






学习内容:B站 刘二大人 《pytorch深度学习实践》课程系列
先讲理论和套路:
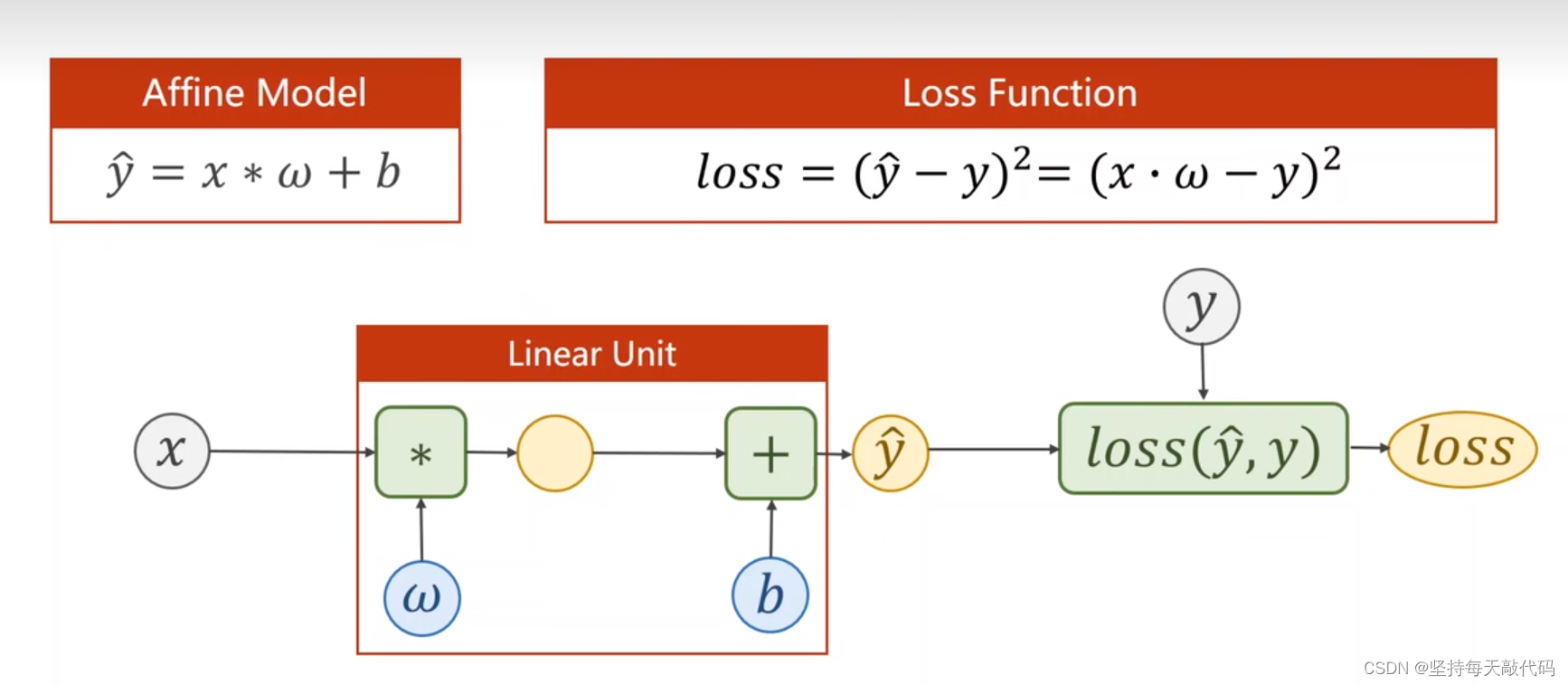
前向传播:
如上图,前向传播就是从输入x,经过model 的多个层(当然这里只有一个linear)计算得到y_pred,然后通过loss(y_pred,y)计算得到loss的过程。
反向传播:
如上图,反向传播就是从loss开始,通过链式求导法则求所有涉及w的参数梯度的过程,最后得到loss对w的梯度用于更新。
模型训练全过程
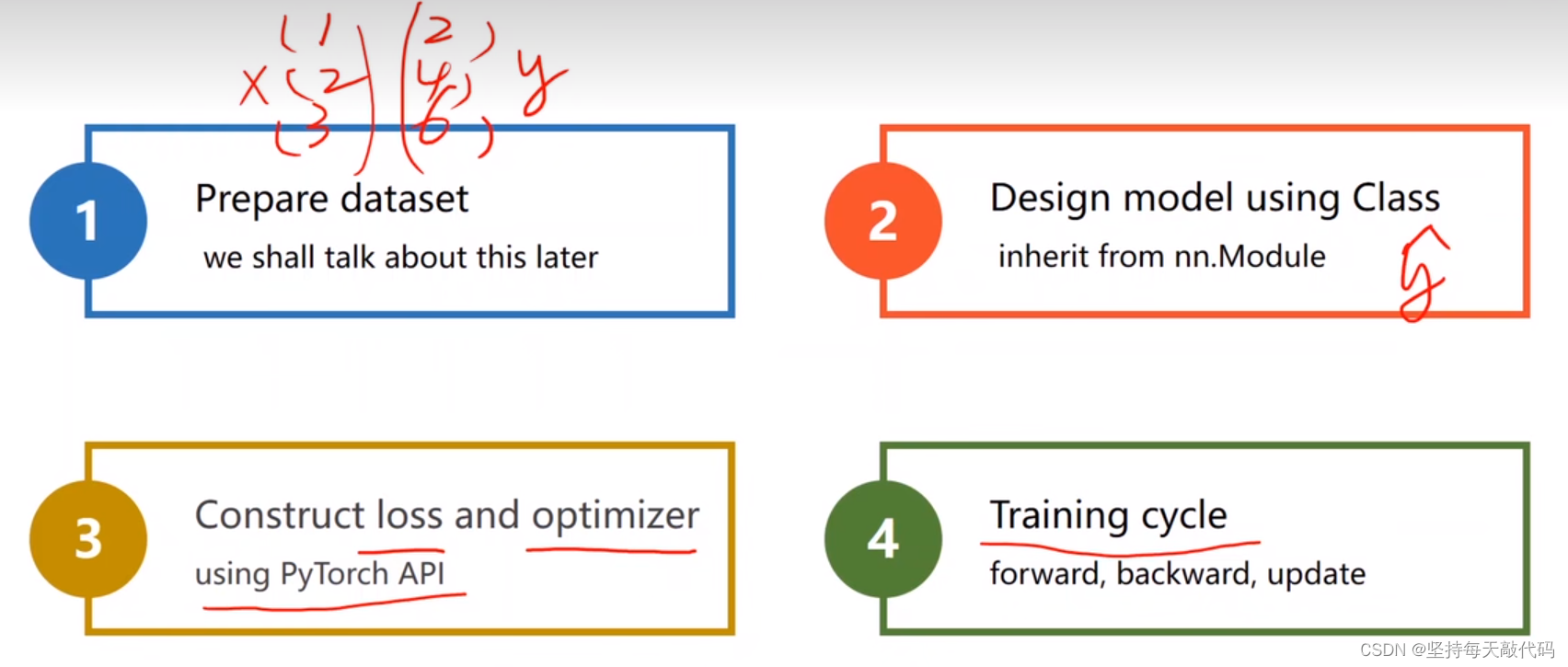
- Prepare dataset:主要确定输入数据和输出数据的形状,该如何定义张量。
- Design model using Class:设计模型求y_pred,init定义层,forward构建计算图,最后求出pred。
- Construct loss and optimizer(using Pytorch API):使用pytorch封装好的api构建loss器和优化器
- Traing cycle:forward求损失 , backward求梯度, update更新权重。
1.数据准备
import torch
import torch.nn as nn
x_data = torch.Tensor([[1.0],[2.0],[3.0]])
y_data = torch.Tensor([[2.0],[4.0],[6.0]])
#数据集x、y都必须是3x1的矩阵,定义张量的时候注意!!!2.构建模型
class LinearModel(nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.linear = nn.Linear(1,1)
def forward(self,x):
y_pred = self.linear(x)
return y_pred
#构建模型的过程:
#1) 在init中定义计算图中用到的层
#2) 在forward方法中去调用定义好的层,构建计算图,计算并返回y_pred构建模型的技巧
- 脑海中有整个计算图的概况
- 在init中定义计算图中用到的层
- 在forward方法中去调用定义好的层,计算并返回y_pred
torch.nn.Linear
torch.nn.Linear(输入样本维度,输出样本维度,bias=True)
包含了weight和bias两个张量参数,我们只需要确定输入和输出样本的维度,帮我们自动完成线性操作。
3.构建损失函数和优化器
#实例化一个自定义模型
model = LinearModel()
