000, -0.2787, 0.3834, -0.7667],
[-0.4118, 0.0000, 0.3115, -0.3535, 0.0000, 0.2221, -0.7711, -0.4667],
[-0.8824, 0.3568, -0.1148, 0.0000, 0.0000, -0.2042, -0.4799, 0.3667],
[-0.0588, 0.9497, 0.3115, 0.0000, 0.0000, -0.2221, -0.5961, 0.5333],
[ 0.0000, 0.5176, 0.4754, -0.0707, 0.0000, 0.2548, -0.7498, 0.0000],
[ 0.0000, 0.2764, 0.3115, -0.2525, -0.5035, 0.0820, -0.3800, -0.9333],
[-0.7647, 0.4271, 0.3443, -0.6364, -0.8487, -0.2638, -0.4167, 0.0000],
[-0.7647, 0.5779, 0.2131, -0.2929, 0.0402, 0.1744, -0.9522, -0.7000],
[-0.7647, 0.0854, 0.0492, 0.0000, 0.0000, -0.0820, -0.9317, 0.0000],
[-0.4118, -0.1357, 0.1148, -0.4343, -0.8322, -0.0999, -0.7558, -0.9000],
[-0.8824, 0.4372, 0.3770, -0.5354, -0.2671, 0.2638, -0.1477, -0.9667],
[-0.5294, 0.2563, 0.3115, 0.0000, 0.0000, -0.0373, -0.6089, -0.8000],
[-0.8824, 0.2864, 0.3443, -0.6566, -0.5674, -0.1803, -0.9684, -0.9667],
[-0.7647, 0.3970, 0.2295, 0.0000, 0.0000, -0.2370, -0.9240, -0.7333],
[-0.8824, -0.1156, 0.0164, -0.5152, -0.8960, -0.1088, -0.7062, -0.9333],
[-0.6471, 0.7085, 0.0492, -0.2525, -0.4681, 0.0283, -0.7626, -0.7000],
[-0.7647, 0.0854, -0.1475, -0.4747, -0.8511, -0.0313, -0.7950, -0.9667],
[ 0.5294, 0.5879, 0.8689, 0.0000, 0.0000, 0.2608, -0.8471, -0.2333],
[-0.2941, 0.2563, 0.2459, 0.0000, 0.0000, 0.0075, -0.9633, 0.1000]]),
tensor([[1.],
[1.],
[1.],
[0.],
[1.],
[0.],
[1.],
[1.],
[0.],
[1.],
[1.],
[1.],
[1.],
[1.],
[1.],
[0.],
[1.],
[1.],
[1.],
[0.],
[1.],
[0.],
[0.]])]完整代码
import torch
import numpy as np
from torch.utils.data import Dataset,DataLoader
#1.准备数据集
class DiabetesDataset(Dataset):
def __init__(self,filepath):
xy = np.loadtxt(filepath, delimiter = ',', dtype = np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
#魔法函数,通过index拿到里边的数据
def __getitem__(self, index):
return self.x_data[index],self.y_data[index]
#魔法函数,得到数据的长度
def __len__(self):
return self.len
dataset = DiabetesDataset('data/diabetes.csv.gz')
train_loader = DataLoader(dataset = dataset,
batch_size = 32,
shuffle = True,
num_workers = 2)
#2.设计模型
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = nn.Linear(8,6)
self.linear2 = nn.Linear(6,4)
self.linear3 = nn.Linear(4,1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self,x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
#构建损失和优化器
criterion = torch.nn.BCELoss(size_average = False)
optimizer = torch.optim.SGD(model.parameters(),lr = 0.01)
#循环训练
if __name__ == '__main__':
for epoch in range(1):
for i,data in enumerate(train_loader,0):
#1.Prepare data
inputs,labels = data
#2.Forward
y_pred = model(inputs)
loss = criterion(y_pred,labels)
print('epoch=',epoch,'batch=',i,'loss = ',loss.item())
#3.Backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
小结
本讲主要掌握如下内容:
- epoch、batch-size、iteration的概念
- 如何使用DataSet定义自己的数据集(包括对数据集的处理)
- 如何使用Dataloader生成mini-batch来进行训练

















 1091
1091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