#定义损失函数,用来求均方误差,但是这里不求平均
criterion = torch.nn.MSELoss(size_average = False)
#定义优化器,确定对哪些参数进行优化,也知道lr,后期就可以自动更新
optimizer = torch.optim.SGD(model.parameters(),lr = 0.01)
4.训练循环
#epoch控制训练的轮数
for epoch in range(1):
#Forward
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
print(epoch,loss)
#Backward
optimizer.zero_grad()
loss.backward()#对loss计算过程中所有涉及的张量进行求梯度,并存放到张量本身
#Update
optimizer.step()#对优化器所包含的参数进行更新代码理解:
- mini-batch:这里x_data是一个3x1的矩阵张量,相当于3个样本,也就是一个mini-batch.传入linear,得到一个y_pred 也是3x1形状的张量。
- loss是一个标量,也就是将mini-batch对应的loss1、loss2、loss3求和取平均了。
- Forward的过程:根据计算图,先求y_pred,再求loss。
- backward之前需要将梯度清零。因为backward执行后就会求梯度,求出来的梯度会在加在原有的梯度上。optimizer提前指定了model的参数,所以optimizer.zero_grad()对多有参数的梯度全都清零。
- backward过程:对loss进行backward操作。对所有涉及模型参数都求梯度,并存放到张良本身:data 和 grad。
- 优化器对模型参数更新。
5.测试
#Output
print('w = ',model.linear.weight.item())
print('b = ',model.linear.bias.item())
#Test Model
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred=',y_test.data)完整代码
import torch
import torch.nn as nn
x_data = torch.Tensor([[1.0],[2.0],[3.0]])
y_data = torch.Tensor([[2.0],[4.0],[6.0]])
class LinearModel(nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.linear = nn.Linear(1,1)
def forward(self,x):
y_pred = self.linear(x)
return y_pred
model = LinearModel()
criterion = torch.nn.MSELoss(size_average = False)
optimizer = torch.optim.SGD(model.parameters(),lr = 0.01)#知道对哪些参数进行优化,也知道lr
for epoch in range(1):
#Forward
y_pred = model(x_data)
print(f"y_pred:{y_pred}")
loss = criterion(y_pred,y_data)
print(epoch,loss)
#Backward
optimizer.zero_grad()
loss.backward()#对loss计算过程中所有涉及的张量进行求梯度,并存放到张量w本身
#Update
optimizer.step()#对优化器所包含的参数进行更新
#Output
print('w = ',model.linear.weight.item())
print('b = ',model.linear.bias.item())
#Test Model
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred=',y_test.data)小结
本结主要介绍了pytorch实现线性模型,代码风格跟以前完全不一样了,很多东西封装好了,在设计的时候弹性很好。比如:1) 设计model的时候,在init中定义forward中需要用到的linear层,在forward中调用定义好的层进行前向传播,同时也在构建计算图,最后求出输出值y_pred.
2)循环训练的时候,前向传播包括两个部分,首先通过model求得y_pred ,然后通过y_pred和y—_data求loss。反向传播包括三部分,首先优化器对模型参数的梯度清零;然后这里对loss进行反馈传播(loss是标量)计算涉及的梯度;优化器对参数进行更新。
感觉就是优化器管理参数的值,反向传播求参数的梯度。而且一定记住是对loss进行的反馈传播,整个计算图的过程,是从输入x经过model 的多层得到y_pred,再进行Loss(y_pred,y_data)计算得到loss。然后在通过loss对沿途的参数求梯度。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









